








摘要
在终生患病风险和疾病表现方面的性别差异是众所周知的。临床前研究的目标是改善治疗,延长健康周期,减少卫生保健的财政负担,主要是在雄性动物和细胞上进行的。表现型性状的性别差异在多大程度上可以用体重的性别差异来解释还不清楚。我们量化了雄性和雌性小鼠363个表型性状性状值与体重之间异速生长关系的性别差异,记录在国际小鼠表型联盟的200万次测量中。我们发现异速生长参数(斜率、截距、残差)的性别差异是普遍的(73%性状)。体重差异不能解释性状值的所有性别差异,但按体重缩放可能对某些性状有用。我们的结果表明,表型性状的性别差异是性状特异性的,促进了按小鼠体重缩放药物剂量的病例特异性方法。
简介
在临床前研究中使用雄性动物,在临床试验中使用男性参与者,这在世界各地的医疗系统中造成了严重的偏见1.现有的关于许多疾病的知识、其表现、时间进程和治疗方案的效力都严重偏向男性。在生物医学研究中实现性别平等和对研究结果进行性别分析的必要性已得到广泛承认2,3.,4,5,6.解决这一问题的努力导致了临床研究的立法变化,要求政府资助的临床试验的女性参与者(例如,7,8,9).在临床试验中性别比例再平衡方面有适度改善10,11,12最近美国政府对临床前研究指南的修订,要求将生理性别作为研究变量,这一点得到了支持13.
小鼠的临床前研究,这是研究人类疾病最常见的动物模型之一14,15,是临床研究的基础。这些数据阐明了临床相关的药理学过程,并使治疗效果的测试成为可能,这将引起人类的伦理和安全问题15.随着人们越来越认识到性别在生物医学中的重要性,在小鼠数据中对这一主题的更尖锐的关注表明,在临床前研究中使用雌性动物的一些最初的假设和担忧,例如它们与发情周期相关的更大变异倾向,缺乏经验支持2,16,17,18.
建立在实证研究的基础上,这些研究试图建立生物医学中性别差异的本质,并澄清围绕在男性身上收集并推广到女性身上的临床前研究数据的假设2,18,19,20.,我们在这里使用异速生长框架和大型表型数据集来解决尚未解决的问题,即小鼠表型性状的性别差异是否可以用体重的性别差异来解释。体重在多大程度上可以消除性别作为一个自变量的统计学意义仍不清楚21然而,围绕如何有效地缩小健康差距的辩论是重要的。异速标度的数据与性别差异最显著的方面之一有关,即药物不良反应(adr)。与男性相比,女性发生不良反应的频率几乎是男性的两倍22在美国,男性和女性服用的剂量通常相同23.定义男性和女性表型性状和体重之间的异速生长关系,是为了更好地理解这种关系是否在不同性状中得到维持,以及大多数观察到的差异是否由于尺度。这将有助于了解大多数性别特异性不良反应是否可以通过实施体重调整剂量来解决,如果不能,使用体重调整剂量是否有助于在某些情况下减少性别特异性不良反应。
研究表明,疾病经历的性质和治疗的益处在男性和女性之间是不同的24,25,26,27,28,29对许多系统来说,观察到的性状的性别差异与潜在过程的差异有关,而不是体型的性别差异。这些差异体现在医疗保健的主要支柱上,影响着与护理相关的成本及其质量30..例如,男性(抗炎)和女性(促炎)免疫系统的广泛不同行为转化为抗体反应的可变性,与女性相比,一些疫苗导致男性的免疫反应更强31,32,33,34.此外,代谢的性别差异是小鼠和大鼠模型中代谢综合征疾病(如肥胖)表型更明显表达的基础35.这些与代谢稳态的基本调节差异有关,影响能量分配和存储。两性之间的病理生理差异也已在心脏病学中得到承认,例如从冠状动脉造影中提取的诊断数据以性别特异性的方式解释36.在药物治疗的背景下,药代动力学的性别差异与吸收率(如胃酶)有关37)、分布机制(如等离子体结合能力38)和代谢(如肾消除能力)导致男性的游离药物浓度较低,而药物清除率较高38.同样,肾功能的主要方面也存在性别差异(如肾小球滤过率39)意味着一种药物对男性和女性身体的影响也是不同的,这与药代动力学参数一起,转化为药物疗效和毒性的差异22.在已经确定性别差异的许多系统之外,我们在这里提供了代表疾病模型动物(小鼠)临床前参数(例如,免疫、代谢、形态学)的表型性状静态异速生长的经验数据。我们的目的是阐明雄性小鼠的特征值是否以及在何种程度上可以缩放以匹配雌性小鼠的特征值。
在这里,我们表明体重的性别差异并不能解释雄性和雌性小鼠之间表型性状的所有差异,强调异速生长的性别差异可能会影响生物医学的研究结果。我们采用静态异速生长法的框架,即按照赫胥黎的理论,测量不同大小的个体在同一发育阶段的性状共变异40,41他提出了一个方程来模拟简单的异速生长。这个方程表达了两个性状的生长,x而且y,当由共同的生长参数调节时:y=斧头b或者等价地,logy=日志(一个) +b日志(y),其中各组成部分的增长率之比为y而且x对应截取日志(一个)和斜率b42.我们量化了男性和女性的表型性状和体重之间的关系,统计评估了描述国际小鼠表型联盟200多万只小鼠363个性状的性别差异的大小和模式的场景43(IMPCwww.mousephenotype.org).我们讨论这些数据,考虑到在临床前研究中对男性数据的概括44,以及它们的进化意义,利用大型野生型数据集来阐明静态异速生长的趋势。对围绕性别差异的进化背景的考虑可以增强对疾病状态表型如何在种群中出现或持续的理解45,46.
结果
数据的特点
在初始数据清洗和过滤程序后,数据集包含363个表型性状,每个性状的平均样本量为2866只小鼠(n= 2080767)。在大多数表型性状中,男性和女性的表现高度相似,只有不到15%的性状(53/363)在性别之间的样本量差异大于5%。根据Zajitschek等人的研究,这些性状被分为九个功能组。18(见“方法”):行为(85个特征,n= 440,491),眼睛(40个性状,n= 21,871),听力(21个性状,n= 273,715),心脏(31个性状,n= 233,772),血液学(24个性状,n= 291,214),免疫学(99个性状,n= 92,130),代谢(8个性状,n= 108,788),形态学(21个性状,n= 287,420)和生理(34个性状,n= 331366)。
对363个表型性状进行非独立筛选,得到p将彼此相关的性状的值合并,使数据集减少到219个性状,每个性状的平均样本量为3530个男性和3598个女性。
静态异速测量的线性混合效应模型
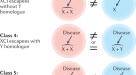
我们的线性混合效应模型,包括亚品系作为随机效应,表明219个性状中有11个(5%)(17/363个性状未合并p值)与情景A(不同斜率,相同截距,图。1 a, d);这些性状大多属于免疫和心脏功能类群。情形B(相同斜率,不同截距,图。1 b, e)支持93/219(42%)个性状(未合并的154/363个性状)p值)。对于情形C(不同斜率,不同截距,图。1 c、f), 57/219(26%)性状被归类为一致(70/363为未合并性状p值),其余58/219(26%)性状的斜率和截距在雌雄间无显著差异。总体而言,当性别间异速生长模式存在统计学显著差异时,截距差异比斜率差异更常见(42%比5%),但斜率和截距差异也都常见(26%)。只有超过四分之一的性状在男性和女性之间没有显着差异,这表明,对于大多数性状来说,异速生长模式的性别差异代表了性状值变化的重要来源。所有斜坡都表现为次异速生长,斜率值<1。

上面一行表示体重(x轴)和眼睛大小(y轴)之间的假设正相关关系,下面一行表示体重和活动水平(y轴)之间的负相关关系。体重被缩放并居中,因此截距位于灰色虚线表示的特征平均值。下面给出了一系列场景。一个两性表现出不同的正斜率但相同的截距。b两性的正斜率相同,但截距不同。c两性表现出不同的正斜率和不同的截距。d两性表现出不同的负斜率但相同的截距。e两性的负斜率相同,但截距不同。f两性有不同的负斜率和不同的截距。
我们对应用模型的模型拟合性进行了比较,包括小鼠亚品系作为随机因素,以及不含亚品系的模型,结果表明,在未合并的比较中,考虑亚品系变异导致我们的模型对248个性状中的155个(63%)的拟合性显著提高。随机加入亚品系时,具有显著δAIC值(δAIC)的性状数量最多的功能类群是心脏(25/31个性状,81%)和免疫(51/63个性状,81%)。在合并比较中,154个性状中有98个(64%)的模型拟合显著更高。
综合来看,各功能组的性状均有统计学意义(α= 0.05)性别差异。性别间的斜率差异(情况A)和性别间的截距差异(情况B)在行为、免疫和生理组中最为常见。表现出性别间斜率和截距差异的特征(场景C)在行为、生理和血液学功能组中最常见。在行为组和眼功能组的性状中,坡度和截距的差异最为常见。
异速生长参数的性别偏见
性别偏向值表示当雄性和雌性小鼠差异显著时,表现出更大参数值的特征的数量。也就是说,我们计算哪一性别表现出更大的截距、斜率和更高的方差幅度。斜率和截距值的性别偏倚,除了方差的大小(剩余SD)外,在功能组中显示了相当大的变异性,这表明性别差异的特征特异性模式。情景A为坡度差异显著的性状,大多数性状在雄性中表现出较大的坡度幅度(n= 10个特征),而不是女性(n= 7个性状)(图2).对于场景B,女性在心脏、形态学、免疫学和眼部功能组表现出更大的截距幅度(n= 91个性状),而男性在生理、代谢、血液学、行为和听力功能组(n= 63个性状)(图;2 b).总体性别偏见(63个男性特征:91个女性特征,图。2 b)的截距差异略大于斜率差异(10个男性性状:6个女性性状,图。2).情景C表示性别间显著的斜率和截距参数差异,在九个功能组中有三个以混合偏倚为主(n= 26个性状),表明性状最常表现出偏倚的方向差异的混合,包括一个参数(斜率或截距)中的男性偏倚和另一个参数(斜率或截距)中的女性偏倚的组合(图。2摄氏度).在情形C下,免疫和听力相关性状是一个例外,即具有显著性别差异的性状在斜率值和截距值上没有表现出混合偏倚,与性状之间的性别差异较小一致。在各功能组中,残差性别差异有统计学意义的男性偏倚(5组)略高于女性偏倚(4组),这表明在特征表现出性别差异的地方,男性比女性更容易变化,反之亦然(图2)。二维(152个男性特征:97个女性特征)。

性别偏差表示一个性别的参数值(斜率、截距、方差)比另一个性别更大。颜色代表了两性之间特质值的显著差异(绿色=男性偏向,橙色=女性偏向)。雌性偏倚(橙色条的相对长度)或雄性偏倚(绿色条的相对长度)的性状数量表示为对应组中性状总数的百分比。绿色条内的数字表示在给定的特征组中表现出男性偏见的特征的数量,橙色条内的值表示女性偏见的特征的数量,紫色条内的值表示女性偏见(拦截或斜率)和男性偏见(拦截或斜率)的组合。一个坡度的性别差异。b拦截的性别差异。c斜率和截距的性别差异,包括具有混合显著差异(紫色)的性状(即男性偏倚显著斜率和女性偏倚显著截距,或女性偏倚显著斜率和男性偏倚显著截距)。d性别间方差差异(残差标准差)有统计学意义的偏倚。
斜率、截距和方差的性别差异的元分析和元回归
异速斜率和截距绝对值及方差的多层次元分析显示性别间存在显著差异(图2)。3得了).总体比较(图;3得了),效应量范围为显著(即置信区间[CI]不与零重叠)点估计值0.089 [0.063-0.115,CI](图。3)将截距的性别差异降至0.152 [0.1.5-0.200,CI](补充表1)的残差(图;3 c).在各功能组中,在参数(即截距)和跨参数中,两性之间的绝对差异的大小存在差异。对于截距的绝对差异,行为功能组内的性状在男性和女性之间的模型点估计差异最大(0.140 [0.115-0.166,CI](补充表1).所有组的效应量均显著(补充表1),除了听力组内的性状,其差异幅度最小(图。3 d),点估计值为0.049[−0.034至0.132,CI](补充表1).对于坡度的差异,除听力组外,所有类别均表现出显著的效应量(补充表1).免疫性状的模型点估计差异最大(0.037 [0.029-0.046,CI]),几乎是形态学性状的效应量(0.010 [0.002-0.017,CI])的4倍(图2)。3 e,补充表1).

果园图显示模型点估计(黑色开放椭圆)和相关置信区间(ci)(黑色粗水平线),95%预测区间(pi)(黑色细水平线;PI代表异质性),以及个体效应大小(填充圆),由其样本量(N)缩放,即每个性状所包含的小鼠数量。效应量的数量(表型性状的数量)表示为k.一个男性和女性异速截距绝对值的总体差异。b男性和女性异速斜率绝对值的总体差异。c男性和女性剩余方差(SD)值之间的总体差异。d男性和女性异速截距值的差异,以官能团分开。e男性和女性异速斜率值的差异,以官能团分隔。f男性和女性残差方差(SD)值之间的差异,以功能群分隔。
对于残差的相对差异,眼组(0.292 [0.228-0.357,CI])和免疫组(0.234 [0.184-0.283,CI])的效应量最大,是心脏组(0.091[0.038-0.145])效应量最小的2 - 3倍(补充表)1).听力特征在性别间的SD值最相似,具有不显著的效应量(0.087[−0.04至0.216,CI])(图2)。3 f,补充表1).总体而言,在所有参数(截距、斜率、SD和模型拟合)中,听力特征的置信区间(ci)是唯一一个始终与零重叠的参数,表明性别之间没有统计学上的显著差异(图2)。3 d-f,补充表1).对于特定功能组内的特征,两性之间的差异有相当大的差异。对于截距的性别差异,生理、代谢和行为组的性状间变异性最高。3 d),而斜率差异在眼睛和行为性状上表现出最大的性状间变异性(图。3 e).在眼组各性状中,SD的相对差异最大。3 f).
斜率/截距与剩余方差的关系
我们的四变量元回归和斜率、截距和剩余方差之间关系的排序(图2)。4)显示斜率或截距与剩余方差(r= 0.07-0.14,图4 a、b),表明无论是斜率参数还是截距参数,两性差异的幅度越大,与性状方差越大的相关性不强。相反,两性在斜率和截距上的绝对差异是强而显著相关的(r= 0.82,图4摄氏度),表明在男性和女性性状值存在显著差异的情况下,如果存在截距差异,则可能伴随着异速生长斜率的差异。

图显示生物性状被整理成9个功能组(即性状类型,用不同的圆圈颜色表示)。个体效应大小(圈)按其样本量(N)缩放,即每个特征所包含的小鼠数量。一个异速截距与残差的关系。b异速斜率与残差的关系。c异速斜率与截距的关系。
讨论
目前的大多数医学指南都不是针对性别的,是根据仅在雄性动物身上进行的临床前研究得出的4,10,47假设这些结果同样适用于女性,或者女性表型代表着男性表型的较小体型版本48,49.我们发现73%的性状是二态的,要么是斜率和截距,要么是斜率和截距同时存在,其中42%的性状在雄性和雌性小鼠之间表现出尺度差异。尺度差异并非在所有表型性状中都得到支持,这表明体重本身不足以解释表型性状的性别差异,但它可能对某些性状有用。
在个性化医疗干预触手可及的时代,针对患者的解决方案是医疗保健领域可实现的前沿(例如,50,51,52),现在人们普遍认识到,非常需要基于性别的数据,以公平和有效的方式推进护理。随着阐明性别差异的存在和重要性的研究不断出现,许多使用两性的实验机构继续避免对性别差异进行下游测试,部分原因是认为这类分析所需的样本量膨胀48,53,54,55.
为了阐明性别差异的本质,需要进行明确的男女比较47,56.在这里,我们通过一个新的元分析重点来解决这个问题,该重点是在广泛的范围内识别和表征生物性状的异速标度关系。我们的荟萃分析结果在所有功能组中恢复了斜率、截距和剩余SD的性别差异的显著效应值,唯一的例外是分配给听力组的特征,在所有分析的异速生长参数中,男性和女性的特征相似(CI重叠为零)(补充表)1、补充数据1、补充数据2).标准化平均差异(SMD或Cohen’s)d)表明9%的性状存在中等效应量(33/363),主要在行为、眼睛和生理组内;7%的性状存在较大效应量(25/363),主要在行为、代谢、形态和生理组间(补充数据)2).另外29%(106/363)的性状分布在所有功能类群中,表现出较小的效应量(SMD > 0.2),其余性状的SMD值在量级上低于0.2(补充数据)2).我们确定斜率参数(b)的差异,并发现这些差异大多与截距值的显著差异有关(图。4摄氏度).在男女坡度存在显著差异的地方,女性坡度比男性坡度更陡的比例为38%,男性坡度比女性坡度更陡的比例为62%(补充数据1).如果女性的斜率更陡,忽略性别之间的斜率差异,将导致这些性状的性状方差缺失0.3-32.6%(平均= 8.9%),主要属于生理和行为和眼睛组(补充数据1).同样,如果男性的斜率更陡,忽略性别之间的斜率差异,将无法捕获这些特征中0.3-46.1%的方差,最显著的是形态学、血液学和心脏组(补充数据)1).
我们证明,小鼠的性状和体重之间的关系在两性之间的模式(即性状间协方差的变化)上存在根本差异,而且二态性不能完全用截距值的幅度变化来解释,如果女性表型代表男性表型的缩放版本,则可以预测。对于性别间斜率和截距均存在显著差异的性状,通常会出现混合情况(男性偏倚显著斜率和女性偏倚显著截距,或女性偏倚显著斜率和男性偏倚显著截距)(26%),这意味着不能根据从男性收集的回归数据中提取的异速生长系数来预测女性值。此外,我们发现残差SD存在男性偏倚,表明在形态学、免疫学、血液学、心脏和听力功能组(9个功能组中的5个)的特征上,男性差异更大。
我们对特征特异性异速生长模式的发现补充了最近的证据,这些证据支持在动物研究中常规记录的标记中复杂的、特征特异性的性别差异模式18,20.,57.先前使用国际小鼠表型联盟表型性状的研究已经确定,性别二态性在表型参数中普遍存在20.此外,与长期以来的假设相反,女性和男性都没有表现出更大的特征变异性。
我们提出了一个问题,即表型性状的全部或部分性别差异是否由于体重的差异,这对药物治疗有影响,特别是围绕按体重缩放的药物剂量的疗效的数据。
在药物处方流行率和使用模式以及对药物治疗的反应方面存在已知的性别差异58,59.由于药代动力学和药效学特征的性别差异,相同的治疗方案可能引起不同的反应(例如,60,61),这是由潜在的生理差异引起的。这些包括,例如,在我们的分析中,在生理组中捕获的显著二态特征,如铁62和体温63形态组中,如瘦质量和脂肪质量58,心功能组间,如QT间期(Q波与T波之间的时间)64.此外,女性出现药物不良反应(adr)的可能性要高50-75%65,尽管这些并没有完全解释23.女性发生不良反应的风险可能会增加,因为她们被开的药比男性多,但女性通常被开的药剂量与男性相同,这意味着在大多数情况下,相对于体重,女性接受的剂量更高。建议以毫克/公斤体重为基础按比例增加剂量,作为减少不良反应的途径22特别是那些呈现陡峭剂量反应曲线的药物66.事实上,adr的性别差异被认为是体重而不是性别本身的结果21.为了支持这两个断言,我们将期望观察到一个场景(这里是场景B),其中大多数或所有表型性状在男性和女性之间表现出比例关系,作为体重的函数。
我们的结果表明,42%的性状遵循情景B,许多性状(26%)也支持体重和表型性状之间的性别和性状特异性关系。这与体重校正药代动力学在男性和女性中不能直接比较的证据一致22,67,并且在体重校正后,adr的许多性别差异仍然存在68,69.尽管如此,美国食品和药物管理局(FDA)建议改变女性的剂量(例如,睡眠药物唑吡坦70)和一些药物的体重调整剂量,如抗真菌药物和抗高血压药物,这似乎可以改善药代动力学的性别差异71,72.我们的结果与支持在某些情况下缩放一致,这些特征中最多的出现在免疫组和心脏组,其中包含与药代动力学和药效学因素最密切相关的参数。尽管承认在已知的情况下,小鼠模型无法捕捉人类对治疗药物(例如癌症治疗)的反应73),我们建议情景B中的特征作为进一步研究体重调整剂量的候选。如果基于截距缩放支持重量调整剂量(场景B),异速生长关系的变化可能降低这种方法的疗效的程度也需要考虑。在我们的分析中,这是通过模型拟合来衡量的,其中更大的模型拟合相当于更多的由体重解释的男性和女性表型性状的方差。对于那些扩展的特征(场景B),因此最有用的剂量扩展候选可能被那些具有最高模型拟合的特征(Zr,从R转换而来)捕获2边际)(补充图2).这些特征包括器官质量(R2边际= 0.82)和瘦质量(R2边际= 0.71),以及与脂质和葡萄糖参数相关的生理和代谢特征(如高密度脂蛋白胆固醇,R2边际= 0.60;葡萄糖响应曲线下面积,R2边际= 0.50)。模型拟合较低的性状可能会缩放,但表型性状中相当数量的方差不能用体重来解释,因此缩放可能无法达到预期的临床结果。在情景B中,符合这一标准的特征最常在眼睛、形态学和生理学组中发现。
我们认为,如果存在性别和剂量之间的关联,剂量-反应曲线可能是性别特异性的,并支持澄清这种关系(例如,使用荟萃分析)74).由于许多药物由于女性不良反应的风险而从市场上撤出,用于阐明性别特异性剂量反应曲线的荟萃分析方法代表了减少不良反应数量和达到精准医疗设定的重要目标的可行机会75.我们进一步注意到,行为因素,例如寻求健康行为和处方模式的差异,可能与女性使用大多数治疗药物的流行率高于男性有关59,76,并没有被我们在小鼠身上的数据捕捉到。
在个体发生、种群和进化水平上建立了形态变异的基本描述符77,78,异速生长可能在固定的方向上引导表型变异,定义在大的进化时间尺度上持续存在的缩放关系。例如,哺乳动物的颅面变化被观察到受到异速生长的限制,比如小型哺乳动物的脸比大型哺乳动物的脸短79.相反,异速生长可能促进形态多样化,作为“进化阻力最小”的一条线,允许在密切相关的物种中相对快速地产生新的形态类型42,80.这些途径(异速生长限制vs异速生长促进)可能是探索疾病表型性别差异如何产生的起点,这些数据已被引用为与开发新疗法相关的潜在未开发资源81.静态异速生长的研究,如本文所述,揭示了种内异速生长斜率的低水平变化,这只能解释很小比例的大小变化82,相对于异速截距的变化83.此外,性别选择下的性状在人工选择实验中也表现出较小的异速斜率变化84在野生种群中85,而截距变化则显得清晰且可遗传。发展系统的特征以前被认为是一种内部约束40,86,而最近的解释表明,外部约束(选择)更有可能在静态水平上保持斜率不变性42,这与表明变异发生在个体发生水平的数据是一致的,即生长速率和个体发生异速生长斜率是可进化的(例如,87,88,89).与其他静态异速生长研究大体一致的是,我们发现在异速生长存在差异的地方,显著的截距偏移比显著的斜率偏移更常见。2相比于2b)。除了进化意义之外——异速生长的坡度可能没有很高的进化能力,或者进化能力——这里研究的许多特征可能表明坡度的性别差异水平很低,因为两性都经历着相同的选择压力,以维持不同体型的功能性大小关系。
我们的元分析结果构建了基于性别的性状相互作用复杂性的叙述,并促进了临床前研究的特定病例方法,旨在为药物发现、开发和剂量提供信息。使用一个包括小鼠亚品系的模型,在一系列不同的表型性状中,我们表明体重的差异不足以解释性状值的性别差异,但缩放差异是常见的,体重缩放可能有助于某些性状。我们的研究结果证明了静态异速生长的可塑性,揭示了表型性状中性别变异的途径,该途径可能在啮齿动物之外推广,并在更广泛的范围内奠定了表型空间的模式。异速生长的性别差异可能会影响生物医学的研究结果。
方法
数据编译和过滤
我们在R环境v. 4.1.3中进行了所有的数据处理和统计分析90(数据集和脚本可在Zenodo91).我们从国际小鼠表型联盟(IMPC)汇编了我们的数据集(www.mousephenotype.org, IMPC数据发布于2019年6月10.1日),于2019年10月访问。这些表示在高通量表型设置中记录的特征,其中标准操作程序(sop)在管道概念中实现。表型性状代表用于疾病表型研究的生物标志物(见参考文献)。20.),分为以下九个功能组:行为、眼睛、听觉、心脏、血液学、免疫学、代谢、形态学和生理学,这是IMPC最初的分类(也曾在Zajitschek等人中使用过)。18).这些分组是根据数据点收集过程的描述和成人阶段管道事件的分类进行分配的,详细内容见国际标准化筛选小鼠表型资源(IMPReSS,https://www.mousephenotype.org/impress/index).性别是使用所有活幼崽的标准操作程序来操作的,所有数据都是一致的,并且是管道中主要生存能力筛选的一部分。根据外生殖器的形态对小鼠进行了性别区分。
对于初始数据集,仅对成年野生型小鼠的数据点进行整理,过滤以包括可获得关于性别和体重的协变量信息的非分类表型性状值。注意,所有小鼠都来自C57BL/6菌株,但它们来自7个亚菌株。该初始数据集由419个性状的2,866,345个数据点组成。实施了一系列数据清理程序,以删除缺失体重的数据点,表型性状的零值和重复的标本id。使用R包dplyr v.1.0.7进行数据过滤92.结果数据集包含379个表型性状的2118,370个数据点,所有这些性状都有相应的体重数据,使我们能够估计感兴趣的性状与体重之间的异速生长关系。其中89个性状(24%)处于区间尺度,因此调整为比值尺度。对于每个表型性状,我们有以下变量(协变量):表型中心名称(收集实验数据的地点)、外部样本ID(动物ID)、元数据组(实验期间实验条件的标识符)、性别(男/女)、体重(体重单位为克)、出生日数(记录体重的日期)、品系名称(小鼠亚品系的标识符)、程序名称(IMPReSS中实验程序的描述)、参数名(在IMPReSS中记录参数的描述)和数据点(表型性状测量-响应变量)。
静态异速测量的线性混合效应模型
异速生长的静态形式,在单个物种的成年种群中测量的特征与大小的共变78,采用线性混合效应模型方法进行量化93.在这个框架内,表型性状值和体重之间的关系,考虑与亚品系相关的随机效应,分配到元数据组和批(定义为收集测量的日期),对379个性状中的每个性状进行量化。我们使用体重而不是肥胖(特征~脂肪量),因为尽管肥胖的患病率存在性别差异94体重可能限制男性和女性之间的体重差异,体重是用于评估药物剂量反应研究的临床测量指标,并在医疗保健机构中收集。使用该函数构建模型lme三个月在R包nlme v. 3.1-15395并分别应用于每个表型性状。我们对连续预测器(即权重)应用了大均值居中(gmc);通过这种方式,截取(x= 0)为每一性别提供对体重相似的女性或男性的预测值。应用模型为:
Log(数据点)~ gmc(Log(权重))* sex +(1 |批)+ (gmc(Log(权重))|元数据组)+ (gmc(Log(权重))|亚品系)
随机因子“批”标记了同一天接受手术的一组小鼠(见参考文献)。20.),“元数据组”表示程序参数发生变化的情况(例如,不同的仪器、不同的观察者和不同的设置),strain表示每只小鼠的应变标识符(例如,C57BL/6N)。这三个随机因素加上“权重”随机斜率将减少由于聚类而产生的第I型误差96.此外,为了估计两性之间不同的残差方差,我们建立了组间异方差结构模型,该结构使用lme函数的参数weights = varIdent (form = ~1 | sex)定义。我们分析了一个自定义函数来应用这个模型,使用条件语句来解释随机因素(子品系或元数据组)只有一个唯一项的情况(例如,性状“胫骨长度”的数据只包含品系C57BL/6N)。换句话说,有些性状只有一个亚品系或一个元数据组,在这种情况下,我们不符合相应的随机效应。这一过程产生了2,080,767和363个性状的最终数据集(即,模型对几个性状没有收敛,这些性状被排除在后续分析之外)。
对于每个表型性状,采用R包扫把法提取模型参数(回归系数和方差分量)。混合v.0.2.797,对于男性和女性(斜率,截距,标准误差,斜率SE,截距SE, R2边际,R2条件和剩余方差)和相应的p提取回归系数值,以评估斜率和截距的性别差异的显著性。由于lme函数没有为残差方差(标准差,SDs)的差异提供统计显著性,我们使用了Nakagawa等人开发的方法。98或变异率的对数,通过比较两组间SDs的差异得到p残差SD值(另见Senior等。99).
我们意识到,在363个被研究的性状中,有些性状是强相关的(即,非独立的:例如,来自左右眼的性状以及具有层次聚类和重叠细胞类型的免疫分析)。因此,我们崩溃了p这些相关性状的值为219p值,使用由Zajitschek等人执行的程序(分组相关性状或性状分组)。18.我们采用了Fisher的方法,并对Li和Ji提出的方法进行了调整One hundred.在R包中实现,poolr101,该模型模拟了性状之间的相关性;我们把这个相关性设为0.8。
为了评估小鼠亚毒株在多大程度上解释了我们模型中的变异,我们编写了一个自定义函数来比较我们上面的应用模型,包括亚毒株作为随机因素,与不包括亚毒株的模型。我们提取了模型拟合中的差异(delta, δ),使用赤池信息准则(AIC)进行测量,以及相关的p包含一个以上亚品系的所有性状的值,包括应用模型和不包含亚品系的模型(248个性状)。我们进一步应用了上述去除非独立特征和折叠的方法p值(见ref.)18),对相关性状进行简化数据集(154个性状),并使用δAIC进行相同的模型比较。
静态异速生长假说与异速生长参数的性别偏向
利用从上述模型中提取的参数,我们评估了三种情景(见图1)。1),描述了表型性状值与体重静态异速生长关系中性别差异的形式。对于一个给定的特征,这些是:(a)男性和女性有显著不同的斜率,但共享相似的截距(图。1 a, d), (b)男性和女性的截距差异显著,但斜率相似(图2)。1 b, e), (c)男性和女性的斜率和截距有显著差异(图。1 c、f).此外,我们还评估了性别之间有多少特征在残差SDs中存在显著差异。对于这些分类,我们两者都用了p363个性状和219个合并性状组的值。
对于A-C场景,代表了男性和女性回归斜率和/或截距参数之间的显著差异,以及SDs中性别差异显著的情况,数据被整理成功能分组(如上所列),以评估参数值和方差在表型性状值中是否存在性别偏见,以及在多大程度上存在性别偏见。也就是说,当男性和女性差异显著时,我们统计哪个性别显示了更大的参数值(截距,斜率),并且我们还分别统计了方差幅度更高的性别。结果在一个功能组内汇集表型性状,并使用R包ggplot 2v进行可视化。3.3.5102用于场景A-C,产生一组参数值的比较,一组方差(SD)值的比较。我们应该强调的是,我们只使用了包含363个性状的数据集,因为一旦性状合并,一些性状值的方向性就变得毫无意义了,尽管合并了p价值观是有意义的p价值观是没有方向性的(例如,花时间在光明的一面或黑暗的一面)。
斜率、截距和SD残差差异的meta分析
我们意识到我们的分类方法使用p价值观类似于投票计数,它有局限性103.因此,我们使用以下效应量进行了正式的元分析:(1)截距之间的差异(自然对数尺度上男性和女性的特征均值),(2)斜率之间的差异(对数-对数尺度上),以及(3)使用相应SE或更准确地说,SE的平方作为抽样方差的残差SDs之间的差异(这种效应量的细节可以在其他地方找到98,99).前两个效应量及其抽样误差方差由上述混合模型的回归系数及其误差方差得到。我们注意到,男性和女性拦截之间的差异相当于对数响应比(lnRR)。104这表明了两组之间的相对差异(注意截距差异表示男性和女性处于平均人群体重时的差异)。因为这两种类型的效应大小都是在与自然对数相关的尺度上,所以它们可以在不同的特征之间进行比较。此外,我们计算科恩的d,每个性状的标准化平均差(SMD)的常见估计量,以及lnRR。计算SMD以说明男性和女性的平均性状值差异的大小,采用SMD值的标准基准,即小效应= 0.2,中等效应= 0.5,大效应= 0.8d).
我们在这项研究中的主要兴趣是,在不考虑效应大小方向性的情况下,男性和女性在截距、斜率和残差sd方面是否存在差异。因此,我们对均值和抽样方差应用变换进行了幅度的元分析,假设遵循折叠正态分布(eq. 8)105)计算,计算公式如下:
在哪里φ\ (\ \)是标准正态累积分布函数和ES折叠和SE折叠分别为变换后的效应量(点估计)和抽样方差,ES和SE为变换前对应的点估计和抽样方差。除了这三种效应量外,我们还荟萃分析了另一种效应量,即由边际R量化的模型拟合2(由固定效应计算的方差;在我们的例子中,体重、性别和它们的相互作用)。边际R2数值平方根转换为相关值,类似于观察到的性状值与模型预测值之间的相关性(基于固定效应)。然后,我们将这个相关值转换为Fisher的Zr,以便我们可以计算基于样本量的抽样方差(参见补充材料结果)。
莫105已经表明,使用这种折叠变换(绝对值效应大小)的元分析方法几乎不偏倚。因此,使用rma直接对这些转换后的变量进行元分析。R包中的mv函数,metfor106.截距模型(元分析模型)有三个随机因素:(1)功能组,(2)特征组和(3)效应量标识符(相当于元分析模型中的残差)107),而在元回归模型中,我们拟合官能团作为调节因子(见图。3.).三种效应量的模型结构完全相同。我们报告了参数估计和95%置信区间CI和95%预测区间PI,它们被可视化为果园图(类似于小提琴图)108)使用R包,orchaRd109.在荟萃分析中,95% PI代表了异质性的程度,以及未来研究的效应大小的可能范围。当95% CI不跨越零时,我们认为估计具有统计学意义。
斜率、截距、残差SDs和模型拟合之间的相关性
我们还使用R包brms中实现的贝叶斯四变量元分析模型,量化了四个效应量之间的相关性110.使用函数brm拟合功能分组为固定效应,拟合性状分组为随机效应。值得注意的是,我们有log变换后的ES折叠和Zr,也变换了SE折叠和SE为Zr使用delta方法(例如,111),然后将效应大小拟合到模型中。我们通过设置两个链、1000次预热和4000次迭代对所有估计参数施加默认先验。我们用Gelman-Rubin统计量评估了链的收敛性112,对于所有链都是1(即,意味着它们都是收敛的),我们还检查了后验样本的所有有效样本量(都超过800)。我们报告了平均估计值(三种效应量和模型拟合之间的相关性)和95%可信区间(CI),如果95% CI不与0重叠,我们认为参数在统计学上显著不同于0。补充资料中提供了Zr的四变量回归,以说明跨功能群的异速拟合的范围和大小,以及与斜率、截距和SD值的关系(补充说明1,补充图。1,补充图。2).
报告总结
有关研究设计的进一步资料,请参阅自然组合报告摘要链接到这篇文章。
数据可用性
本研究生成的源数据已存放在GitHub (https://github.com/itchyshin/mice_allometry).本研究中使用的数据可从Zenodo数据库(https://doi.org/10.5281/zenodo.7336162)91.数据来自国际小鼠表型联盟(IMPC) (www.mousephenotype.org, IMPC数据发布于2019年6月10.1日)。
代码的可用性
在支持信息中提供了一个R Markdown文件,其中包含所有分析的说明和完整的工作流程https://itchyshin.github.io/mice_allometry/.
参考文献
研究中的性别偏见:它如何影响循证医学?报告编号0141-0768 (SAGE出版物,伦敦,英格兰,英国,2007)。
Mogil, J. S. & Chanda, M. L.在疼痛的基础科学研究中纳入女性受试者的案例。疼痛117, 1-5(2005)。
罗杰斯,W. A. & Ballantyne, A. J.将女性排除在临床研究之外:神话还是现实。梅奥中国。Proc。83, 536-542(2008)。
金,a.m.,廷根,C. M. &伍德拉夫,T. K.试验和治疗中的性别偏见必须结束。自然465, 688-689(2010)。
比尔利,A. K.和朱克,I.神经科学和生物医学研究中的性别偏见。>。Biobehav。牧师。35, 565-572(2011)。
克莱因,s.l.等。观点:在基础研究中纳入性驱动发现。国家科学院学报美国112, 5257-5258(2015)。
国家卫生研究院。1993年振兴法案,PL 103-43。grants.nih.gov /资金/资金/ women_min / guidelines_amended_10_2001.htm001.htm(1993)。
Correa-de-Araujo, R.严重差距:缺乏性别/基于性别的研究如何损害健康。J.妇女健康15, 1116-1122(2006)。
Klinge, I.欧洲研究中的性别观点。杂志。Res。58, 183-189(2008)。
Zucker, I. & Beery, A. K.男性仍然主导着动物研究。自然465, 690-690(2010)。
马祖尔,C. M.和琼斯,D. P.二十年了,还在继续:包括女性作为参与者,在生物医学研究中研究性和性别。BMC妇女健康15, 94(2015)。
费尔德曼等人。利用自动数据提取在大规模临床研究中量化性别偏见。JAMA Netw。开放2, e196700-e196700(2019)。
政策:国家卫生研究院在细胞和动物研究中平衡性别。自然509, 282(2014)。
罗森塔尔,N. &布朗,S.小鼠上升:人类疾病模型的前景。细胞生物学。9, 993-999(2007)。
Takao, K. & Miyakawa, T.小鼠模型中的基因组反应极大地模拟了人类炎症疾病。国家科学院学报美国112, 1167-1172(2015)。
激素是动物研究中的“女性问题”吗?科学364, 825-826(2019)。
普伦德加斯特,B. J.,大西,K. G. &朱克,I.雌性小鼠解放,纳入神经科学和生物医学研究。>。Biobehav。牧师。40, 1-5(2014)。
Zajitschek, s.r.k.等。性状变异的性别二态性及其生态进化和统计学意义。eLife9, e63170(2020)。
贝克尔,J. B., Prendergast, B. J. &梁J. W.雌性大鼠并不比雄性大鼠更可变:神经科学研究的元分析。医学杂志。性。是不同的。7, 34(2016)。
卡普,n.a.等人。哺乳动物表型性状中两性二态性的流行。Commun Nat。8, 1-12(2017)。
理查德森,S. S., Reiches, M., Shattuck-Heidorn, H., LaBonte, M. L. & Consoli, T.观点:关注临床前性别差异并不能解决女性和男性的健康差异。国家科学院学报美国112, 13419-13420(2015)。
Zucker, I. & Prendergast, B. J.药代动力学的性别差异预测女性药物不良反应。医学杂志。性。是不同的。11, 32(2020)。
Koren, G., Nordeng, H. & MacLeod, S.药物生物等效性的性别差异:是时候重新思考实践了。中国。杂志。其他。93, 260-262(2013)。
Rathore, s.s.,王,Y. & Krumholz, h.m.地高辛治疗心力衰竭的性别差异。心血管病。j .地中海。347, 1403-1411(2002)。
甘地,M., Aweeka, F.,格林布拉特,R. M. & Blaschke, T. F.药代动力学和药效学中的性别差异。为基础。启杂志。Toxicol。44, 499-523(2004)。
篇章,J. G.等。女性急性冠脉综合征的症状表现:神话与现实。拱门。实习生。地中海。167, 2405-2413(2007)。
惠特利,H. P. &林赛,W.基于性别的药物活性差异。点。Fam公司。医生80, 1254-1258(2009)。
Wallach, J. D., Sullivan, P. G., Trepanowski, J. F., Steyerberg, E. W. & Ioannidis, J. P.随机对照试验中基于性别的亚组差异:来自Cochrane元分析的经验证据。BMJ355, i5826(2016)。
莫维斯-贾维斯,F.等人。Sex和gender:健康、疾病和药物的修饰词。《柳叶刀》396, 565-582(2020)。
性和性别敏感研究呼吁行动小组等。卫生研究中的性与性别:更新政策以反映证据。医学博士J. Aust。21257 - 62。e51(2020).
鲍曼,A,海涅曼,M. J. &法斯,M. M.性激素和人体免疫反应。嗡嗡声。天线转换开关。更新11, 411-423(2005)。
人类体液免疫的两性二态性疫苗。疫苗26, 3551-3555(2008)。
克莱因,S. L. &波兰,G. A.个性化疫苗学:一种尺寸和剂量可能不适合两性。疫苗31, 2599-2600(2013)。
生物医学研究中的性别二态性:对性别分析的呼吁。反式。r . Soc。热带医学。Hyg108, 385-387(2014)。
Mauvais-Jarvis, F. Arnold, A. P. & Reue, K.代谢性别差异临床前研究设计指南。细胞金属底座。25, 1216-1230(2017)。
Mosca, L, Barrett-Connor, E. & Wenger, N. K.心血管疾病预防中的性别/性别差异。循环124, 2145-2154(2011)。
帕勒萨克,A.比林杰,m.h. - u。,Bode, C. & Bode, J. C. Gastric alcohol dehydrogenase activity in man: influence of gender, age, alcohol consumption and smoking in a caucasian population.酒精。酒精。37, 388-393(2002)。
药代动力学和药效学的性别差异。中国。Pharmacokinet。48, 143-157(2009)。
药理学反应的性别差异。Int。启一般。83, 1-10(2008)。
赫胥黎,j.s.相对增长的问题(L.麦克维,1932)。
恒差生长比及其意义。自然114, 895-896(1924)。
Pélabon, C.等。论个体发生与静态异速生长的关系。点。Nat。181, 195-212(2013)。
狄金森,m.e.等人。高通量发现新型发育表型。自然537, 508-514(2016)。
Usui, T., Macleod, m.r., McCann, s.k, Senior, a.m.和Nakagawa, S.变异的元分析表明,在临床前研究中,包含变异提高了可复制性和可推广性。公共科学图书馆杂志。19, e3001009(2021)。
疾病中性别差异的进化。医学杂志。性。是不同的。6, 5(2015)。
莫罗,E. H. & Connallon, T.性别特异性选择对疾病遗传基础的影响。Evolut。达成。6, 1208-1217(2013)。
朱克,普伦德加斯特,B. J.和比尔里,A. K.生物医学研究中普遍忽视性别差异。冷泉港。教谕。医学杂志。14, a039156(2021)。
Buch, T.等人。阶乘设计的好处,重点是在一个实验中包括雌性和雄性动物。J. Mol. Med。97, 871-877(2019)。
Campesi, I., Seghieri, G. & Franconi, F. 2型糖尿病女性和2型糖尿病男性并不小:抗糖尿病药物的性别差异。咕咕叫。当今。杂志。60, 40-45(2021)。
杰克逊,S. E.和切斯特,J. D.个体化癌症药物。Int。j .癌症137, 262-266(2015)。
贾维德,M. & Haleem, a .增材制造在骨科的应用:综述。j .中国。.中国。创伤9, 202-206(2018)。
Heath, A. & Pechlivanoglou, P.个性化医疗时代的优先研究:不明原因异质性的潜在价值。医疗决策。麦。0, 0272989x211072858(2022)。
戴顿,A.等人。打破循环:在雌性大鼠的研究中,动情变化不需要增加样本量。高血压68, 1139-1144(2016)。
阿内加德,m.e.,惠顿,l.a.,亨特,C. &克莱顿,j.a.性别作为一个生物变量:一个五年的进展报告和行动呼吁。J.妇女健康29, 858-864(2020)。
Woitowich, n.c., Beery, A. & Woodruff, T.一项关于生物科学中性别包容的10年随访研究。eLife9, e56344(2020)。
Garcia-Sifuentes, Y. & Maney, D. L.生物科学中性别差异的报告和误报。eLife10, e70817(2021)。
Rawlik, K., Canela-Xandri, O. & Tenesa, a .跨越人类复杂特征光谱的性别特异性遗传结构的证据。基因组医学杂志。17, 1-8(2016)。
Madla, C. M.等。我们来谈谈性别:男性和女性在药物治疗上的差异。药物Del。牧师。175, 113804(2021)。
Watson, S, Caster, O, Rochon, P. a . & den Ruijter, H.报告了女性和男性的药物不良反应:来自半个世纪以来全球收集的个人病例报告的汇总证据。EClinicalMedicine17, 100188(2019)。
杨,L.等。人类肝脏药物代谢和转运基因表达的性别差异。J. Metab药物。Toxicol。3., 1000119(2012)。
Zakiniaeiz, Y., Cosgrove, K. P., Potenza, M. N. & Mazure, C. M.性别平衡:解决临床前研究中的性别差异。耶鲁·j·比尔。地中海。89, 255-259(2016)。
蒋,L.等。循环铁蛋白水平与2型糖尿病风险的性别特异性关联:前瞻性研究的剂量-反应荟萃分析j .中国。性。金属底座。104, 4539-4551(2019)。
范霍夫,女性热需求。Nat,爬。改变5, 1029-1030(2015)。
Regitz-Zagrosek, V. & Kararigas, G.心血管疾病性别差异的机制途径。杂志。牧师。97, 1-37(2017)。
女性有更多的药物不良反应吗?点。j .中国。北京医学。2, 349-351(2001)。
陈,>。et al。生物等效性试验的药代动力学分析:临床药理学和生物药剂学中性别相关问题的意义。中国。杂志。其他。68, 510-521(2000)。
Fadiran, e.o., Zhang, L. in女性用药(Harrison-Woolrych, M.) 41-68(施普林格国际出版,2015)。
格林布拉特,D. J.,哈马茨,J. S. &罗斯,唑吡坦和性别:女性真的有风险吗?j .中国。Psychopharmacol。39, 189-199(2019)。
格林布拉特,D. J.等。舌下给药后唑吡坦药代动力学和药效学的性别差异。j .中国。杂志。54, 282-290(2014)。
Farkas, R. H., Unger, E. F. & Temple, R. Zolpidem和驾驶障碍识别风险人员。心血管病。j .地中海。369, 689-691(2013)。
郭涛,孙文杰,夏德勇,赵丽生。氟康唑在健康成年志愿者体内的药代动力学:种族和性别的影响。j .中国。制药。其他。35, 231-237(2010)。
Jarugula, V.等。体重和性别对阿利斯基伦药代动力学、药效学和降压疗效的影响j .中国。杂志。50, 1358-1366(2010)。
Mak i.w, Evaniew, N. & Ghert, M.迷失在翻译:动物模型和癌症治疗的临床试验。点。j . Transl。Res。6, 114-118(2014)。
钟超,钟旭,徐涛,徐涛,张艳。血清尿酸与脑卒中风险的性别特异性关系:前瞻性研究的剂量-反应meta分析。j。心脏协会。6, e005042(2017)。
Polasek, t.m., Shakib, S. & Rostami-Hodjegan, A.临床医学中的精确给药:现在和未来。克林牧师专家。杂志。11, 743-746(2018)。
Fernández‐Liz, E.等人。确定年龄和性别如何影响西班牙加泰罗尼亚初级卫生保健环境中的处方药使用。Br。j .中国。杂志。65, 407-417(2008)。
头盖骨的表型、遗传和环境形态整合。进化36, 499-516(1982)。
异时性和异速生长:个体发育的进化变化分析。医学杂志。牧师。73, 79-123(1998)。
卡迪尼,A. &波利,P. D.较大的哺乳动物的脸较长,因为头骨形状受到尺寸相关的限制。Commun Nat。4, 2458(2013)。
波尔图,A., de Oliveira, F. B., Shirai, L. T., de Conto, V. & Marroig, G.哺乳动物头骨模块化的进化I:形态整合模式和量级。Evolut。医学杂志。36, 118-135(2009)。
促进对性别差异的理解,以促进生物医学科学的公平和卓越。医学杂志。性。是不同的。1, 1(2010)。
Voje, K. L., Hansen, T. F., Egset, C. K., Bolstad, G. H. & Pélabon, C.异速生长约束和异速生长的演化。进化68, 866-885(2014)。
性选择和异速生长:对证据和观点的批判性重新评估。另一个星球。Int。j . Org。Evolut。61, 838-849(2007)。
埃格塞特,C. K.等。异速测量的人工选择:改变高度而不改变坡度。j . Evolut。医学杂志。25, 938-948(2012)。
Egset, C. K., Bolstad, G. H., Rosenqvist, G. Endler, J. A. & Pelabon, C.孔雀鱼(Poecilia reticulata)异速生长的地理变异。j . Evolut。医学杂志。24, 2631-2638(2011)。
个体发育和系统发育中的异速发育和大小。医学杂志。牧师。41.https://doi.org/10.1111/j.1469-185X.1966.tb01624.x(1966)。
啮齿类动物进化中的异速生长差异。生态。另一个星球。3., 971-984(2013)。
哺乳动物驯化中个体发育异速生长轨迹的演化。进化72, 867-877(2018)。
在个体发生的进化过程中,有些事情正在发生。Bmc Evolut。医学杂志。10.https://doi.org/10.1186/1471-2148-10-221(2010)。
R核心团队。R:统计计算的语言和环境。R统计计算基础.https://www.R-project.org/(维也纳,奥地利,2022)。
中川,S. &威尔逊,L. A. B.小鼠表型性状异速生长的性别差异表明雌性不是鳞片雄性。https://doi.org/10.5281/zenodo.7336162(2022)。
维克汉姆,François, R.,亨利,L., & Müller, K. dplyr:数据操作语法。R包v. 1.0.7(2021)。
纵向数据的随机效应模型。生物识别技术, 963-974(1982)。
坎特,R. &卡巴列罗,B.全球肥胖性别差异:综述。放置减轻。3., 491-498(2012)。
Pinheiro, J. C. & Bates, D. M. nlme:线性和非线性混合效应模型,3.1-153。R核心团队。(2021)。
Schielzeth, H. & Forstmeier, W.超出支持的结论:混合模型中的过度自信估计。Behav。生态。20., 416-420(2009)。
扫帚。混合模型的整理方法v. 0.2.7。(2021)。
中川,S.等。变异的元分析:生态和进化的应用及其外。生态方法。Evolut。6, 143-152(2015)。
资深,a.m., Viechtbauer, W. & Nakagawa, S.对变异元分析的回顾和扩展:变异比的对数系数。Synth >,方法11, 553-567(2020)。
李娟,季林。利用相关矩阵的特征值调整多位点分析中的多重检验。遗传95, 221-227(2005)。
Cinar, O. & Viechtbauer, W.合并独立和相关p值的poolr包。J.统计。101, 1-42(2022)。
韦翰,H。ggplot2:数据分析的优雅图形(斯普林格出版社,2016年版)。
Gurevitch, J., Koricheva, J., Nakagawa, S. & Stewart, G.荟萃分析与研究综合科学。自然555, 175-182(2018)。
赫奇斯,L. V.,古列维奇,J. &柯蒂斯,P. S.实验生态学中反应比率的元分析。生态80, 1150-1156(1999)。
莫里西,M. B.进化参数的量级、差异和变异的元分析。j . Evolut。医学杂志。29, 1882-1904(2016)。
用元for包在R中进行元分析。J.统计。36, 1-48(2010)。
中川,S. & Santos, E. S.生物学元分析的方法问题和进展。Evolut。生态。26, 1253-1274(2012)。
月亮,K.-W。使用Shiny App学习ggplot2191-200(施普林格国际出版社,2016)。
中川,S.等。果园地:为生态学、进化论及其他领域的应用而培育森林地。Synth >,方法12, 4-12(2021)。
营运P.-C。brms:使用Stan的贝叶斯多层模型的R包。J.统计。80, 1-28(2017)。
Nakagawa, S. Johnson, P. C. D. & Schielzeth, H.对广义线性混合效应模型中的决定系数R2和类内相关系数进行了重新审视和扩展。J. R. Soc接口14, 20170213(2017)。
格尔曼,A. &鲁宾,D. B.使用多个序列迭代模拟的推断。统计科学。7, 457-472(1992)。
确认
本研究由澳大利亚研究委员会资助,授予S.N.和M.L. DP200100361,授予l.a.b.w FT200100822。本出版物中报道的研究由欧洲分子生物学实验室核心资金和美国国立卫生研究院国家人类基因组研究所支持,资助号为UM1HG006370。内容仅为作者的责任,并不一定代表美国国立卫生研究院的官方观点。
作者信息
作者及隶属关系
贡献
L.A.B.W.和S.N.设计了这项研究;s.n., L.A.B.W, S.R.K.Z, M.L.和H.H.对数据分析的概念和实施做出了贡献;J.M.对数据采集做出了贡献;l.a.b.w起草了这份手稿,由S.N.和M.L.贡献
相应的作者
道德声明
相互竞争的利益
作者声明没有利益竞争。
同行评审
同行评审信息
自然通讯感谢Rebecca German和其他匿名审稿人对这项工作的同行评审所做的贡献。
额外的信息
出版商的注意施普林格自然对出版的地图和机构从属关系中的管辖权主张保持中立。
权利和权限
开放获取本文遵循知识共享署名4.0国际许可协议(Creative Commons Attribution 4.0 International License),允许以任何媒介或格式使用、分享、改编、分发和复制,只要您对原作者和来源给予适当的署名,提供知识共享许可协议的链接,并注明是否有更改。本文中的图像或其他第三方材料包含在文章的创作共用许可中,除非在材料的信用额度中另有说明。如果内容未包含在文章的创作共用许可协议中,并且您的预期使用不被法定法规所允许或超出了允许的使用范围,您将需要直接获得版权所有者的许可。要查看此许可证的副本,请访问http://creativecommons.org/licenses/by/4.0/.
关于本文

引用本文
威尔逊,l.a.b., Zajitschek, S.R.K, Lagisz, M。et al。小鼠表型性状异速生长的性别差异表明雌性不是鳞片雄性。Nat Commun13, 7502(2022)。https://doi.org/10.1038/s41467-022-35266-6
收到了:
接受:
发表:
DOI:https://doi.org/10.1038/s41467-022-35266-6
