愿意分享数据的研究人员并不总是得到那些评估研究的人的适当信任。信贷:盖蒂
有时,似乎有一种不可阻挡的趋势,即数据集应该广泛用于研究目的(也称为开放数据)。全世界的研究资助者都是支持开放数据管理标准被称为FAIR原则(确保数据可查找、可访问、可互操作和可重用)。期刊越来越多地要求作者将论文背后的潜在数据提供给同行。数据集带有数字对象标识符(DOI),因此可以很容易地找到它们。这种可引用性有助于研究人员为他们生成的数据获得荣誉。
但现实有时会告诉我们一个不同的故事。世界上评估科学的系统(目前)还没有像评估期刊文章或书籍等产出那样,对公开共享的数据进行评估。设计这些系统的资助者和研究负责人承认,科学产出有很多种,但许多人拒绝接受它们之间存在等级关系的观点。
在实践中,当涉及到招聘和晋升决策,或授予重要委员会的成员资格,或在国家评估系统中,那些在科学领域位高权重的人往往不会以同样的方式看待公开数据集。除非这种情况发生改变,否则开放数据革命将停滞不前。
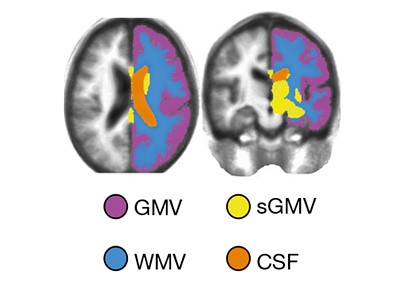
阅读论文:人类寿命的大脑图表
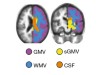
本周,英国剑桥大学的Richard Bethlehem和费城宾夕法尼亚大学的Jakob Seidlitz及其同事发表了描述大脑发育“图表”的研究。r.a.i.伯利恒et al。自然https://doi.org/10.1038/s41586 - 022 - 04554 - y;2022).这些类似于记录一个人一生中身高和体重的图表,研究人员和临床医生可以访问这些图表。
这项工作从未如此大规模地进行过:通常在神经科学领域,研究都是基于相对较小的数据集。为了创建一个更具有全球代表性的样本,研究人员从100多项研究中收集了大约12万份磁共振成像扫描结果。并非所有的数据集最初都可供研究人员使用。例如,在某些情况下,正式的数据访问协议限制了数据共享的方式。
一些数据原本属于专利的科学家成为了这篇论文的积极合著者。相比之下,那些从一开始就可以访问数据的研究人员在论文的引用和致谢中都有功劳,这是出版业的惯例。
这种做法既不新鲜,也不局限于某个特定领域。但结果往往是相同的:公开共享数据集的作者有可能无法获得晋升或终身职位所需的荣誉,而那些在出版物中被命名为作者的人更有可能获得促进其职业生涯发展的好处。
用于数据重用的信用数据生成器
只要发表论文的作者身份是获得科学贡献功劳的主要方式,这种情况是可以理解的。但是,如果开放数据在评估、招聘和晋升过程中得到与研究文章同样的正式认可,研究小组将失去至少一个保持数据集封闭的动机。
大学、研究小组、资助机构和出版商应该一起开始考虑如何在他们的评估系统中更好地识别开放数据。他们需要问一问:那些在开放数据方面付出额外努力的人,如何得到适当的信用?
研究人员无法获得人类数据的情况总是存在的。例如,婴儿的数据是高度敏感的,需要通过严格的隐私和其他测试。此外,让数据集可访问需要时间和资金,而研究人员并不总是有。低收入和中等收入国家的研究人员担心,他们的数据可能被高收入国家的研究人员或企业以他们不同意的方式使用。
但是,把所有为研究成果贡献知识的人都归功于他们是科学的基石。目前流行的惯例——即那些将自己的数据公开给研究人员使用的人,只需承认和引用即可——需要重新思考。只要论文的作者身份明显比数据生成更有价值,这就会抑制开放数据集的积极性。我们越早改变越好。
 阅读论文:人类寿命的大脑图表
阅读论文:人类寿命的大脑图表 让科学数据公平
让科学数据公平 用于数据重用的信用数据生成器
用于数据重用的信用数据生成器 数据共享以及它如何有益于你的科学事业
数据共享以及它如何有益于你的科学事业