期刊和资助机构越来越多地要求稿件作者应要求分享数据或公开信息。从技术角度来说,这是一个很大的要求,但一些简单的策略可以简化这个过程。
科学论文很少包含用于证明结论的所有数据,即使是在补充材料中。作者可能会担心被抢先,或者担心其他研究人员会利用原始数据做出新的发现,或者他们可能希望保护研究参与者的隐私。或者,更有可能的是,作者既没有时间也没有专业知识来打包数据以供他人查看和理解。
这种沉默让研究界付出了代价。数据透明度允许其他人重复分析并发现错误或欺诈性索赔。它允许通过对现有数据集的再分析获得新的发现,并增加了对科学过程的信任。今年8月,白宫科技政策办公室宣布,到2025年,所有由联邦政府资助的新研究的科学数据必须向美国公众开放.在提交论文时,越来越多的作者被要求向编辑提供原始数据,将数据放到网上,或者包括是否应要求提供数据的数据共享声明。不幸的是,这类政策并非无懈可击,正如同类研究中规模最大的一份明确文件所显示的那样。
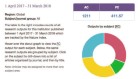
今年5月,在萨格勒布的克罗地亚天主教大学(Catholic University of Croatia)研究循证医学的利维娅·普尔贾克(Livia Puljak)和她的同事发表了一项研究,他们研究了由BioMed Central出版的约300种期刊。BioMed Central是一家开放获取出版商,隶属于施普林格Nature,该杂志也有出版物自然.研究人员确定了2019年1月发表的1792份手稿,这些手稿宣称他们的数据“应要求”或“应合理要求”提供,1.2021年初,他们给通讯作者发了电子邮件,要求访问原始数据。为了消除人们对这项研究可能会产生令人尴尬的结果的担忧,他们指出,分析将是匿名的:“我们不会透露任何关于作者特征的细节,”他们写道。

数据共享以及它如何有益于你的科学事业
254位作者进行了回复,其中123位分享了他们的数据。在不分享数据的受访者中,最常见的情况是,他们要求更多的信息,然后在得到这些信息时保持沉默(17%);他们说他们不被允许分享数据(11%)或不能访问数据(9%);或者他们没有给出解释(8%)。这项研究发表在临床流行病学杂志,因为作者不想公开羞辱其他作者,所以没有公开的原始数据。
所有参与研究的期刊都要求作者声明他们是否愿意分享他们的数据。但由于分享不是发表的条件,不清楚为什么不打算分享数据的作者不直接说出来。普贾克说:“也许他们给出了社会可以接受的答案。”“可能,人们没有真正考虑过,当有人真的要数据时会发生什么。”
英国牛津大学的流行病学家Tom Jefferson说,作者应该为虚假的数据可用性声明承担后果。他表示:“编辑们应该采取行动,无论是更正还是撤稿。”他补充称,以不再拥有这些数据为借口,就像是在说“猫吃了我的文件柜”。但是位于弗吉尼亚州夏洛茨维尔市的开放科学中心(COS)的政策主任大卫·梅勒(David Mellor)并不赞成撤销。“这是一种钝器,”他说。提到这项研究的发现,他指出,“有可能这封电子邮件只是没有被看到。”
伦敦玛丽女王大学(Queen Mary University of London)的计算社会科学家瓦伦丁·丹切夫(Valentin Danchev)称这项研究是了解数据共享实际状态的有益一步。但是,他补充说,“我们需要更多这样的研究,这样我们就可以在不同的领域和不同的调查设计中进行推广。”
去年,丹乔夫与人合著了一项研究2有487个临床试验发表在《美国医学会杂志》,《柳叶刀》或新英格兰医学杂志.其中89篇文章的作者表示,他们将数据集存储在了在线存储库中,但丹乔夫的团队只能在指定的位置找到17篇。
2020年,日本丰ake藤田卫生大学的行为神经科学家Tsuyoshi Miyakawa分子的大脑他在一篇社论中写道3.自2017年以来,他在发表前向41篇论文的作者索要了原始数据,因为他觉得提交的数据“太美了,不像是真的”。其中21篇论文的作者撤回了他们的论文,他以数据不足为由拒绝了其余19篇论文。这一经历让Miyakawa有些怀疑:在社论中,他建议编辑们不要再假设研究人员是诚实的。
数据定义
研究人员表示,改革可能需要从高层开始。Puljak和她的合著者说,他们希望要求作者在发表之前提交原始数据的做法能更广泛地使用。他们并不孤单。记者联系的几位研究人员自然他说,期刊应该承担一些责任,因为它们优先考虑原创研究和订阅费用,而忽视了对数据共享的监管。当被问及出版商是否有责任确保作者遵守他们的数据共享声明时,施普林格Nature的研究完整性主管Chris Graf说:“尊重作者关于数据共享的声明是作者或他们的机构的责任。”(自然的新闻独立于出版商。)

许多研究人员说他们会分享数据,但实际上并没有
“数据共享”意味着可以根据要求从研究作者那里获得数据;“开放数据”的相关但不同的概念意味着数据可以通过在线存储库和相关资源广泛访问。梅勒说,普贾克的研究“表明‘可随时索取’并不能解决问题”。一项研究表明,“开放数据”表现更好4的论文发表于8月《公共科学图书馆·综合》。发现88%包含url或DOI代码的数据可用性语句包含足够的信息来检索数据。
多学科知识库,如Figshare(归施普林格Nature所有)、Zenodo(由欧洲核子研究中心(CERN,位于瑞士日内瓦附近的欧洲粒子物理实验室)和OSF运营。io(由COS操作)是数据沉积的流行选项。但是梅勒说:“任何专门为你正在生成的数据类型设计的存储库可能都是最好的。”像高能物理的HEPdata和神经成像的OpenNeuro这样的存储库,通常将数据格式化为社区标准,并使这些领域的研究人员能够发现它们。一些公司还制定了保护医疗记录等敏感数据的协议。
密歇根大学安娜堡分校(ICPSR的总部所在地)的政治和社会研究校际联盟(ICPSR)提供广泛的、专业的数据管理,该组织支持开放的社会科学,Amy Pienta说。ICPSR管理员检查丢失的数据,审查数据质量,并创建一个数据标签字典。为了保护参与者的隐私,他们可能会删除识别信息或限制授权用户访问。
皮恩塔建议那些整理自己数据的研究人员也要遵循这些步骤。她说:“数据的可重用性来自于以一种足够有组织的方式创建元数据,这样人们就可以在不需要你监视的情况下理解研究。”她补充说,要仔细考虑,甚至是文件格式。例如,一些期刊只允许pdf格式的补充文件。“这是一场噩梦,”Puljak说,因为这种格式会使提取数据用于后续分析变得困难。
OpenAIRE、FOSTER Plus和Orion等欧盟资助的项目提供了开放科学的培训材料,包括讲习班、指南和在线课程。
思考未来
根据梅勒的说法,如果研究人员希望提高数据的可用性,他们需要减少事后的考虑。他说:“人们很倾向于把数据共享作为过程中的最后一步,这一步并不太重要。”“这促使我们将大量精力集中在研究过程的初期。”
研究预注册,即作者在开始分析之前分享他们的实验和分析方案,以阻止选择性发表积极结果和糟糕的统计实践,如“P梅勒说,“-hacking”与公开数据和方法密切相关。“在一项研究的开始,精确地确定数据将如何收集和保存,以及将测试什么假设——这真的为成功奠定了基础。然后,随着数据的收集,填充数据位就成了问题。”

NatureTech中心
COS在OSF.io上有一个研究注册表。该组织还创建了徽章,以表明预先注册,以及开放数据和开放材料,参与的期刊可以在论文中放置。梅勒说,目前有120多家期刊展示了这种徽章,从而通过表明“它不像我们通常认为的那样奇怪或古怪”,使开放科学正常化。
皮恩塔说,提前制定数据共享计划也“让你自己的科学研究变得更好”。共享数据和开放数据可以增加你的论文被引用的次数,如果其他研究人员使用这些数据,甚至可以让你的论文成为合著者。存储在存储库中的数据集可以接收它们自己的doi,将它们变成独立的出版物,可能会取悦授予和保留期委员会。
除了这些优势之外,还有一种满足感,那就是让你的研究成果被广泛使用,特别是在大流行期间。Puljak说:“如果有人在收集这种新疾病的数据并分享它,它就可以帮助整个世界。”
 许多研究人员说他们会分享数据,但实际上并没有
许多研究人员说他们会分享数据,但实际上并没有 为什么数字徽章不起作用
为什么数字徽章不起作用 数据共享以及它如何有益于你的科学事业
数据共享以及它如何有益于你的科学事业 数据共享:对开放数据持开放态度
数据共享:对开放数据持开放态度 NatureTech中心
NatureTech中心