
在过去20个月里,COVID-19大流行已报告造成490多万人死亡(https://coronavirus.jhu.edu),限制SARS-CoV-2病毒传播的措施影响了世界各地人民的生活。尽管建模有助于重建一些国家疫情的早期动态,但我们仍然缺乏关于疫情在全球范围内如何展开的连贯图景。写在自然戴维斯分校et al。1在美国和欧洲,使用一个全球模型来评估SARS-CoV-2的早期神秘传播——最初的监测工作没有发现该病毒的传播。
阅读论文:SARS-CoV-2的神秘传播和第一波COVID-19
回顾大流行最初几个月的时间顺序,令人担忧的是病毒在世界各地传播的速度有多快,导致人们的社会和经济生活大规模关闭。2020年1月10日,中国湖北省武汉市报告41例COVID-19病例。中国境外的首次感染报告是1月13日(泰国)和1月16日(日本)。武汉于1月23日实施封城,意大利(3月11日)、西班牙(3月14日)、奥地利(3月16日)和法国(3月17日)也相继实施封城。许多国家对迅速变化的形势措手不及,报告了大量死亡人数。下次我们怎样才能做得更好呢?要回答这个问题并改善我们应对未来大流行的准备工作,至关重要的是要更清楚地了解病毒的最初传播情况。这是困难的,因为当时检测病毒感染的能力有限,这意味着在许多地方,SARS-CoV-2的传播可能没有被发现。
戴维斯et al。使用了全球流行和流动性(GLEAM)模型,该模型既有随机(包含随机元素)成分,也有机制(包括与病毒感染和传播相关的生物和社会机制的定义原则)成分,以模拟病毒在全球范围内的传播2.该模型依靠各种类型的数据来捕捉流行病过程的多因素性质。这些信息包括以下数据:病毒传播的人群,如特定国家的人口统计数据;国际和本地范围内的人员流动(例如,航空运输网络和通勤流量);以及行为,比如记录不同年龄的个体如何相互交流的信息。该模型还捕捉了SARS-CoV-2传播的生物学方面、临床特征(如所分析的每个年龄组的致死率)以及采取封锁等非药物遏制措施的时间。
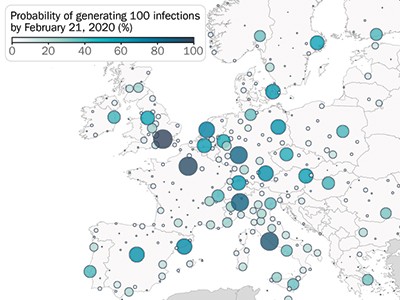
利用这个模型,作者们阐明了这种病毒是如何在世界各地传播的。例如,该模型证实,在一开始(2020年1月至3月),美国和欧洲的许多病毒传入都没有引起注意(图1)。在美国,加州是第一个受到本地传播影响的州(根据模型,1月26日那一周),尽管仅在一个月后(2月26日)才报告了当地传播的证据。在欧洲,模型显示,意大利、英国、德国和法国的本地传播于1月底开始,在当地病例报告之前也有很大的延迟。总的来说,戴维斯和同事们估计,到2020年3月8日,美国和欧洲每100例SARS-CoV-2感染者中只有1-3例被发现。

2020年初报告和估计的COVID-19病例数。戴维斯et al。1使用复杂的流行病学模型重建了COVID-19大流行开始时SARS-CoV-2病毒在30个欧洲国家和美国的传播情况。他们估计,在2020年1月17日至2月21日期间,监测工作仅发现了一小部分病例,其余估计病例来自隐蔽传播。
值得注意的是,在研究的所有30个欧洲国家和美国所有州,本地传播在2020年1月中旬至3月中旬之间约2个月的相对狭窄的时间窗口内开始。这些开始日期的差异——以及干预时间和力度的差异——导致了不同地区疾病传播模式的高度差异。截至2020年7月4日,所分析区域的感染发病率(感染病毒的人口占区域人口的比例)约为0.2%至15%。
该模型可以帮助评估当时实施的检测策略的表现,这些策略主要影响来自中国的乘客。尽管2020年1月进入美国和欧洲的COVID-19感染者中有很大一部分确实来自中国,但邻近的欧洲国家和美国各州很快成为所分析地区感染率的主要贡献者。
由于缺乏关于受传播影响的国际地点的可靠疫情信息,大多数国家的检测政策范围太窄,而且可能无效。戴维斯和他的同事们提出了一个与事实相反的设想:如果检测政策更广泛,能够检测出美国和欧洲所有输入性和本地感染的50%,那么在许多地方,本地传播的开始可能会推迟至少一个月。这将使各国政府有更多时间进行准备,例如通过提高卫生保健能力和购买防护设备。然而,考虑到这种反事实情景的乐观基本假设,仍然很难想象各国能够足够快地提高检测能力,以检测出50%的SARS-CoV-2初始感染。

针对旅行者进行COVID检测的机器学习算法
还有其他方法可以重建SARS-CoV-2的传播,例如,研究对病毒的RNA进行测序,以确定循环毒株的“家谱”3.,4.在这些方法中,病毒传播的重建历史是由分析时所有可用数据所告知并与之一致的。相比之下,戴维斯提出的模拟et al。初始化为与大流行开始时的数据相匹配,但不受2020年1月21日之后观察到的数据的限制。因此,作者探索了比系统发育研究更广泛的病毒传播可能的轨迹,其中一些轨迹可能与现实中发生的情况并不完全匹配。尽管模拟具有这一特点,但重建感染发生率与观察到的病例数之间存在相对较好的相关性。
与其他方法相比,Davis及其同事的方法的一个关键优势是,他们的模型提供了对流行病传播的机制理解。这就有可能对情景进行建模,记录在不同的政策选择下大流行可能如何展开,例如上文提到的反事实情景,其中包括从大流行开始就进行更密集的检测。模型能够捕捉和预测复杂的非线性动态,并评估不同政策选择的潜在影响,这在很大程度上解释了为什么这种模型越来越多地被用于支持决策,而这一趋势因大流行而得到放大。美国疾病控制和预防中心成立的疾病预测中心只是这一趋势的最新例子5.
应该考虑几种令人兴奋的方法来改进这些模型以供将来使用。将这些模型与流行病学和病毒测序数据校准的方法,可以提高它们在“即时铸造”和预测病毒传播方面的表现,以及实时评估政策的效果。有必要更详细地了解影响传播的因素(如流动性、混合模式、行为变化、气候和人群免疫力),以改进模式假设。模型的好坏取决于它们所依赖的数据。尽管COVID-19监测和相关数据集在大流行期间有了很大改善,但这些努力在COVID-19之后必须保持,信息系统必须稳定6,7(例如,https://coronavirus.jhu.edu)必须继续以强有力的方式评估全球疾病动态。
 阅读论文:SARS-CoV-2的神秘传播和第一波COVID-19
阅读论文:SARS-CoV-2的神秘传播和第一波COVID-19 接触追踪应用程序遏制了新冠病毒在英格兰和威尔士的传播
接触追踪应用程序遏制了新冠病毒在英格兰和威尔士的传播 针对旅行者进行COVID检测的机器学习算法
针对旅行者进行COVID检测的机器学习算法



