





摘要gydF4y2Ba
在新冠肺炎疫情下,在线教育很重要,但个人家庭在线考试却会以各种方式鼓励学生作弊,尤其是共谋作弊。虽然在保持社交距离期间不可能进行物理监护,但在线监护成本高昂,损害隐私,并可能导致普遍的勾结。在此,我们提出了一种基于优化的远程在线测试反合谋方法,通过最小化合谋增益,可以与其他技术相结合来防止作弊。在预先了解学生能力的情况下,我们的DOT技术优化了问题的顺序,并在同步的时间段将问题分配给学生,相对于传统考试(学生同时收到常见问题),将共谋收益降低了2-3个数量级。我们的DOT理论允许控制共谋增益到一个足够低的水平。我们最近的DOT形式的期末考试很成功,统计测试和考试后调查证明了这一点。gydF4y2Ba
简介gydF4y2Ba
考试对于衡量和提高教育成果至关重要gydF4y2Ba1gydF4y2Ba但一个主要的问题是,许多学生倾向于作弊gydF4y2Ba2gydF4y2Ba,gydF4y2Ba3.gydF4y2Ba.正如麦凯布博士和国际学术诚信中心2002年至2015年的一项研究所表明的那样gydF4y2Ba4gydF4y2Ba在美国,学生作弊现象惊人地普遍,例如,分别有43%、68%和95%的研究生、本科生和高中生承认在作业或考试中作弊。gydF4y2Ba
最近,作弊问题变得越来越严重。为了应对COVID-19大流行,在线学习已成为大多数教育系统的必要和专属gydF4y2Ba5gydF4y2Ba,gydF4y2Ba6gydF4y2Ba.从传统的教育环境硬着陆到“应急”的在线学习模式gydF4y2Ba7gydF4y2Ba创造了各种挑战,例如有限的资源获取gydF4y2Ba8gydF4y2Ba,缺乏经验/技能gydF4y2Ba9gydF4y2Ba,gydF4y2Ba10gydF4y2Ba,对教育质量和效果的关注gydF4y2Ba6gydF4y2Ba,gydF4y2Ba11gydF4y2Ba,以及教育不平等的加剧gydF4y2Ba12gydF4y2Ba.就学习成果的评估而言,保持社交距离直接不利于监督gydF4y2Ba13gydF4y2Ba因为在个人家庭进行的在线测试只会增加作弊的机会gydF4y2Ba14gydF4y2Ba并增加了这样做的诱惑gydF4y2Ba15gydF4y2Ba,gydF4y2Ba16gydF4y2Ba,gydF4y2Ba17gydF4y2Ba.传统上,体罚监考通常被用来抑制作弊。在保持社交距离期间,如何监考在线考试是一个新的挑战gydF4y2Ba6gydF4y2Ba,因为传统的方法没有考虑到大流行gydF4y2Ba14gydF4y2Ba.为防止作弊,学校设计并使用了配备摄像头和相关技术的严格在线监考方法gydF4y2Ba18gydF4y2Ba在疫情期间有效提高学习效果gydF4y2Ba19gydF4y2Ba,gydF4y2Ba20.gydF4y2Ba.有专业的在线监考服务,如TOP HATgydF4y2Ba21gydF4y2Ba(被400多家机构使用),ExamitygydF4y2Ba22gydF4y2Ba和ProctortrackgydF4y2BaTMgydF4y2Ba23gydF4y2Ba(监考过200多万次考试)。他们通过网络摄像头和屏幕视频监控学生,强制全屏模式,并禁止任何内容共享。一些监考公司与学校签订合同,而另一些则向学生收费;例如,ProctorU每次考试收费15美元,而Proctorio终身收费100美元。除了与使用第三方监制软件相关的成本之外,还有对隐私的担忧gydF4y2Ba24gydF4y2Ba,gydF4y2Ba25gydF4y2Ba,gydF4y2Ba26gydF4y2Ba.使作弊问题恶化的是“数字军备竞赛”,即“寻找新的作弊方式需要新的防止作弊的方法”。gydF4y2Ba27gydF4y2Ba.gydF4y2Ba
尽管严格的监督有好处,但也有一种合理的担忧,即使用“如此严厉的措施”直接向我们的学生发出了我们对他们的诚实缺乏信任的信号gydF4y2Ba14gydF4y2Ba.因此,相对于控制远程评估环境,最近开发了OpenProctor系统,该系统从学习者生成的数据中提取写作风格,并将其作为一种行为生物识别技术,利用机器学习验证学生的作者身份gydF4y2Ba28gydF4y2Ba.该方法的平均准确率为93%,显著高于12%的人类性能基线gydF4y2Ba29gydF4y2Ba.不幸的是,这种方法的效用仅限于文本抄袭,不适用于选择题和计算题,而这在大多数科学和工程课程中是必要的gydF4y2Ba15gydF4y2Ba.正如参考文献中提到的。gydF4y2Ba30.gydF4y2Ba由于“数学或基于事实”的课程具有高度的客观性,与主观的“基于写作”的课程相比,在没有监考的情况下保持学术诚信更具挑战性,也经常受到质疑。此外,这种写作风格的识别方法主要集中在考试后阶段,这可能还不够,因为它没有降低作弊的实用性,也不是Fuller等人所质疑的最优。gydF4y2Ba14gydF4y2Ba.(“教师的角色仅仅是抓住和惩罚作弊的学生,还是支持学生完成学业,让他们最终相信,通过努力学习,他们不必诉诸欺骗就能成功?”)gydF4y2Ba
除了这些花哨的技术,传统的在线学习体验也提供了不使用摄像头的技巧和建议,可以整合形成实用的解决方案;例如,随机排序问题,在有限的时间内提出问题gydF4y2Ba31gydF4y2Ba,并从一个大池子中抽取评估问题gydF4y2Ba26gydF4y2Ba,gydF4y2Ba32gydF4y2Ba.gydF4y2Ba
然而,从紧急临时远程评估过渡gydF4y2Ba7gydF4y2Ba有效的传统在线评估需要教育工作者的广泛努力;例如,创建一个大的问题池。题库的大小通常需要很大,以使测试之间的问题重叠可以忽略不计,例如,30个问题的测试需要300个问题的题库,以控制两个学生在3个以下的平均共同问题数(测试问题数的平方除以题库的大小)。gydF4y2Ba15gydF4y2Ba,gydF4y2Ba26gydF4y2Ba.这样的题库非常大,不可能经常更新,因此很容易出现作弊现象,疫情期间网上发布的考题数量迅速增长就是明证。gydF4y2Ba
在这里,我们通过提供基于优化的成本效益和保护隐私的解决方案来解决上述限制,以帮助教育工作者以最小的努力执行有效的远程评估。具体来说,我们的方法强调了以下三个特点:首先,我们的方法是基于优化的,同时最小化作弊的生产力和实用性。作弊背后的两个决策过程模型是众所周知的。gydF4y2Ba33gydF4y2Ba提出了一个包含理性成本收益和“自我概念”效应两个竞争过程的模型。gydF4y2Ba34gydF4y2Ba开发了一个基于激励/压力、合理化和机会的欺诈三角模型。我们的方法大大提高了成本效益比,减少了机会,从而直接引导学生意识到独立完成考试比作弊更有成效。这种对串通行为的遏制独立于监督,并且尊重隐私。其次,我们的方法最小化了问题池的大小;例如,一个测试中问题数量1.5倍的池的大小被发现足以用我们的方法将共谋增益抑制到一个微不足道的水平。相对于简单地通过谷歌搜索就能完成的事实回忆,更小的资料库规模让教育者能够相对容易地设计出他们自己的问题,这需要智力上的努力gydF4y2Ba14gydF4y2Ba,并经常更新问题gydF4y2Ba31gydF4y2Ba而不是直接依赖公开的题库而不改述gydF4y2Ba32gydF4y2Ba哪一种有诱发学术不诚实的高风险gydF4y2Ba35gydF4y2Ba,gydF4y2Ba36gydF4y2Ba,gydF4y2Ba37gydF4y2Ba.显然,由于题库更小,我们的框架鼓励更好地遵守最佳实践。第三,我们的方法主要集中在阻止合谋行为,根据一项基于自我报告的调查研究发现,合谋行为被认为比在线考试中其他类型的作弊行为更受欢迎gydF4y2Ba17gydF4y2Ba后来通过直接测量得到了验证gydF4y2Ba38gydF4y2Ba的调查结果显示,约80%的作弊行为属于合谋,42%的作弊行为是抄袭网络网站,21%的作弊行为是两者兼而有之。还可能存在其他类型的不当行为,例如访问未经授权的来源和合同欺诈,可通过采用现成的技术加以解决;例如,设计开卷问题gydF4y2Ba39gydF4y2Ba,gydF4y2Ba40gydF4y2Ba,gydF4y2Ba41gydF4y2Ba,基于配置文件的认证gydF4y2Ba42gydF4y2Ba挑战性的问题gydF4y2Ba43gydF4y2Ba,gydF4y2Ba44gydF4y2Ba,以及网络视频会议监考。gydF4y2Ba
在接下来的文章中,我们将重点关注我们的方法的关键要素,尽管上述补充策略对于补充我们的方法成为反作弊问题的综合实际解决方案也很重要。我们的方法主要是为“数学或基于事实”的课程设计的,并且与大多数类型的问题兼容,这里用一个基于多项选择题(MCQ)的模型来说明,因为MCQ是流行的、可靠的、有效的和具有成本效益的gydF4y2Ba45gydF4y2Ba,gydF4y2Ba46gydF4y2Ba.我们的主要结果是一个定理,为我们的考试设计提供了合谋增益的上限,在我们的远程在线测试(DOT)平台中反合谋的调度算法,以及我们的DOT考试结果。使用我们的DOT技术,共谋收益可以在实践和理论上变得微不足道,特别是通过结合学生能力的先验知识。共谋增益指的是学生通过共谋提高分数的百分比,能力指的是学生在考试中正确回答问题的个人概率。我们的主要想法是以同步的方式将问题以个体特定的序列优化地交付给学生,这样即使学生自由地在自己之间作弊,他们仍然不能显著提高他们的分数(图2)。gydF4y2Ba1gydF4y2Ba).gydF4y2Ba

假设两个学生相互勾结,其中一个学生可以从另一个学生那里得到另一个学生已经回答过或正在做的问题的答案(参见“方法”)。gydF4y2Ba一个gydF4y2Ba以一个简单的例子来说明这个基于循环的方案,在这个例子中,六个学生参加一个由六个问题组成的考试(gydF4y2Ba米gydF4y2Ba1gydF4y2Ba=gydF4y2Ba米gydF4y2Ba2gydF4y2Ba= 6),每个问题必须在垂直方框所示的分配时间内完成。在不了解学生能力的情况下,该方案可将学生潜在的双向作弊率降低至50%左右;gydF4y2BabgydF4y2Ba如果给作弊的学生提供更多的新问题,作弊的机会就更小了。gydF4y2Ba米gydF4y2Ba1gydF4y2Ba= 4,gydF4y2Ba米gydF4y2Ba2gydF4y2Ba= 6);gydF4y2BacgydF4y2Ba如果学生能力的先验信息是可用的,天真的作业在gydF4y2BabgydF4y2Ba仍然会产生重大的共谋收益;但gydF4y2BadgydF4y2Ba,使用我们的基于分组的反合谋方案,最大和平均合谋收益可以分别急剧降低到~10%和~3%。该方案首先将能力范围划分为gydF4y2Ba米gydF4y2Ba2gydF4y2Ba−gydF4y2Ba米gydF4y2Ba1gydF4y2Ba+ 1个区间,然后将学生适当地分组到这些区间中,最后分别为这些学生组分配相应数量的连续循环序列。该方案的最大合谋增益受定理1的限制。gydF4y2Ba
结果gydF4y2Ba
共谋增益的边界定理gydF4y2Ba
作为一阶近似,我们的分析集中于一个理想化的DOT场景,但我们的分析可以扩展到更一般的设置,没有理论或技术上的困难。在初始DOT设置中,gydF4y2Ba米gydF4y2Ba1gydF4y2Bamcq是从gydF4y2Ba米gydF4y2Ba2gydF4y2Bamcq(例如,为方便起见,具有相同的难度和学分,可以很容易地放宽以进行更准确的分析)提供给一类学生gydF4y2BaNgydF4y2Ba学生,确实有gydF4y2Ba问gydF4y2Ba每题选一题,答对一题。所有gydF4y2BaNgydF4y2Ba学生们有自己的一套gydF4y2Ba米gydF4y2Ba1gydF4y2Ba问题一个个呈现出来,总体上各不相同gydF4y2Ba序列gydF4y2Ba,并被要求同时参加考试。每个学生必须在预定的时间内回答每个问题,并且不能重提以前的问题。这种提问模式在图中得到了例证。gydF4y2Ba1gydF4y2Ba一个。gydF4y2Ba
在对学生串谋行为的实际假设(“方法”)下,我们提出了一种基于分组的反串谋方案(GAS),在对学生能力有先验知识的情况下,将串谋增益控制在任意期望水平以下。一个学生的能力可以很容易地根据他/她的平均绩点(GPA)(粗略的替代品),从早期的测验(更好的指标),和/或考试的第一部分(通过动态规划实现)来评估。一般来说,我们基于分组的方法包括以下三个要素:(1)gydF4y2Ba分组gydF4y2Ba:能力相近的学生被分组,在考试中接受相同顺序的问题;(2)gydF4y2Ba优化gydF4y2Ba:可以在组间复制的问题数量大幅减少(甚至与下一个元素结合到一起为零);(3)gydF4y2Ba增加gydF4y2Ba:问题池可以扩大到问题的数量大于gydF4y2Ba米gydF4y2Ba1gydF4y2Ba.gydF4y2Ba
反合谋考试设计能够有效降低合谋增益,主要原因如下(图2)。gydF4y2Ba1gydF4y2Bab-d):(1)从上到下的最大问题泄漏gydF4y2BaCgydF4y2Ba连续的循环序列可以减少到零,如果gydF4y2Ba米gydF4y2Ba2gydF4y2Ba−gydF4y2Ba米gydF4y2Ba1gydF4y2Ba+ 1≥gydF4y2BaCgydF4y2Ba(补充图。gydF4y2Ba1gydF4y2Ba);(2)通过分组,可以显著减少等额学生人数(组数),使之只使用gydF4y2BaCgydF4y2Ba序列;(3)能力相似的学生在群体内作弊的概率较小,因为他们只能获得很少的共谋收益,但由于共享相同的序列,促进了群体内的共谋。用这个程序,通过制作gydF4y2BaCgydF4y2Ba=gydF4y2Ba米gydF4y2Ba2gydF4y2Ba−gydF4y2Ba米gydF4y2Ba1gydF4y2Ba+ 1足够大,我们可以控制最大个人共谋增益以及低于任何期望水平的平均共谋增益。gydF4y2Ba
在数学上,我们提出了以下定理,显示了与我们的GAS相关的共谋增益的上限(补充说明)gydF4y2Ba1gydF4y2Ba).gydF4y2Ba
定理1gydF4y2Ba
给定的序列gydF4y2Ba米gydF4y2Ba1gydF4y2Ba银行的问题gydF4y2Ba米gydF4y2Ba2gydF4y2BamcqgydF4y2Ba当每个问题的Q个选项中只有一个正确选项时,个体合谋增益的最大值可以控制在不大于(1)gydF4y2Ba−gydF4y2Ba1 / Q) / (MgydF4y2Ba2gydF4y2Ba−gydF4y2Ba米gydF4y2Ba1gydF4y2Ba+gydF4y2Ba1)使用GASgydF4y2Ba.gydF4y2Ba
这个定理在实践中是强大的;例如,根据这个上限,在合理的测试设置下,对于任何大规模的类,理论上都可以将个体合谋增益的最大值控制在3.6%以下gydF4y2Ba米gydF4y2Ba2gydF4y2Ba= 60,gydF4y2Ba米gydF4y2Ba1gydF4y2Ba= 40,gydF4y2Ba问gydF4y2Ba= 4。gydF4y2Ba
期末考试设计的指标gydF4y2Ba
上述定理为共谋控制提供了一个上界,但通常不是最优的,因为它没有充分利用学生的能力知识。基于GAS的结果,可以使用离散优化算法(“方法”)进一步降低合谋增益,以获得最佳的DOT反合谋性能。为此,目标函数需要定义如下。gydF4y2Ba
让我们介绍gydF4y2Ba能力概要gydF4y2Ba的学生gydF4y2BaYgydF4y2Ba= {gydF4y2BaygydF4y2Ba我gydF4y2Ba∈gydF4y2Ba(1 /gydF4y2Ba问gydF4y2Ba1)gydF4y2Ba∣gydF4y2Ba我gydF4y2Ba= 1, 2,…gydF4y2BaNgydF4y2Ba}以非递增的顺序,而agydF4y2Ba勾结矩阵gydF4y2Ba\ (P = {(P {} _ {j,我})}_ {i, j在[N]} \ \)gydF4y2Ba,在那里gydF4y2BapgydF4y2BajgydF4y2Ba,gydF4y2Ba我gydF4y2Ba表示学生的概率gydF4y2Ba我gydF4y2Ba学生串通gydF4y2BajgydF4y2Ba如果gydF4y2Ba我gydF4y2Ba≠gydF4y2BajgydF4y2Ba,gydF4y2BapgydF4y2Ba我gydF4y2Ba,gydF4y2Ba我gydF4y2Ba学生的概率gydF4y2Ba我gydF4y2Ba考试不作弊。gydF4y2BaPgydF4y2Ba是上三角形。给定一个gydF4y2Ba赋值gydF4y2Ba一个gydF4y2Ba= (gydF4y2Ba一个gydF4y2Ba我gydF4y2Ba、……gydF4y2Ba一个gydF4y2BaNgydF4y2Ba),是一个向量,其元素为问题序列(SQs),其中gydF4y2Ba一个gydF4y2Ba我gydF4y2BaSQ是否分配给学生gydF4y2Ba我gydF4y2Ba,平均共谋收益gydF4y2BaggydF4y2Ba总共谋增益是否与班级规模和考试中的问题数相关,并定义为gydF4y2Ba
在{总和gydF4y2Ba⋅gydF4y2Ba}代表所有元素相加的运算,gydF4y2Ba∘gydF4y2Ba表示Hadamard(逐元素)乘法,则gydF4y2Ba能力差异矩阵gydF4y2BaDgydF4y2Ba定义为gydF4y2Ba\ ({{d} _ {j,我})}_ {i, j在[N]} \ \)gydF4y2Ba在哪里gydF4y2Ba(\ d {} _ {j,我}= \马克斯({y} _ {j} - {y} _ {}, 0) \)gydF4y2Ba,以及gydF4y2Ba位置矩阵gydF4y2BaZ \ (Z = {({} _ {j,我})}_ {i, j在[N]} \ \)gydF4y2Ba由gydF4y2Ba一个gydF4y2Ba在哪里gydF4y2BazgydF4y2BajgydF4y2Ba,gydF4y2Ba我gydF4y2Ba表示该学生的问题数gydF4y2Ba我gydF4y2Ba可以欺骗学生gydF4y2BajgydF4y2Ba如果gydF4y2BajgydF4y2Ba≠gydF4y2Ba我gydF4y2Ba,以及特殊情况gydF4y2BazgydF4y2Ba我gydF4y2Ba,gydF4y2Ba我gydF4y2Ba定义为gydF4y2Ba米gydF4y2Ba1gydF4y2Ba.如果所有学生都使用与常规考试场景相同的SQ,而没有共谋预防,则平均共谋增益为gydF4y2Ba
我们开发了DOT平台(补充说明gydF4y2Ba6gydF4y2Ba)整合了反共谋技术和其他在线考试辅助技术,并于2020年4月28日将该平台应用于一门本科生成像课程的期末考试。总共85名本科生中有78人参加了两个分开授课的班级的考试。考试包括gydF4y2Ba米gydF4y2Ba1gydF4y2Ba= 40个问题,分配给每个学生,并安排从池gydF4y2Ba米gydF4y2Ba2gydF4y2Ba= 60个问题,通过应用我们的贪婪算法和启发式构造的勾结矩阵gydF4y2BaPgydF4y2Ba,详见“方法”及“补充说明”gydF4y2Ba4gydF4y2Ba.在考试期间,学生被要求参加WebEx会议,由教师解决任何问题或技术难题(原则上,我们的DOT技术可以与声音在线监考相结合,以提高成绩,但需要额外付费)。学生的能力信息是根据他们在在线授课之前进行的期中考试中的表现来估计的。gydF4y2Ba
优化后的分配使合谋增益降低了几个数量级。在数量上,平均共谋增益从19.23%降低到0.0073%(与传统情况相比降低了三个数量级),最坏情况下的共谋增益为(gydF4y2BaggydF4y2BaWgydF4y2Ba,当每个学生设法达到他/她最大可能的共谋收益时的平均共谋收益;(见“方法”)和最大个人合谋收益(gydF4y2BaggydF4y2Ba心肌梗死gydF4y2Ba,最大可能共谋的最大收益超过所有学生;(见“方法”)分别为0.91%和6.88%。具体来说,我们在以下条件下进行了数值模拟,以估计优化分配下的平均共谋增益:(1)准确gydF4y2BaYgydF4y2Ba和随机gydF4y2BaPgydF4y2Ba,估计gydF4y2BaYgydF4y2Ba被认为是可信的以及共谋的可能性gydF4y2BapgydF4y2Ba凯西,我gydF4y2Ba(gydF4y2BakgydF4y2Ba
为了进一步说明我们的DOT技术的性能,在上述实际案例的设置中,我们进行了数值模拟,假设随机高斯分布能力轮廓与gydF4y2BaμgydF4y2Ba0gydF4y2Ba= (1 + 1/ .gydF4y2Ba问gydF4y2Ba) / 2和gydF4y2BaσgydF4y2Ba0gydF4y2Ba=(1−1/ .gydF4y2Ba问gydF4y2Ba)/6,截断为有意义的[1/ .gydF4y2Ba问gydF4y2Ba, 1]和启发式构造gydF4y2BaPgydF4y2Ba从gydF4y2BaYgydF4y2Ba.我们计算了没有共谋预防的共谋收益gydF4y2BaggydF4y2Ba0gydF4y2Ba并通过优化预防gydF4y2BaggydF4y2Ba每个配置超过500个实例。我们的结果总结在表中gydF4y2Ba1gydF4y2Bab.在这种情况下,可以观察到平均合谋增益的平均值可以在很小的标准差下降低三个数量级,这表明我们的DOT设计在控制合谋增益方面不仅有效而且稳定。我们进一步将学生人数改为四个典型班级的人数gydF4y2BaNgydF4y2Ba= 20到gydF4y2BaNgydF4y2Ba= 500,见表gydF4y2Ba1gydF4y2BaC,平均共谋增益的平均值保持在一个非常小的水平,这意味着我们的方法在处理大范围的类大小方面的实用性。gydF4y2Ba
期末考试分析gydF4y2Ba
我们首先看一下期末考试的成绩,这些成绩用几个直方图来概括。在40道题中,78名学生的分数的归一化分布(零平均值,单位标准)正如预期的那样,是正态分布的近似“钟形曲线”(图2)。gydF4y2Ba2gydF4y2Baa).作为第一次目测对比,我们将期末考试结果的分布与期中考试结果的分布进行对比,期中考试结果在这里作为对照组。为了进行更定量的分析,我们对期中和期末考试的结果进行了标准测试,以确定这两组考试中是否存在任何异常。首先,我们发现这两个样本集都是通过应用安德森-达令检验从正态分布中抽取的gydF4y2Ba47gydF4y2Ba(gydF4y2BapgydF4y2Ba= 0.1570和gydF4y2BapgydF4y2Ba期中和期末样本分别为0.3004)。接下来,我们使用双样本Kolmogorov-Smirnov检验确认两个样本集都来自相同的正态分布gydF4y2Ba48gydF4y2Ba(gydF4y2BapgydF4y2Ba= 0.1574)。作为一个额外的测试,我们应用了双样本gydF4y2BatgydF4y2Ba-test相等方差gydF4y2Ba49gydF4y2Ba并确认两个分布具有相同的均值(gydF4y2BapgydF4y2Ba= 0.7997)。总之,证据并不支持期中和期末考试的分布存在差异的说法,表明传统的物理监考方法(期中)和我们的DOT格式(期末)在同一人群中的评估结果是一致的。gydF4y2Ba

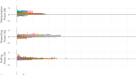
一个gydF4y2Ba期末考试成绩的分布(78名学生,在DOT平台上进行)呈正常的“钟形”分布,与期中考试成绩的分布(社交距离之前)差异不显著,这表明我们的DOT技术在防止串通方面的有效性。gydF4y2BabgydF4y2Ba通过我们优化的问题分配,计算出的最大可能合谋收益的百分比分数的分布严格低于7%。gydF4y2BacgydF4y2Ba左边是一组MCQ的大小与收到这组问题的学生数量的直方图,右边是这个数字与MCQ标签的分布,表明不是所有的学生都收到了相同的问题。gydF4y2BadgydF4y2Ba策划gydF4y2Ba问gydF4y2Ba价值观与比较的数量和问题的数量相比较,以检验共谋导致学生给出的相同错误答案的数量明显更高的假设。因为所有gydF4y2Ba问gydF4y2Ba数值低于0.05的显著性水平,我们认为没有显著的合谋发生。gydF4y2Ba
定量上,学生通过合谋获得的最大增益理论上被设计控制在7%以下(图2)。gydF4y2Ba2gydF4y2Bab).这与不使用我们优化的反合谋技术的75%的最大增益相比有利。值得注意的是,超过90%的学生的最大合谋增益可能低于2%,这巩固了我们技术的有效性。这种方法的一个特点是,不是所有的学生都共用同一个题集,这有助于减少学生之间的串通机会。在每个MCQ的接受者数量方面,只有19个问题分配给所有学生,20个问题分配给不到40名学生(图2)。gydF4y2Ba2gydF4y2Bac)。gydF4y2Ba
根据前面的讨论,利用我们的反合谋考试设计,控制的合谋增益非常小,但仍然不是零。因此,有必要检验是否确实发生了重大共谋。为此,我们考察了以下两个方面:(i)成对学生给出相同错误答案的频率是多少;(ii)前20个问题的平均正确答案数量与后20个问题的平均正确答案数量是否相当。方面(i)的基本原理是,如果没有勾结发生,学生对给出相同错误答案的事件是随机和独立的。我们测试的基本前提是两个学生对MCQ给出相同答案的概率gydF4y2Ba问gydF4y2Ba= 4个选项等于1/4,假设学生的答案是独立的。相反,如果发生重大合谋,这种可能性将显著提高。方面(ii)的基本原理是,正确回答第一个和最后20个问题的概率之间的差异也应该是随机的,如果没有共谋,平均为零。另一方面,考虑到在考试的后半段更有可能出现合谋现象,我们预计后20道题的正确答案会增加。gydF4y2Ba
对于(i)方面,我们使用一组配对测试制定并测试了显著共谋发生的假设gydF4y2Ba50gydF4y2Ba.测试方面假设(i)的结果证实,每个错误发现率对应的值都低于0.05的显著性(图1)。gydF4y2Ba2gydF4y2Bad).因此,经验证据并不支持始终给出相同错误答案的学生对存在异常数量(补充说明)gydF4y2Ba5gydF4y2Ba).为了解决第(ii)方面,我们制定并测试了这样一个假设,即正确回答前20个问题和后20个问题的方法的差异为零。基于78名学生对考试中问题的回答,我们使用非参数Wilcoxon符号秩检验进行配对观察gydF4y2Ba49gydF4y2Ba,产生了一个gydF4y2BapgydF4y2Ba值为0.3133。基于上述证据,我们不能否认前20题和后20题的平均正确答案数是相同的这一假设。换句话说,前20题的平均正确答案数和后20题的平均正确答案数之间的差异在统计学上并不显著。gydF4y2Ba
考试后调查的反馈gydF4y2Ba
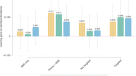
考试后调查表明,使用DOT平台的在线考试受到了大多数学生的好评(图2)。gydF4y2Ba3.gydF4y2Ba).更准确地说,76.9%的学生(图;gydF4y2Ba3.gydF4y2Baa)在从非常不足(1)到非常充分(5)的5分量表中,80.8%的学生将回答问题的持续时间评为3分或以上。gydF4y2Ba3.gydF4y2Bab)在从非常不方便(1)到非常方便(5)的5分制中,对使用平台界面的便利性进行了3分或以上的评价。调查还获得了关于考试问题难度的反馈。接近70%的学生选择“合理”,这是第三个选择(图。gydF4y2Ba3.gydF4y2Bac).在排除极端的“简单”(选项1)和“困难”(选项5)后,96.1%的学生认为问题在可接受的范围内(在2到4之间)。调查最后询问了学生的期末在线考试与他们参加的其他在线考试的相似程度。学生对其他在线考试对我们在线考试观感的熟悉程度的看法显示,在从非常不同(1)到没有不同(5)的5分量表中,约59%的学生回答了3分或以上(图5)。gydF4y2Ba3.gydF4y2Bad).其余41%的学生通过选择选项(1)和(2)表示期末考试的形式与其他考试设置不同。gydF4y2Ba

的条形图摘要gydF4y2Ba一个gydF4y2Ba时隙长度的充分性,gydF4y2BabgydF4y2Ba平台界面方便,gydF4y2BacgydF4y2Ba考试题目的简单性,以及gydF4y2BadgydF4y2Ba分别与其他在线考试相似(美国纽约州特洛伊伦斯勒理工学院提供的本科医学成像课程于2020年4月28日进行)。gydF4y2Ba
讨论gydF4y2Ba
虽然我们的方法仅用mcq来说明,但我们的方法实际上与大多数类型的问题兼容(除了易于编写的类型测试),因为正是优化的SQs抑制了共谋增益。更不用说许多其他类型的问题可以很容易地适应MCQ形式。同样值得注意的是,我们的方法与其他先进技术兼容,如“学习分析”。gydF4y2Ba29gydF4y2Ba,该方法可以集成到我们的基于写作的构造性回答问题的文本抄袭检测方法中。gydF4y2Ba
在上述的考试后调查中,我们收到了学生们关于如何改进dot格式考试设计的建设性意见。具体来说,我们计划让DOT平台更加灵活,这样问题就可以有不同的权重/积分/时间长度,选择的数量和正确选择的数量都可以调整。另一个可能的调整是使用软移动窗口的方法,而不是一次向学生提出一个问题。在软移动窗口内,学生可以在移动时间窗口内处理少量问题并根据需要修改答案。值得注意的是,这种扩展可以在离散优化框架中进行类似的分析,并且不存在任何技术困难。当无法事先了解学生的能力时,在线考试的初始阶段可以用于评估学生的能力水平。接下来是根据估计的能力为考试的剩余部分安排SQs。最后是区块链技术gydF4y2Ba51gydF4y2Ba对于保持问题数据库的机密性(仅对教师开放)和系统地管理学生的个人教育学分高度相关。这些改进和其他改进可以很容易地在我们的优化框架中实现。gydF4y2Ba
最近的一项研究gydF4y2Ba52gydF4y2Ba研究表明,COVID-19可能会持续多年,因为已经发生了数千个突变(例如,SARS-CoV-2蛋白有56%的基因突变),这解释了许多假阴性检测。在过去几天里,美国再次出现了第一波或第二波新诊断病例,感染人数明显增加。因此,由于COVID-19而导致的社交距离和类似政策可能在不久的将来甚至更长的一段时间内仍然存在gydF4y2Ba53gydF4y2Ba.对疫情的积极回应是让在线学习和测试实践进入教育活动的主流,或者至少可以假设在线学习和测试实践在不断改进的同时发挥重要作用。得益于互联网和计算技术,高质量的DOT系统现在是可行的解决方案,可以提供类似的考试结果,具有成本效益,并且不会侵犯学生的隐私。gydF4y2Ba
综上所述,我们提出了一种新型的在线考试反串谋方法,该方法依靠排列空间中的离散优化和学生能力的先验知识来抑制学生之间的串谋行为。结合其他辅助方法,可以达到一般的作弊预防目的。此外,我们还介绍了我们的DOT平台及其成功应用。从理论上、数值上和实验上都证明,使用DOT技术可以经济有效地减少作弊收益,因此在保持社交距离及其他时间内,准确可靠的考试是可行的。gydF4y2Ba
方法gydF4y2Ba
共谋行为的假设gydF4y2Ba
共谋行为的假设如下:gydF4y2Ba
- 1.gydF4y2Ba
作弊是单向的。如果两个学生A和B相互勾结,而A的能力比B强,那么只有B会抄袭A的答案,这被称为B欺骗A, A帮助B。gydF4y2Ba
- 2.gydF4y2Ba
如果A已经在B之前回答了问题,或者他们同时在做这个问题,B就可以从A那里得到答案。因此,A和B的不同相对SQs(我们将“问题序列”简称为SQ)将影响B可以从A复制的问题的数量。gydF4y2Ba
- 3.gydF4y2Ba
每个学生只能欺骗不超过一个学生(“A帮助B”模式);考虑到每道题的时间有限,以及考试中所涉及的压力,B通常只能依靠一个帮手。换句话说,由于B需要帮助,当来自多个帮手的不同输入时,他/她不擅长判断哪个答案是正确的(除非B使用投票策略,这可能对他/她的最终分数有重大影响)。因此,我们认为“A帮助B”模式在这种情况下是合理的。gydF4y2Ba
- 4.gydF4y2Ba
B可以帮助C,同时欺骗A。gydF4y2Ba
- 5.gydF4y2Ba
B欺骗A不会影响D欺骗A;换句话说,一个学生可以帮助多个学生。gydF4y2Ba
- 6.gydF4y2Ba
基于作弊的答案不会进一步传播,以帮助其他学生。这一假设可以通过以下论点来证明:考虑到考试时间有限和压力,B不太可能记住他/她从A抄袭的内容,也没有时间向C提供答案。gydF4y2Ba
对学生能力的估计gydF4y2Ba
在实施社交距离之前,学生的能力是根据他们在期中考试中的表现来评估的。这两个班由不同的老师授课,期中考试也不同,但他们将在同一时间参加同一场期末考试。因此,他们在课堂上的相对表现被视为他们的能力分数,而不是他们的真实分数。首先将两个类别的等级分布归一化为均值为零、单位方差为零的分布,然后进行组合。值得一提的是,没有参加期中考试的学生被排除在归一化程序之外,然后将其放回到带0的组合配置文件中(分配一个平均成绩来估计他们的表现)。最后,将组合归一化分数线性变换到范围[0.25,1],形成能力剖面的先验知识gydF4y2BaYgydF4y2Ba学生的集合。注意,范围[0.25,1]是根据经验选择的。根据我们的经验,每学期我们都能在课堂上回答所有的问题,有几个学生的成绩接近满分,也有几个完全没有准备的学生。此外,启发式共谋矩阵gydF4y2BaPgydF4y2Ba基于能力差异而不是能力值,因此,能力范围的线性变换只会对平均共谋增益施加一个恒定的比例因子gydF4y2BaggydF4y2Ba根据公式(gydF4y2Ba1gydF4y2Ba),不会影响SQ分配的优化结果。gydF4y2Ba
共谋矩阵的构造gydF4y2Ba
为了进行优化,我们启发式地构造了一个合谋矩阵gydF4y2BaPgydF4y2Ba描述每个学生作弊的概率。根据正文的符号,对串通机制进行合理假设:(1)学生的概率gydF4y2Ba我gydF4y2Ba主动作弊与他/她的能力有关gydF4y2BaygydF4y2Ba我gydF4y2Ba;学生1倾向于不作弊,因为他/她不可能获得任何收益(风险大于收益),而学生gydF4y2BaNgydF4y2Ba会想尽一切办法去欺骗,因为他/她总是会获得(收益大于风险)。(2)两个学生A和B之间发生共谋的概率与的差有关gydF4y2BaygydF4y2Ba一个gydF4y2Ba而且gydF4y2BaygydF4y2BaBgydF4y2Ba.学生gydF4y2Ba我gydF4y2Ba欺骗学生1的意愿最强,而欺骗学生1的意愿最小gydF4y2BajgydF4y2Ba如果gydF4y2BaygydF4y2Ba我gydF4y2Ba=gydF4y2BaygydF4y2BajgydF4y2Ba因为他/她无法信任gydF4y2BajgydF4y2Ba超过自己的人,他/她永远不会欺骗自己gydF4y2BajgydF4y2Ba如果gydF4y2BaygydF4y2Ba我gydF4y2Ba>gydF4y2BaygydF4y2BajgydF4y2Ba.gydF4y2Ba
基于上面的假设,共谋矩阵gydF4y2BaPgydF4y2Ba启发式构造如下:gydF4y2Ba
在哪里gydF4y2BangydF4y2BafgydF4y2Ba(gydF4y2Ba我gydF4y2Ba)定义为中的元素数量gydF4y2BaYgydF4y2Ba大于gydF4y2BaygydF4y2Ba我gydF4y2Ba,gydF4y2BaηgydF4y2Ba是一个非负常数,可以用来调节学生的作弊意愿。更大的gydF4y2BaηgydF4y2Ba是否会增加学生串通作弊的概率,并假定学生总是主动作弊gydF4y2BaηgydF4y2Ba=gydF4y2Ba∞gydF4y2Ba(所有优化都是在此设置下进行的)。方程(gydF4y2Ba3.gydF4y2Ba)及(gydF4y2Ba4gydF4y2Ba)定义学生作弊和不作弊状态的概率gydF4y2Ba我gydF4y2Ba分别和处于作弊状态的学生的可能性gydF4y2Ba我gydF4y2Ba会欺骗学生gydF4y2BajgydF4y2Ba是否与他们的能力差异成正比gydF4y2BaygydF4y2BajgydF4y2Ba−gydF4y2BaygydF4y2Ba我gydF4y2Ba由所有可能情况下能力差异的总和归一化。gydF4y2Ba
在不失一般性的前提下,我们进一步假设学生具有不同的能力(gydF4y2BaygydF4y2Ba1gydF4y2Ba>gydF4y2BaygydF4y2Ba2gydF4y2Ba>gydF4y2Ba⋯gydF4y2Ba>gydF4y2BaygydF4y2BaNgydF4y2Ba),因为将微小的差异加到两个相等的事实gydF4y2BaygydF4y2Ba对结果的影响可以忽略不计gydF4y2BaggydF4y2Ba化简表达式gydF4y2BangydF4y2BafgydF4y2Ba(gydF4y2Ba我gydF4y2Ba)的形式gydF4y2Ba
因此,gydF4y2BapgydF4y2BajgydF4y2Ba,gydF4y2Ba我gydF4y2Ba可以写得更明确如下:gydF4y2Ba
注意启发式共谋矩阵gydF4y2BaPgydF4y2Ba表示一个实际合理的优化起始点。我们构建gydF4y2BaPgydF4y2Ba对能力差异较大的学生之间的勾结给予更大的权重,而不是能力差异较小的学生之间的勾结,这有助于限制在最坏情况下的勾结收益。由于模型与实际很可能存在不匹配,任何优化结果都需要进行最坏情况分析。gydF4y2Ba
最坏情况指标分析gydF4y2Ba
类似于计算机科学中的平均案例分析和最坏情况分析,我们可能希望在最坏情况研究中重新审视我们的优化结果,因为模型和实践之间很可能存在不匹配。因此,本文引入了另外两个重要指标,从风控角度评估优化结果,即最坏情况下的平均共谋增益gydF4y2BaggydF4y2BaWgydF4y2Ba定义为在所有学生设法达到他们最大可能的共谋收益(学生最大可能的共谋收益)的情况下的平均共谋收益gydF4y2Ba我gydF4y2Ba是通过设置的概率来实现的gydF4y2Ba我gydF4y2Ba和学生作弊gydF4y2BajgydF4y2Ba1,从谁gydF4y2Ba我gydF4y2Ba在其他的选择中会获得最大的收益吗gydF4y2Ba我gydF4y2Ba),gydF4y2Ba
以及最大的个人共谋收益gydF4y2BaggydF4y2Ba心肌梗死gydF4y2Ba这是所有学生可能获得的最大合谋利益,gydF4y2Ba
ggydF4y2BaWgydF4y2Ba是否可以用来评估优化结果在最坏情况下的表现,是否可以作为给定能力剖面下共谋增益的可靠上限估计gydF4y2BaYgydF4y2Ba由于计算gydF4y2BaggydF4y2BaWgydF4y2Ba不涉及勾结矩阵。gydF4y2BaggydF4y2Ba心肌梗死gydF4y2Ba是一种可以从学生所能获得的最大合谋利益的角度来评估考试公平性的指标。如果在输出分配的最坏情况下计算的共谋增益是不可接受的,则应谨慎使用该结果或只需更改初始化并生成更多解。模型的总体符号和度量在补充表中总结gydF4y2Ba1gydF4y2Ba而且gydF4y2Ba2gydF4y2Ba.gydF4y2Ba
循环贪婪搜索gydF4y2Ba
原则上,应从大小为的所有可能分配的集合中寻找达到最小合谋增益的最优分配gydF4y2BangydF4y2BaNgydF4y2Ba而且gydF4y2BangydF4y2BaSQs池的大小是多少gydF4y2BaPgydF4y2Ba平方gydF4y2Ba.实际上,如果考试中有很多学生和/或很多问题,最优解在计算上是不可行的(似乎NP-hard),因此我们提出以下有效的算法。我们首先将SQs的搜索池缩小到由循环移位生成的序列(让我们将集合表示为gydF4y2BaPgydF4y2BaCSgydF4y2Ba)gydF4y2BaPgydF4y2Ba平方gydF4y2Ba遵循启发式gydF4y2BaPgydF4y2BaCSgydF4y2Ba是一个很好的代表子空间吗gydF4y2BaPgydF4y2Ba平方gydF4y2Ba.gydF4y2BaPgydF4y2BaCSgydF4y2Ba包含所有可能的gydF4y2BazgydF4y2Ba的任意两个序列所获得的值gydF4y2BaPgydF4y2Ba平方gydF4y2Ba,如果我们从两个空间中随机选择两个序列,则期望gydF4y2BazgydF4y2Ba的两个序列的值gydF4y2BaPgydF4y2BaCSgydF4y2Ba比那还小gydF4y2BaPgydF4y2Ba平方gydF4y2Ba(见补充说明)gydF4y2Ba7gydF4y2Ba为了证明)。然后,我们选择从随机初始化的赋值或由GAS结果生成的赋值中使用贪婪搜索算法,重复多次搜索过程,直到损失不减少为止。通过这种贪心搜索,可以在多项式时间内得到满意的结果。gydF4y2Ba
具体来说,我们可以在循环池中执行贪婪搜索(循环贪婪搜索,CGS)。CGS背后的概念是针对每个学生进行迭代,并将他/她当前的问题序列替换为一个gydF4y2BaPgydF4y2BaCSgydF4y2Ba如果更新后的分配达到较小的平均共谋增益。为了完成一个完整的搜索,需要进行几个循环的贪婪搜索,并且在迭代过程中,上一个循环的输出分配将被视为下一个循环的初始化。我们使用GAS的结果作为首选的初始化,同时也建议采用其他初始化,在结果中寻找最优的初始化来改进方案(参见补充说明中的算法2)gydF4y2Ba2gydF4y2Ba获取伪代码和实现细节)。gydF4y2Ba
最小-最大贪婪匹配gydF4y2Ba
而不是在循环池中搜索gydF4y2BaPgydF4y2BaCSgydF4y2Ba,我们可以从整个排列池中搜索gydF4y2BaPgydF4y2Ba平方gydF4y2Ba使共谋收益最小化。由于问题规模较大时在大排列空间中搜索困难,我们采用最小-最大贪婪匹配算法(MMM)在多项式时间内进行搜索。一种自然的方法是从最初的随机分配开始,然后贪婪地根据一定的顺序每次挑选一个学生来改进它,并改进他/她的SQ,以便从所有可能的集合中最小化总增益gydF4y2Ba米gydF4y2Ba1gydF4y2Ba排列的gydF4y2Ba米gydF4y2Ba2gydF4y2Ba.我们提出MMM来贪婪地改进一个作业,并证明计算一个序列来取代一个学生的序列,在一个最小化总增益的作业中,可以通过执行最小权重最大匹配在多项式时间内完成(参见补充说明中的算法3)gydF4y2Ba7gydF4y2Ba有关实现细节)。为了方便起见,我们首先引入一些符号。给出任何gydF4y2Ba年代gydF4y2Ba∈gydF4y2BaPgydF4y2Ba年代gydF4y2Ba问gydF4y2Ba:gydF4y2Ba
- 1.gydF4y2Ba
为每一个gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba],我们定义gydF4y2Ba年代gydF4y2Ba(gydF4y2BajgydF4y2Ba) =gydF4y2BalgydF4y2Ba如果gydF4y2BajgydF4y2Ba出现在gydF4y2BalgydF4y2Ba第Th位gydF4y2Ba年代gydF4y2Ba,gydF4y2Ba年代gydF4y2Ba(gydF4y2BajgydF4y2Ba) = 0否则。gydF4y2Ba
- 2.gydF4y2Ba
为每一个gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba],gydF4y2BaαgydF4y2Ba(gydF4y2Ba年代gydF4y2Ba,gydF4y2BajgydF4y2Ba= 1,如果gydF4y2Ba年代gydF4y2Ba(gydF4y2BajgydF4y2Ba)≥1,且gydF4y2BaαgydF4y2Ba(gydF4y2Ba年代gydF4y2Ba,gydF4y2BajgydF4y2Ba) = 0否则,表示是否问题gydF4y2BajgydF4y2Ba在序列上gydF4y2Ba年代gydF4y2Ba.gydF4y2Ba
- 3.gydF4y2Ba
为每一个gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba),每个gydF4y2BalgydF4y2Ba≤gydF4y2Ba米gydF4y2Ba1gydF4y2Ba,gydF4y2BaβgydF4y2Ba(gydF4y2Ba年代gydF4y2Ba,gydF4y2BajgydF4y2Ba,gydF4y2BalgydF4y2Ba= 1,如果gydF4y2Ba年代gydF4y2Ba(gydF4y2BajgydF4y2Ba)≥1,gydF4y2Ba年代gydF4y2Ba(gydF4y2BajgydF4y2Ba)≤gydF4y2BalgydF4y2Ba,gydF4y2BaβgydF4y2Ba(gydF4y2Ba年代gydF4y2Ba,gydF4y2BajgydF4y2Ba,gydF4y2BalgydF4y2Ba) = 0否则,表示是否问题gydF4y2BajgydF4y2Ba出现在位置上或位置之前gydF4y2BalgydF4y2Ba在序列gydF4y2Ba年代。gydF4y2Ba
- 4.gydF4y2Ba
为每一个gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba),每个gydF4y2BalgydF4y2Ba≤gydF4y2Ba米gydF4y2Ba1gydF4y2Ba,gydF4y2BaγgydF4y2Ba(gydF4y2Ba年代gydF4y2Ba,gydF4y2BajgydF4y2Ba,gydF4y2BalgydF4y2Ba= 1,如果gydF4y2Ba年代gydF4y2Ba(gydF4y2BajgydF4y2Ba)≥gydF4y2BalgydF4y2Ba,gydF4y2BaγgydF4y2Ba(gydF4y2Ba年代gydF4y2Ba,gydF4y2BajgydF4y2Ba,gydF4y2BalgydF4y2Ba) = 0否则,表示是否问题gydF4y2BajgydF4y2Ba出现在位置上或位置之后gydF4y2BalgydF4y2Ba在序列gydF4y2Ba年代gydF4y2Ba.gydF4y2Ba
- 5.gydF4y2Ba
对于任何gydF4y2Ba\(s,s^{\prime} \in {P}_{SQ}\)gydF4y2Ba,以及任何gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba],gydF4y2Ba\(\delta (s,s^{\prime},j)=1\)gydF4y2Ba如果gydF4y2Ba年代gydF4y2Ba(gydF4y2BajgydF4y2Ba1、gydF4y2Ba\ (^ {\ '} (j) > 1 \)gydF4y2Ba,gydF4y2Ba\(s^{\prime} (j)\le s(j)\)gydF4y2Ba,gydF4y2Ba\(\delta (s,s^{\prime},j)=0\)gydF4y2Ba否则表示学生是否被分配gydF4y2Ba年代gydF4y2Ba可以在问题上作弊gydF4y2BajgydF4y2Ba来自被分配的学生gydF4y2Ba\ (^ {\ '} \)gydF4y2Ba.gydF4y2Ba
给定一个实例([gydF4y2BaNgydF4y2Ba]、[gydF4y2Ba米gydF4y2Ba2gydF4y2Ba]、[gydF4y2Ba米gydF4y2Ba1gydF4y2Ba],gydF4y2BaYgydF4y2Ba), MMM通过赋值初始化gydF4y2Ba一个gydF4y2Ba,并继续贪婪地改进gydF4y2Ba一个gydF4y2Ba在gydF4y2BaNgydF4y2Ba轮,一次一个学生,如下gydF4y2Ba我gydF4y2Ba≤gydF4y2BaNgydF4y2Ba、学生gydF4y2Ba我gydF4y2Ba被选中,并且gydF4y2Ba一个gydF4y2Ba我gydF4y2Ba被序列贪婪地取代了gydF4y2Ba年代gydF4y2Ba*gydF4y2Ba这使总收益最小化,或者简单地重申,从平均收益中提供了最大的下降gydF4y2Ba一个gydF4y2Ba.在形式上,gydF4y2Ba
(在哪里gydF4y2Ba年代gydF4y2Ba,gydF4y2Ba一个gydF4y2Ba−gydF4y2Ba我gydF4y2Ba)表示学生的作业gydF4y2Ba我gydF4y2Ba的序列gydF4y2Ba一个gydF4y2Ba我gydF4y2Ba替换为gydF4y2Ba年代gydF4y2Ba.注意,对于任何gydF4y2Ba年代gydF4y2Ba∈gydF4y2BaPgydF4y2Ba平方gydF4y2Ba,两者的平均增益之差(gydF4y2Ba年代gydF4y2Ba,gydF4y2Ba一个gydF4y2Ba−gydF4y2Ba我gydF4y2Ba),gydF4y2Ba一个gydF4y2Ba是从每个问题中获得的差异的总和吗gydF4y2BajgydF4y2Ba出现在序列中gydF4y2Ba年代gydF4y2Ba,如式(gydF4y2Ba11gydF4y2Ba).gydF4y2Ba
我们计算gydF4y2Ba\ ({} ^ {*} = \ arg \ mathop{\分钟}\ limits_ {s \ P{} _{平方}}g ((s,{一}_ {-}))\)gydF4y2Ba通过解决以下最小权值最大匹配问题,将问题匹配到序列中的位置。我们定义了一个加权的完全二部图gydF4y2BaGgydF4y2Ba= ((gydF4y2Ba米gydF4y2Ba1gydF4y2Ba]gydF4y2Ba∪gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba],gydF4y2BaEgydF4y2Ba),每个都有一个节点gydF4y2Ba米gydF4y2Ba1gydF4y2Ba位置,以及每个的节点gydF4y2Ba米gydF4y2Ba2gydF4y2Ba的问题。为每一对一个位置gydF4y2BalgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba1gydF4y2Ba]和问题gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba],我们将边的权值设为增益与问题的差值gydF4y2BajgydF4y2Ba当它出现在位置时gydF4y2BalgydF4y2Ba以及从提问中获得的好处gydF4y2BajgydF4y2Ba正如它出现在gydF4y2Ba一个gydF4y2Ba我gydF4y2Ba, W.R.T.序列gydF4y2Ba一个gydF4y2Ba−gydF4y2Ba我gydF4y2Ba所有其他的学生。很容易看出,解决这个最小权值最大匹配问题分配给学生gydF4y2Ba我gydF4y2Ba用所需的序列gydF4y2Ba米gydF4y2Ba1gydF4y2Ba问题gydF4y2Ba\ ({} ^ {*} = \ arg \ mathop{\分钟}\ limits_ {s \ P{} _{平方}}g ((s,{一}_ {-}))- g arg (a) = \ \ mathop{\分钟}\ limits_ {s \ P{} _{平方}}g ((s,{一}_ {-}))\)gydF4y2Ba.gydF4y2Ba
然后,我们将MMM扩展为MMM-CGS算法,作为MMM和CGS的自然扩展,将初始赋值设置为CGS的输出(在补充说明中修改算法3的第2行)gydF4y2Ba2gydF4y2Ba),并像MMM一样贪婪地改进它。这确保了我们只会改进来自CGS的解决方案(至少没有伤害),这意味着我们的启发式优化方法CGS有潜在的改进空间。gydF4y2Ba
整数线性规划(ILP)gydF4y2Ba
为了获得最佳性能,我们将此设置调整为整数线性规划问题,以指数级的计算代价在置换空间中找到最优分配,如补充说明中的算法4所示gydF4y2Ba2gydF4y2Ba.gydF4y2Ba
我们首先展示算法4的正确性,并且它计算出一个有效的解。考虑一个任意的实例gydF4y2Ba我gydF4y2Ba= ((gydF4y2BaNgydF4y2Ba],gydF4y2Ba米gydF4y2Ba2gydF4y2Ba,gydF4y2Ba米gydF4y2Ba1gydF4y2Ba,gydF4y2BaYgydF4y2Ba),并让gydF4y2Ba一个gydF4y2Ba是算法4在此实例上应用时返回的赋值gydF4y2Ba我gydF4y2Ba.这对任何学生来说都是显而易见的gydF4y2Ba我gydF4y2Ba∈gydF4y2Ba(gydF4y2BaNgydF4y2Ba], (ii)任何问题gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba],则最多有一个值gydF4y2BalgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba1gydF4y2Ba],以致于gydF4y2Ba年代gydF4y2Ba我gydF4y2Ba,gydF4y2BajgydF4y2Ba=gydF4y2BalgydF4y2Ba,否则约束gydF4y2Ba\({\sum}_{j\in [{M}_{1}]}{M}_{i,j,l}=1\)gydF4y2Ba是否违反,以及(ii)为任何职位gydF4y2BalgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba1gydF4y2Ba,但只有一个问题gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba这样的gydF4y2Ba年代gydF4y2Ba我gydF4y2Ba,gydF4y2BajgydF4y2Ba=gydF4y2BalgydF4y2Ba,否则,与(i)一起,约束gydF4y2Ba\({\总和}_ {j \ [{M} _{1}]}{年代}_ {i, j} ={\总和}_ {l中\ [{M} _ {2}]} l \)gydF4y2Ba是违反了。通过算法4的构造很容易看出,每个学生都被分配了gydF4y2Ba米gydF4y2Ba1gydF4y2Ba问题gydF4y2Ba一个gydF4y2Ba在一个有效的序列中。gydF4y2Ba
验证算法4中ILP公式的目标是由变量表示的赋值的分数是很容易的gydF4y2Ba年代gydF4y2Ba我gydF4y2Ba,gydF4y2BajgydF4y2Ba,通过检查每对学生gydF4y2Ba我gydF4y2Ba,gydF4y2BakgydF4y2Ba∈gydF4y2Ba(gydF4y2BaNgydF4y2Ba],并为每个问题gydF4y2BajgydF4y2Ba∈gydF4y2Ba(gydF4y2Ba米gydF4y2Ba2gydF4y2Ba],变量gydF4y2BacgydF4y2Ba我gydF4y2Ba,gydF4y2BakgydF4y2Ba,gydF4y2BajgydF4y2Ba正确指示是否gydF4y2Ba我gydF4y2Ba可以从gydF4y2BakgydF4y2Ba在的问题gydF4y2BajgydF4y2Ba在变量指定的赋值下gydF4y2Ba年代gydF4y2Ba我gydF4y2Ba,gydF4y2BajgydF4y2Ba而且gydF4y2Ba年代gydF4y2BakgydF4y2Ba,gydF4y2BajgydF4y2Ba.gydF4y2Ba
为了证明完备性,验证算法4中每个可能的赋值都是ILP的可行解就足够了。对每个有效的赋值进行检查是很容易的gydF4y2Ba一个gydF4y2Ba,有一种方法可以先给变量赋值gydF4y2Ba年代gydF4y2Ba我gydF4y2Ba,gydF4y2BajgydF4y2Ba对应于中的序列gydF4y2Ba一个gydF4y2Ba,然后以不违反任何约束的方式将ILP公式中的其余变量转换为。gydF4y2Ba
实用指南gydF4y2Ba
GAS本身通常不是最优的,但将其结果作为贪婪算法的初始化,可以保证搜索结果的平均共谋增益的理论界。在我们的仿真中,我们的快速启发式搜索算法CGS的性能接近于使用两种复杂算法MMM和ILP优化的结果(补充说明gydF4y2Ba3.gydF4y2Ba).请注意,我们的CGS方法并不能保证最优的收敛性,并且在理论上与竞争的复杂算法不同。特别是,ILP算法可以找到全局最优,但需要指数级的计算资源。为了设计小规模的在线考试,我们通常更喜欢适当地使用ILP。对于大规模的在线考试,我们通常更喜欢使用多项式复杂度的MMM算法来找到至少一个局部最小值,由我们的GAS和CGS方法的输出初始化。gydF4y2Ba
数据收集和道德监督gydF4y2Ba
我们开发了一个DOT平台(一个web应用程序,所有mcq,详见补充说明gydF4y2Ba4gydF4y2Ba而且gydF4y2Ba6gydF4y2Ba)进行网上测试。考试后的调查是通过SurveyMonkey进行的。我们遵守了所有相关的道德规范。RPI机构审查委员会批准了该研究方案。研究中所有参与者均获得知情同意。gydF4y2Ba
报告总结gydF4y2Ba
有关研究设计的进一步资料,请参阅gydF4y2Ba自然研究报告摘要gydF4y2Ba链接到这篇文章。gydF4y2Ba
数据可用性gydF4y2Ba
我们声明,支持本研究结果的所有数据都已在手稿和补充信息中提供。在经过RPI机构审查委员会的程序后,将应要求提供测试的原始数据。gydF4y2Ba
代码的可用性gydF4y2Ba
本研究的源代码和模拟数据可在Github (gydF4y2Bahttps://github.com/edward1001001/Anticheating_in_DOTgydF4y2Ba).gydF4y2Ba
参考文献gydF4y2Ba
罗迪格,H. L. III,普特南,A. L. &史密斯,M. A.考试的十大好处及其在教育实践中的应用。见:J. P.梅斯特和B. H.罗斯(编)学习和动机心理学:教育中的认知。加州圣地亚哥:爱思唯尔学术出版社,第55卷,p1-36(2011)。gydF4y2Ba
Diekhoff, g.m.等。大学作弊:十年后。gydF4y2Ba>高。建造。gydF4y2Ba37gydF4y2Ba, 487-502(1996)。gydF4y2Ba
10大大学作弊丑闻。gydF4y2Ba商业内幕gydF4y2Ba(2012)。gydF4y2Ba
麦凯布,d.l.,巴特菲尔德,k.d. &特维诺,l.k.。gydF4y2Ba大学作弊:学生为什么作弊,教育者该如何应对gydF4y2Ba(JHU出版社,2012)。gydF4y2Ba
Toquero, C. M. 2019冠状病毒病大流行期间高等教育的挑战和机遇:菲律宾的背景。gydF4y2Ba教师。Res。gydF4y2Ba5gydF4y2Ba, em0063(2020)。gydF4y2Ba
vachopoulos, D. Covid-19:在线教育的威胁还是机遇?gydF4y2Ba高。学习。Commun >,gydF4y2Ba10gydF4y2Ba, 2(2020)。gydF4y2Ba
霍奇斯,C.摩尔,S.洛克,B.信托,T.和邦德,A.紧急远程教学和在线学习的区别。gydF4y2BaEducause审查。gydF4y2Bahttps://er.educause.edu/articles/2020/3/the-difference-between-emergency-remote-teaching-and-online-learninggydF4y2Ba(2020)。gydF4y2Ba
Adnan, M. & Anwar, K. COVID-19大流行期间的在线学习:学生的观点。gydF4y2Baj .教师。Soc。Psychol。gydF4y2Ba2gydF4y2Ba, 45-51(2020)。gydF4y2Ba
Zaharah, Z, Kirilova, g.i.和Windarti, A.冠状病毒爆发对印度尼西亚教学活动的影响。gydF4y2Ba萨拉姆。dan Budaya Syar-igydF4y2Ba7gydF4y2Ba, 269-282(2020)。gydF4y2Ba
Mailizar, M., Almanthari, A., Maulina, S. & Bruce, S.中学数学教师对COVID-19大流行期间电子学习实施障碍的看法:以印度尼西亚为例。gydF4y2Ba数学。科学。抛光工艺。建造。gydF4y2Ba16gydF4y2Ba, em1860(2020)。gydF4y2Ba
在线高等教育:不受炒作周期影响。gydF4y2Baj .经济学。教谕。gydF4y2Ba29gydF4y2Ba, 135-54(2015)。gydF4y2Ba
2019-2020年冠状病毒大流行对教育的影响。gydF4y2BaInt。J.健康偏好Res。gydF4y2Ba5gydF4y2Ba, 31(2020)。gydF4y2Ba
陈,B., Azad, S., Fowler, M., West, M. & Zilles, C.学习作弊:量化分数优势随时间的变化。在gydF4y2Ba第七届ACM会议论文集gydF4y2Ba,虚拟事件,美国,2020年8月12-14日,第197-206页(2020)。gydF4y2Ba
Fuller, R, Joynes, V, Cooper, J, Boursicot, K. & Roberts, T. COVID-19是我们“别无选择”(TINA)加强评估的机会吗?gydF4y2Ba地中海,教。gydF4y2Ba42gydF4y2Ba, 781-786(2020)。gydF4y2Ba
罗,北卡罗来纳州。在线学生评估作弊:不仅仅是抄袭。gydF4y2Ba在线远程学习。管理。gydF4y2Ba7gydF4y2Ba,gydF4y2Bahttps://www.westga.edu/~distance/ojdla/summer72/rowe72.htmlgydF4y2Ba(2004)。gydF4y2Ba
Alessio, h.m., Malay, N., Maurer, K., Bailer, A. J. & Rubin, B.考察监考对在线考试成绩的影响。gydF4y2Ba在线学习。gydF4y2Ba21gydF4y2Ba, 146-161(2017)。gydF4y2Ba
沃森,G. R. & Sottile, J.数字时代的作弊:学生在在线课程中作弊更多吗?gydF4y2Ba在线远程学习。管理。gydF4y2Ba13gydF4y2Ba,gydF4y2Bahttps://www.westga.edu/~distance/ojdla/spring131/watson131.htmlgydF4y2Ba(2010)。gydF4y2Ba
李俊,金瑞杰,朴世勇。& Henning, m.a.在COVID-19大流行期间使用技术防止远程评估中的作弊。gydF4y2Baj .凹痕。建造。gydF4y2Ba1 - 3。gydF4y2Bahttps://doi.org/10.1002/jdd.12350gydF4y2Ba(2020)。gydF4y2Ba
法默,J.,拉克特,G. D.,布劳斯坦,J. J.和科尔,B. K.监考在个性化教学中的作用1。gydF4y2Baj:。Behav。分析的gydF4y2Ba5gydF4y2Ba, 401-404(1972)。gydF4y2Ba
梅迪纳,m.s. & Castleberry, a.n.计算机和笔试的监考策略。gydF4y2Ba点。J.卫生系统药学gydF4y2Ba73gydF4y2Ba, 274-277(2016)。gydF4y2Ba
顶部的帽子。在线监考软件。gydF4y2Bahttps://tophat.com/online-proctoring/gydF4y2Ba(2020)。gydF4y2Ba
Examity。gydF4y2Bahttps://examity.com/gydF4y2Ba(2020)。gydF4y2Ba
Proctortrack。gydF4y2Bahttps://www.proctortrack.comgydF4y2Ba(2020)。gydF4y2Ba
哈威尔,D.在冠状病毒爆发后,大量学校关闭,引发了新一轮学生监控浪潮。gydF4y2Ba华盛顿邮报》gydF4y2Ba1(2020)。gydF4y2Ba
利利,M.,米尔,J. &巴克,T.远程现场监考:初步研究。gydF4y2BaJ.互动媒体教育gydF4y2Ba6gydF4y2Ba, 1-5(2016)。gydF4y2Ba
在研究生商科课程的异步、客观、在线评估中先发制人作弊的综合方法。gydF4y2Ba在线学习gydF4y2Ba20.gydF4y2Ba, 195-209(2016)。gydF4y2Ba
考试焦虑:远程监考是如何把学生吓跑的。gydF4y2Ba边缘gydF4y2Ba29日(2020年)。gydF4y2Ba
Amigud, A., Arnedo-Moreno, J., Daradoumis, T. & Guerrero-Roldan, a.e。开放式监考:一个开放学习环境的学术诚信工具。收录:Barolli L., Woungang I., Hussain o.k.(编者)gydF4y2Ba第九届gydF4y2Ba智能网络与协作系统国际会议gydF4y2Ba瑞尔森大学,加拿大,2017年8月24-26日(数据工程和通信技术课堂讲稿)卷gydF4y2Ba8gydF4y2Ba,施普林格,Heidlberg, p262-273(2017)。gydF4y2Ba
Amigud, A., Arnedo-Moreno, J., Daradoumis, T. & Guerrero-Roldan, a.e。使用学习分析来维护学术诚信。gydF4y2BaInt。Rev. Res. Open Distr. Learn。IRRODLgydF4y2Ba18gydF4y2Ba, 192-210(2017)。gydF4y2Ba
完全异步在线课程作弊的回顾:基于数学或事实的课程视角。gydF4y2Baj .建造。抛光工艺。系统。gydF4y2Ba35gydF4y2Ba, 281-300(2007)。gydF4y2Ba
小克罗斯基,G,埃伦,C. R.和雷伯恩,M. H.在没有监考监督的情况下挫败在线考试作弊。gydF4y2BaJ. Acad.公交车。道德gydF4y2Ba4gydF4y2Ba, 1-7(2011)。gydF4y2Ba
戈尔登,J. &科尔贝克,M.解决在线课程中使用考题库问题时的作弊问题。gydF4y2Baj .账户。建造。gydF4y2Ba52gydF4y2Ba, 100671(2020)。gydF4y2Ba
马扎尔,N.,阿米尔,O. &艾瑞里,D.诚实人的不诚实:自我概念维护理论。gydF4y2Baj .市场。Res。gydF4y2Ba45gydF4y2Ba, 633-644(2008)。gydF4y2Ba
康诺利,J.,兰茨,P. &莫里森,J.使用商业欺诈三角预测商科学生的学术失信行为。gydF4y2BaAELJgydF4y2Ba10gydF4y2Ba, 37(2006)。gydF4y2Ba
Madara, B.等。护理专业学生访问测试库:你的测试安全吗?gydF4y2Baj .孕育。建造。gydF4y2Ba56gydF4y2Ba, 292-294(2017)。gydF4y2Ba
伯恩斯,c.m.,成交!基于网络的拍卖网站刚刚入侵了你的测试银行。gydF4y2Ba护士建造。gydF4y2Ba34gydF4y2Ba, 95-96(2009)。gydF4y2Ba
Cheng, C.和Crumbley, D. L.学生和教授使用出版商测试库及其对公平竞争的影响。gydF4y2Baj .账户。建造。gydF4y2Ba42gydF4y2Ba, 1-16 (2018)gydF4y2Ba
Corrigan-Gibbs, H., Gupta, N., Northcutt, C., Cutrell, E. & Thies, W.在网络环境中阻止作弊。gydF4y2BaACM反式。第一版。嗡嗡声。交互。gydF4y2Ba22gydF4y2Ba, 1-23(2015)。gydF4y2Ba
Golub, E. pc在教室和开卷考试。gydF4y2Ba无处不在gydF4y2Ba2005gydF4y2Ba, 1-1(2005)。gydF4y2Ba
在线评估:多项选择、讨论问题、论文和真实的项目。在gydF4y2Ba第三届社区学院教学年会gydF4y2Ba(夏威夷檀香山卡皮奥拉尼社区学院,1998年)。gydF4y2Ba
Sam, a.h., Reid, m.d. & Amin, A.高风险远程访问开卷考试。gydF4y2Ba地中海,建造。gydF4y2Ba54gydF4y2Ba, 767-768(2020)。gydF4y2Ba
乌拉,肖,H. &利利,M.基于配置文件的在线考试学生认证。在gydF4y2Ba信息社会国际会议(i-Society 2012)gydF4y2Ba英国伦敦,2012年6月25-28日,109-113页。gydF4y2Bahttps://ieeexplore.ieee.org/abstract/document/6285058gydF4y2Ba(2012)。gydF4y2Ba
Bailie, J. L. & Jortberg, m.a.在线学习者认证:验证在线用户的身份。gydF4y2Ba在线学习。教书。gydF4y2Ba5gydF4y2Ba, 197-207(2009)。gydF4y2Ba
Ullah, A., Xiao, H., Lilley, M. & Barker, T.在在线考试中使用挑战问题进行学生认证。gydF4y2BaInt。j . InfonomicsgydF4y2Ba5gydF4y2Ba, 9(2012)。gydF4y2Ba
选择题和简答题对延迟记忆学习的影响。gydF4y2Baj .抛光工艺。建造。gydF4y2Ba6gydF4y2Ba, 32-44(1994)。gydF4y2Ba
Abdel-Hameed, A. A., Al-Faris, E. A., Alorainy, I. A. & Al-Rukban, m.o. .健康专业环境中良好选择题的标准和分析。gydF4y2Ba沙特医科大学。gydF4y2Ba26gydF4y2Ba, 1505-1510(2005)。gydF4y2Ba
安德森,T. W. &达林,D. A.基于随机过程的某些“拟合优度”准则的渐近理论。gydF4y2Ba安。数学。统计gydF4y2Ba23gydF4y2Ba, 193-212(1952)。gydF4y2Ba
道奇,Y。gydF4y2BaKolmogorov-Smirnov测试gydF4y2Ba.见:《简明统计百科全书》283-287(施普林格,纽约,2008)。gydF4y2Ba
Montgomery, d.c. & Runger, g.c.。gydF4y2Ba工程师应用统计与概率gydF4y2Ba第四版(威利,2007)。gydF4y2Ba
威尔科克斯,r.r.gydF4y2Ba稳健估计与假设检验导论gydF4y2Ba(文献出版社,2011)。gydF4y2Ba
Underwood, s.b区块链超越比特币。gydF4y2BaCommun。ACMgydF4y2Ba59gydF4y2Ba, 15-17(2016)。gydF4y2Ba
王锐,细泉,尹志刚,魏国伟。解码SARS-CoV-2 t的传播、进化及其对COVID-19诊断、疫苗和药物的影响。gydF4y2Baj .化学。正无穷。模型。gydF4y2Ba60gydF4y2Ba, 5853-5865(2020)。gydF4y2Ba
Kissler, S. M., Tedijanto, C., Goldstein, E., Grad, Y. H. & Lipsitch, M. SARS-CoV-2在大流行后时期的传播动态预测。gydF4y2Ba科学gydF4y2Ba368gydF4y2Ba, 860-868(2020)。gydF4y2Ba
作者信息gydF4y2Ba
作者及隶属关系gydF4y2Ba
贡献gydF4y2Ba
概念化:g.w., m.l., h.m., L.X.;方法论:m.l., s.s., L.X, uk, G.W.;软件和网络:L.L.和H.S.;数据管理:N.I.N, s.g.和M.L.;统计分析:M.K.和U.K.;项目管理:g.w.、h.m.和L.X.;写作和编辑:全部。gydF4y2Ba
相应的作者gydF4y2Ba
道德声明gydF4y2Ba
相互竞争的利益gydF4y2Ba
g.w., m.l., L.X和S.S.对所提出的技术有一项正在申请的专利。gydF4y2Ba
额外的信息gydF4y2Ba
出版商的注意gydF4y2Ba施普林格自然对出版的地图和机构从属关系中的管辖权主张保持中立。gydF4y2Ba
补充信息gydF4y2Ba
权利和权限gydF4y2Ba
开放获取gydF4y2Ba本文遵循知识共享署名4.0国际许可协议(Creative Commons Attribution 4.0 International License),允许以任何媒介或格式使用、分享、改编、分发和复制,只要您对原作者和来源给予适当的署名,提供知识共享许可协议的链接,并注明是否有更改。本文中的图像或其他第三方材料包含在文章的创作共用许可中,除非在材料的信用额度中另有说明。如果内容未包含在文章的创作共用许可协议中,并且您的预期使用不被法定法规所允许或超出了允许的使用范围,您将需要直接获得版权所有者的许可。要查看此许可证的副本,请访问gydF4y2Bahttp://creativecommons.org/licenses/by/4.0/gydF4y2Ba.gydF4y2Ba
关于本文gydF4y2Ba

引用本文gydF4y2Ba
李,M,罗,L, Sikdar, S。gydF4y2Baet al。gydF4y2Ba优化了社交距离期间在线考试的合谋预防。gydF4y2Banpj科学。学习。gydF4y2Ba6gydF4y2Ba, 5(2021)。https://doi.org/10.1038/s41539-020-00083-3gydF4y2Ba
收到了gydF4y2Ba:gydF4y2Ba
接受gydF4y2Ba:gydF4y2Ba
发表gydF4y2Ba:gydF4y2Ba
DOIgydF4y2Ba:gydF4y2Bahttps://doi.org/10.1038/s41539-020-00083-3gydF4y2Ba
这篇文章被引用gydF4y2Ba
应急远程教学时期在线评估系统的发展趋势gydF4y2Ba
智能学习环境gydF4y2Ba(2022)gydF4y2Ba
诚信文化——covid - 19期间机构对诚信的应对gydF4y2Ba
国际教育诚信杂志gydF4y2Ba(2022)gydF4y2Ba
