







摘要gydF4y2Ba
阅读和写作是至关重要的生活技能,但大约十分之一的儿童患有阅读障碍,这种情况可能会持续到成年。阅读障碍的家庭研究表明遗传率高达70%,但很少有令人信服的遗传标记被发现。在这里,我们对51800名自我报告阅读障碍诊断的成年人和1087070名对照组进行了全基因组关联研究,并确定了42个独立的全基因组显著位点:15个与认知能力/教育程度相关的基因,27个新的和可能更特定于阅读障碍的基因。我们在具有中国和欧洲血统的独立队列中验证了23个基因座(13个新的)。阅读障碍的遗传病因在两性之间是相似的,并且与许多特征的遗传协方差被发现,包括双语性,但没有语言相关电路的神经解剖学测量。阅读障碍多基因评分解释了高达6%的阅读特征方差,并可能在未来有助于阅读障碍的早期识别和补救。gydF4y2Ba
主要gydF4y2Ba
阅读能力对于在学校取得成功以及获得就业、信息、保健和社会服务至关重要,并与所获得的社会经济地位有关gydF4y2Ba1gydF4y2Ba.阅读障碍是一种以严重阅读困难为特征的神经发育障碍,根据诊断标准,有5-17.5%的人患有阅读障碍gydF4y2Ba2gydF4y2Ba,gydF4y2Ba3.gydF4y2Ba.它通常涉及受损的语音处理(单词中声音单位或音素的解码),并经常与精神疾病和其他发育障碍同时发生gydF4y2Ba4gydF4y2Ba,尤其是注意力缺陷多动障碍(ADHD)gydF4y2Ba5gydF4y2Ba,gydF4y2Ba6gydF4y2Ba以及言语障碍gydF4y2Ba7gydF4y2Ba,gydF4y2Ba8gydF4y2Ba.阅读障碍可能代表了阅读能力连续统一体的低极端,这是一种复杂的多因素特征,遗传率估计在40%到80%之间gydF4y2Ba9gydF4y2Ba,gydF4y2Ba10gydF4y2Ba.识别遗传风险因素不仅有助于加深对生物学机制的理解,而且还可能扩大诊断能力,促进更早地识别易患阅读障碍和并发疾病的个体,以获得具体支持。gydF4y2Ba
以前对阅读障碍的全基因组研究仅限于受影响家庭的连锁分析gydF4y2Ba11gydF4y2Ba或谦虚(gydF4y2BangydF4y2Ba< 2300例)诊断为儿童和青少年的关联研究gydF4y2Ba12gydF4y2Ba.来自连锁研究的候选基因显示不一致的复制,尽管全基因组关联研究(GWAS)没有发现显著的关联gydF4y2BaLOC388780gydF4y2Ba和gydF4y2BaVEPH1gydF4y2Ba在基因测试中得到了支持gydF4y2Ba12gydF4y2Ba.更大的群体对于提高检测小影响的新遗传关联的敏感性至关重要。在这里,我们展示了迄今为止最大的阅读障碍GWAS, 51800名成年人自我报告了阅读障碍诊断,1087070名对照组,他们都是个人遗传学公司23andMe, Inc.的研究参与者。我们在独立的队列中验证了我们的关联发现,提供了重要变异(主要是单核苷酸多态性(SNPs))和潜在致病基因的功能注释,并估计了基于snp的遗传力。最后,我们研究了与阅读和相关技能、健康、社会经济和精神病学措施的遗传相关性,并在我们强有力的结果中评估了先前涉及阅读障碍候选基因的证据。gydF4y2Ba
结果gydF4y2Ba
全基因组关联gydF4y2Ba
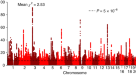
完整的数据集包括51,800名参与者(21,513名男性,30,287名女性)对“你是否被诊断患有阅读障碍”的问题回答“是”。(病例)和1,087,070名(446,054名男性,641,016名女性)参与者回答“否”(对照组)。参与者年龄在18岁或以上(病例和对照组的平均年龄分别为49.6岁(s.d. 16.2)和51.7岁(s.d. 16.6))。我们确定了42个独立的全基因组显著相关位点(gydF4y2BaPgydF4y2Ba< 5 × 10gydF4y2Ba−8gydF4y2Ba)和64个具有提示意义的基因座(gydF4y2BaPgydF4y2Ba< 1 × 10gydF4y2Ba−6gydF4y2Ba)(图。gydF4y2Ba1gydF4y2Ba及补充表gydF4y2Ba1gydF4y2Ba).基因组膨胀适中(gydF4y2BaλgydF4y2BaGCgydF4y2Ba= 1.18),且符合多基因性(见Q-Q图,扩展数据图。gydF4y2Ba1gydF4y2Ba).我们还进行了性别特异性GWAS和年龄特异性GWAS(小于或大于55岁),因为我们的年轻参与者(20- 30岁为5.34%)的阅读障碍患病率高于老年参与者(80- 90岁为3.23%)。这些子样本分析显示了与主GWAS(全样本)的高度一致性。遗传相关性经连锁不平衡(LD)评分回归(LDSC)估计为0.91(95%可信区间(CI): 0.86-0.96;gydF4y2BaPgydF4y2Ba= 8.26 × 10gydF4y2Ba−253gydF4y2Ba), 0.97 (95% CI: 0.91-1.02;gydF4y2BaPgydF4y2Ba= 2.32 × 10gydF4y2Ba−268gydF4y2Ba)年轻人和老年人之间。gydF4y2Ba

的gydF4y2BaygydF4y2Ba轴表示−loggydF4y2Ba10gydF4y2BaPgydF4y2Ba在51,800名个体和1,087,070名对照组中,snp与自我报告的阅读障碍诊断的相关性价值。全基因组显著性的阈值(gydF4y2BaPgydF4y2Ba< 5 × 10gydF4y2Ba−8gydF4y2Ba)由一条水平灰线表示。42个全基因组显著位点的全基因组显著变异体为红色。位于彼此之间小于250kb距离内的变异被认为是一个位点。gydF4y2Ba
在女性GWAS的17个全基因组显著变异中(扩展数据图。gydF4y2Ba2gydF4y2Ba),除4个(rs61190714, rs4387605, rs12031924和rs57892111)外,其余均在主要GWAS中显著,其中3个在LD中具有接近显著的SNP (gydF4y2BaPgydF4y2Ba< 3.3 × 10gydF4y2Ba−7gydF4y2Ba或者更小)。基因间SNP rs57892111(位于gydF4y2BaTFAP2BgydF4y2Ba和gydF4y2BaPKHD1gydF4y2Ba在染色体6p上)并不在主要分析的显著或暗示性snp中,因此可能代表女性特有的变异。现有的GWAS没有证据表明该SNP与任何其他人类特征相关。在男性GWAS的六个全基因组显著变异中(扩展数据图。gydF4y2Ba3.gydF4y2Ba),在主要GWAS中均显著。gydF4y2Ba
在主要GWAS中,除rs5904158在Xq27.3位点外,所有显著变异均为常染色体(区域关联图见补充图)。gydF4y2Ba1gydF4y2Ba).在NHGRI GWAS目录中,共有17个指数变异体具有高LD,并发表了(全基因组显著性)相关snpgydF4y2Ba13gydF4y2Ba(15个与认知/教育特征相关;补充表gydF4y2Ba1gydF4y2Ba和gydF4y2Ba2gydF4y2Ba).因此,共有27个相关位点显示,没有证据表明已发表的全基因组与预期与阅读障碍重叠的特征(例如,教育程度,认知能力)存在关联,并被认为是新的(表2)gydF4y2Ba1gydF4y2Ba).gydF4y2Ba
在38个相关位点(其余4个由验证队列中不可用的indels标记)中,3个(rs13082684, rs34349354和rs11393101)在bonferroni校正水平上显著(gydF4y2BaPgydF4y2Ba< 0.05/38)在GenLang联合GWAS阅读meta分析(gydF4y2BangydF4y2Ba= 33,959)和拼写(gydF4y2BangydF4y2Ba= 18,514)能力gydF4y2Ba14gydF4y2Ba.在gydF4y2BaPgydF4y2Ba< 0.05, GenLang组相关18例,NeuroDys病例对照GWAS组相关3例gydF4y2Ba12gydF4y2Ba(gydF4y2BangydF4y2Ba= 2274例),中文阅读研究(CRS)的阅读准确性和流畅性(gydF4y2BangydF4y2Ba= 2270;gydF4y2Ba补充说明gydF4y2Ba)(表gydF4y2Ba1gydF4y2Ba及补充表格gydF4y2Ba3.gydF4y2Ba- - - - - -gydF4y2Ba6gydF4y2Ba).gydF4y2Ba
基于基因的测试确定了173个显著相关基因(补充表gydF4y2Ba7gydF4y2Ba),但没有显著丰富的生物通路(补充表gydF4y2Ba8gydF4y2Ba).我们估计LDSC负债尺度snp的阅读障碍遗传力为gydF4y2BahgydF4y2Ba2gydF4y2Ba单核苷酸多态性gydF4y2Ba= 0.152(标准误差= 0.006),使用23andMe样本患病率为5%,并且gydF4y2BahgydF4y2Ba2gydF4y2Ba单核苷酸多态性gydF4y2Ba= 0.189(标准误差= 0.008),使用10%的阅读障碍患病率,这在普通人群中更典型gydF4y2Ba2gydF4y2Ba,gydF4y2Ba3.gydF4y2Ba.gydF4y2Ba
精细映射和函数注释gydF4y2Ba
在可信变量集内(补充表gydF4y2Ba1gydF4y2Ba),误读变异是最常见的编码变异(55%);扩展数据图gydF4y2Ba4gydF4y2Ba总结所有预测的变异效应。通过SIFT(从耐受性到不耐受性的分类)评分来预测有害变异gydF4y2BaR3HCC1LgydF4y2Ba,gydF4y2BaSH2B3gydF4y2Ba,gydF4y2BaCCDC171gydF4y2Ba,gydF4y2BaC1orf87gydF4y2Ba,gydF4y2BaLOXL4gydF4y2Ba,gydF4y2BaDLATgydF4y2Ba,gydF4y2BaALG9gydF4y2Ba和gydF4y2BaSORT1gydF4y2Ba.在可信的变异集中,没有基因对功能变异特别不耐受(最小LoFtool(功能丧失)百分位为0.39)。对于42个相关位点,每个位点最可能的基因靶点由OpenTargets的总体V2G(变体到基因)评分来估计(补充表)gydF4y2Ba9gydF4y2Ba).两个索引变体(错义变体rs12737449 (gydF4y2BaC1orf87gydF4y2Ba)及rs3735260 (gydF4y2BaAUTS2gydF4y2Ba)可能是因果关系,因为根据Kircher等人的说法,他们结合了注释依赖损耗(CADD)评分,提示对基因功能有害。gydF4y2Ba15gydF4y2Ba(补充表gydF4y2Ba10gydF4y2Ba).的gydF4y2BaAUTS2gydF4y2Ba变异RegulomeDB rank为2b表示调控作用;它的染色质状态支持转录起始位点的位置gydF4y2Ba16gydF4y2Ba,gydF4y2Ba17gydF4y2Ba.gydF4y2Ba
在MAGMA全基因组基因基础测试中获得的173个显著基因中(见补充表)gydF4y2Ba11gydF4y2Ba), 129个可以进行功能注释(补充表gydF4y2Ba12gydF4y2Ba).蛋白质编码和非编码序列在大约四分之三的这些基因中是积极保守的,63%对变异的不耐受性高于平均水平,33%对功能丧失突变不耐受性。对一般组织和13个脑组织的基因特性分析证实了大脑和特定大脑区域的重要性(补充表)gydF4y2Ba13gydF4y2Ba和gydF4y2Ba14gydF4y2Ba).基于基因测试的173个重要基因中有125个的脑表达水平可以在FUMA中绘制,并显示在补充表中gydF4y2Ba15gydF4y2Ba.共有20个基因表现出较高的一般脑表达水平,其中3个(gydF4y2BaPPP1R1B, NPM1gydF4y2Ba和gydF4y2BaWASF3gydF4y2Ba)位于显著SNP关联附近。在评估的12个大脑区域中,基因表达通常在小脑半球、小脑和大脑皮层最高,与基因性质分析的结果一致。gydF4y2Ba
分区的遗传gydF4y2Ba
功能注释划分的阅读障碍的snp遗传力显示保守区和H3K4me1聚类显著富集(补充表gydF4y2Ba16gydF4y2Ba和扩展数据图。gydF4y2Ba5gydF4y2Ba).在额叶皮层、皮层和前扣带皮层表达的基因富集(gydF4y2BaPgydF4y2Ba< 4.17 × 10gydF4y2Ba−3gydF4y2Ba)(补充表格gydF4y2Ba17gydF4y2Ba和扩展数据图。gydF4y2Ba6gydF4y2Ba),但不包括脑细胞类型(补充表格)gydF4y2Ba18gydF4y2Ba和扩展数据图。gydF4y2Ba7gydF4y2Ba).在多个中枢神经系统(CNS)组织中,增强子和启动子区域分别通过H3K4me1和H3K4me3染色质标记进行富集(补充表)gydF4y2Ba19gydF4y2Ba和gydF4y2Ba20.gydF4y2Ba和扩展数据图。gydF4y2Ba8gydF4y2Ba和gydF4y2Ba9gydF4y2Ba).阅读是口语的一个分支,是人类特有的特征,但在过去3000万到5万年之间,与人类进化有关的一系列注释并没有得到丰富gydF4y2Ba18gydF4y2Ba(补充表gydF4y2Ba21gydF4y2Ba).gydF4y2Ba
遗传相关性和LDSCgydF4y2Ba
估计了98个性状的遗传相关性(图2)。gydF4y2Ba2gydF4y2Ba及补充表gydF4y2Ba22gydF4y2Ba),包括阅读和拼写测量,来自GenLang(图。gydF4y2Ba3.gydF4y2Ba),以及大脑皮层下结构体积,总皮层表面积和厚度,这些数据来自通过meta分析(ENIGMA)增强神经成像遗传学联盟。共有63个性状在bonferroni校正显著性阈值(gydF4y2BaPgydF4y2Ba< 0.05/98;无花果。gydF4y2Ba2gydF4y2Ba).遗传相关性(gydF4y2BargydF4y2BaggydF4y2Ba),定量阅读和拼写测量的范围为−0.70至−0.75(最低95% CI为−0.60,最高95% CI为−0.86),音素意识和非单词重复测量的范围分别为−0.62 (95% CI:−0.50,−0.74)和−0.45 (95% CI:−0.26,−0.64)。儿童/青少年表现(非语言)智商(IQ)gydF4y2BargydF4y2BaggydF4y2Ba较低(−0.19;95% CI:−0.08,−0.30)高于成人言语-数字推理gydF4y2Ba19gydF4y2Ba(−0.50;95% CI: - 0.45, - 0.55),但与儿童智商相似gydF4y2Ba20.gydF4y2Ba(−0.32;95% ci:−0.21,−0.43)和教育程度gydF4y2Ba21gydF4y2Ba(−0.22;95% ci:−0.15,−0.29)。表现积极的特质gydF4y2BargydF4y2BaggydF4y2Ba包括涉及重体力劳动的工作gydF4y2Ba21gydF4y2Ba(0.40;(95% CI: 0.34, 0.45))、工作/职业资格gydF4y2Ba21gydF4y2Ba(0.50;95% ci: 0.41, 0.59), adhdgydF4y2Ba22gydF4y2Ba(0.53;95% CI: 0.29, 0.77),左手和右手使用相同gydF4y2Ba21gydF4y2Ba(0.38;95% CI: 0.19, 0.57)和疼痛测量gydF4y2Ba21gydF4y2Ba(平均= 0.31;95% ci: 0.21, 0.41)。在11项ENIGMA测试中,只有颅内容量与阅读障碍显著相关(gydF4y2BargydF4y2BaggydF4y2Ba=−0.14;95% ci:−0.06,−0.22)。针对来自英国生物银行的80个结构神经成像测量,包括基于表面的形态测量和与语言相关的脑电路扩散加权成像,在bonferroni校正显著性水平上,独立特征的数量不显著。表型独立性是通过使用PhenoSpD工具包对这些性状的GWAS汇总统计的双变量LDSC截取的表型相关矩阵进行谱分解来估计的gydF4y2Ba23gydF4y2Ba(补充表gydF4y2Ba23gydF4y2Ba).gydF4y2Ba

重要的(gydF4y2BaPgydF4y2Ba< 5 × 10gydF4y2Ba−4gydF4y2Ba)遗传相关性(gydF4y2BargydF4y2BaggydF4y2Ba)之间的自我报告阅读障碍诊断从23andMe和其他表型从LD枢纽数据库和增强神经成像遗传学通过元分析(ENIGMA)。我们测试了98个性状,但只有那些在Bonferroni校正后显著的性状。中心点代表遗传相关性,误差条代表估计值周围的标准误差;具体数值见补充表gydF4y2Ba22gydF4y2Ba.垂直线表示遗传相关性为零,水平线表示相关性状的组。普通中等教育证书;HNC,高级国家证书;HND,国家高级文凭;NVQ,国家职业资格认证。gydF4y2Ba

遗传相关性(gydF4y2BargydF4y2BaggydF4y2Ba)在23andMe自我报告的阅读障碍诊断与GenLang联盟的阅读、语言和表现(非语言)智商测量之间进行了比较。中心点代表LDSC估计的遗传相关性,误差条代表估计周围的标准误差;具体数值见补充表gydF4y2Ba22gydF4y2Ba.gydF4y2Ba
多基因评分分析gydF4y2Ba
在四个独立的队列中计算了基于23andMe阅读障碍GWAS的阅读障碍多基因评分(PGS),总体而言,较高的PGS与较低的阅读和拼写准确性相关(补充表)gydF4y2Ba24gydF4y2Ba).在两个以澳大利亚人口为基础的样本(1647名青少年,1163名成年人)中,阅读障碍PGS解释了阅读和拼写测量中高达3.6%的方差,最能预测非单词阅读测试(语音解码指数)的较低表现。诵读困难症PGS与非单词重复测试(被认为是语音短期记忆的标志)的分数无关。在阅读困难丰富的发育队列中,阅读障碍PGS解释了3.7% (UKdys;gydF4y2BangydF4y2Ba= 930)和5.6% (CLDRC;gydF4y2BangydF4y2Ba= 717)的方差。gydF4y2Ba
从文献分析阅读障碍的关联gydF4y2Ba
在75个先前报道的阅读障碍相关中,没有一个在我们的分析中显示出全基因组意义(补充表gydF4y2Ba25gydF4y2Ba).在这些目标变异中,19 (ingydF4y2BaATP2C2gydF4y2Ba,gydF4y2Ba的生产商gydF4y2Ba,gydF4y2BaCNTNAP2gydF4y2Ba,gydF4y2BaDCDC2gydF4y2Ba,gydF4y2BaDIP2AgydF4y2Ba,gydF4y2BaDYX1C1gydF4y2Ba,gydF4y2BaFOXP2基因gydF4y2Ba,gydF4y2BaKIAA0319LgydF4y2Ba和gydF4y2Ba资金gydF4y2Ba)显示关联存活的Bonferroni校正解释了LD (gydF4y2BaPgydF4y2Ba< 0.05/68.7)。对14个候选基因进行基因检测gydF4y2Ba24gydF4y2Ba,gydF4y2Ba25gydF4y2Ba, Bonferroni级别的关联(gydF4y2BaPgydF4y2Ba< 0.05/14)gydF4y2BaKIAA0319LgydF4y2Ba(gydF4y2BaPgydF4y2Ba= 1.84 × 10gydF4y2Ba−4gydF4y2Ba),gydF4y2BaROBO1gydF4y2Ba(gydF4y2BaPgydF4y2Ba= 1.53 × 10gydF4y2Ba−3gydF4y2Ba)(补充表格gydF4y2Ba26gydF4y2Ba).的gydF4y2BaCNTNAP2gydF4y2Ba关联接近正确的复制水平显著性(gydF4y2BaPgydF4y2Ba= 0.004)。先前涉及阅读障碍的三种途径的靶向基因集分析(补充表gydF4y2Ba27gydF4y2Ba)显示复制级支持(gydF4y2BaPgydF4y2Ba= 2.00 × 10gydF4y2Ba−3gydF4y2Ba)为轴突引导通路(包括216个基因)。gydF4y2Ba
讨论gydF4y2Ba
在迄今为止最大的阅读障碍GWAS(>万例自我报告诊断)中,我们确定了42个显著的独立位点。其中,27个代表了尚未在GWAS中发现的相关认知特征的新关联;其中12个新关联在GenLang联盟的英语和其他欧洲语言阅读/拼写的GWAS元分析中得到验证gydF4y2Ba14gydF4y2Ba,中文组有1人。在重要的snp中,36%与一般认知能力GWAS的变异重叠,这与双胞胎研究一致,该研究发现阅读障碍的遗传变异可以用一般和特定阅读认知能力来解释gydF4y2Ba10gydF4y2Ba.与其他复杂性状相似,各显著位点均表现出较小的效应(比值比在1.04 ~ 1.12之间),且具有较高的多原性。我们估计的基于snp的遗传率为19%(假设诵读困难人群患病率为10%),与较小的GWAS报告的结果相同gydF4y2Ba12gydF4y2Ba,但低于双胞胎研究估计的遗传率(40-80%)。gydF4y2Ba26gydF4y2Ba,gydF4y2Ba27gydF4y2Ba.这种差异可能部分是由于稀有和结构变异的影响gydF4y2Ba28gydF4y2Ba这些基因与阅读和相关特征有关gydF4y2Ba29gydF4y2Ba,gydF4y2Ba30.gydF4y2Ba.gydF4y2Ba
而gydF4y2BaAUTS2gydF4y2Ba与自闭症有关吗gydF4y2Ba31gydF4y2Ba,智力残疾gydF4y2Ba32gydF4y2Ba和阅读障碍gydF4y2Ba33gydF4y2Ba,我们发现的变异(rs3735260)是最强的gydF4y2BaAUTS2gydF4y2Ba迄今为止,SNP与神经发育特征的关联。我们的发现还包括其他已知的神经发育基因,比如gydF4y2BaTANC2gydF4y2Ba(与语言延迟和智力障碍有关gydF4y2Ba34gydF4y2Ba,gydF4y2Ba35gydF4y2Ba),特别是,gydF4y2BaGGNBP2gydF4y2Ba(与神经发育迟缓有关gydF4y2Ba36gydF4y2Ba和自闭症gydF4y2Ba37gydF4y2Ba我们所有的验证队列都支持rs34349354。然而,rs34349354基因也与认知能力有关gydF4y2Ba38gydF4y2Ba,而基于表达的数量性状位点(eQTL)证据更有可能与之相关gydF4y2BaZNHIT3gydF4y2Ba,与分子qtl共定位(gydF4y2Baopentargets.orggydF4y2Ba).值得注意的是,在我们的结果中,没有一个更确定的阅读障碍候选基因接近全基因组意义。gydF4y2Ba
像其他人类复杂性状一样,基于snp的遗传力的划分显示了在保守区域的富集gydF4y2Ba39gydF4y2Ba.我们进一步观察到组蛋白标记H3K4me1的富集(这也被报道用于ASD)gydF4y2Ba40gydF4y2Ba),以及中枢神经系统中的H3K4me1和H3K4me3簇(分别标记增强子和启动子)。由于读写系统是建立在我们的口语能力之上的,人类谱系上的进化变化帮助塑造了潜在的基因结构是合理的gydF4y2Ba41gydF4y2Ba.然而,我们没有发现跨越不同时期的古人类史前史的策展注释的显著关联的丰富。gydF4y2Ba
我们自我报告的阅读障碍诊断二元特征与定量阅读和拼写测量显示出强烈的负遗传相关性,支持该测量在23andMe队列中的有效性,并表明阅读技能和障碍在定性上不明显。听力困难和阅读障碍之间的正向遗传相关与儿童阅读技能的遗传相关报告是一致的gydF4y2Ba42gydF4y2Ba这表明早期的听力问题可能会影响语音处理技能的习得。gydF4y2Ba
阅读障碍与成人的语言-数字推理表现出中度的负遗传相关性,但阅读障碍与(非语言)表现智商缺乏很强的遗传相关性。这将与表型观察相一致,即有阅读障碍的人在言语智商测试中处于不利地位gydF4y2Ba43gydF4y2Ba.受教育程度的相关性也不强,这可能反映了学校的调整和其他支持,以抵消学术学习中的劣势。gydF4y2Ba
几乎没有证据表明阅读障碍的共同遗传变异与皮层下体积的个体差异有关,也没有证据表明与成人语言处理有关的大脑区域的结构连通性和形态测量学。因此,先前报道的阅读障碍与神经解剖学方面的表型相关性可能在很大程度上反映了大脑的环境塑造,也许是通过阅读本身的过程gydF4y2Ba44gydF4y2Ba.左撇子和双撇子之间的基因重叠很小gydF4y2Ba45gydF4y2Ba然而,它们都与神经发育障碍/认知能力有表型上的联系gydF4y2Ba46gydF4y2Ba,gydF4y2Ba47gydF4y2Ba.我们报告了阅读障碍和自述的平等使用手之间的显著遗传相关性,但不是左撇子,支持双手性和阅读障碍之间的理论gydF4y2Ba48gydF4y2Ba.gydF4y2Ba
阅读障碍和多动症gydF4y2Ba5gydF4y2Ba,gydF4y2Ba6gydF4y2Ba经常同时发生(我们的病例中有24%报告ADHD,对照组为9%),我们显示两者之间存在中度遗传相关性,可能反映了共同的内在表型,如工作记忆和注意力缺陷gydF4y2Ba49gydF4y2Ba.虽然我们没有发现阅读障碍和ASD之间有显著的遗传相关性,但后者的GWAS包含了不同的神经发育表型,包括不同教育程度和智商的亚组gydF4y2Ba40gydF4y2Ba.与疼痛相关特征的遗传相关性表明,有阅读障碍的个体可能对疼痛的感知有较低的阈值。疼痛和其他神经发育障碍之间的联系已被报道gydF4y2Ba50gydF4y2Ba,gydF4y2Ba51gydF4y2Ba.gydF4y2Ba
在以人群为基础的和阅读障碍丰富的样本中,阅读障碍多基因得分与阅读和拼写测试的较低成绩相关,特别是在非单词阅读方面,这是一种语音解码的测量方法,通常在阅读障碍中受损。多基因分数可以成为一种有价值的工具,帮助识别有阅读障碍倾向的儿童,在阅读技能发展之前提供学习支持。然而,我们研究的一个局限性是样本选择(即没有阅读障碍和来自较高社会经济地位的人)所产生的对碰撞偏差的可能性,我们无法量化;因此,在未来的研究中,在使用基于多种变异的多基因评分时应谨慎gydF4y2Ba52gydF4y2Ba.gydF4y2Ba
总之,我们报告了42个新的与阅读障碍相关的独立全基因组显著位点,其中27个与认知-教育特征无关,应优先作为阅读障碍患者进行随访。变异的功能注释强调了基因组的保守和增强子区域对该性状的重要性。阅读障碍与注意力缺陷多动障碍、职业资格、体力职业、双灵巧和疼痛知觉呈正相关,与学历和认知能力呈负相关;需要以家庭为基础的方法来分离多效性和因果效应。gydF4y2Ba
方法gydF4y2Ba
GWAS参与者gydF4y2Ba
参与者来自消费者基因公司23andMe, Inc.的客户群。参与者提供知情同意,并根据外部aahrpp认可的IRB批准的协议在线参与研究,伦理和独立审查服务(gydF4y2Bawww.eandireview.comgydF4y2Ba).他们包括51800名(21513名男性,30287名女性)参与者,他们对“你是否被诊断患有阅读障碍”的问题回答“是”。(病例)和回答“否”的1,087,070人(男性446,054人,女性641,016人)(对照组)。年龄从18岁到110岁,年轻参与者的阅读障碍患病率(20-30岁为5.34%)高于年长参与者(80-90岁为3.23%)。阅读障碍患病率与参与者年龄之间的负线性关系是意料之中的,因为对特定学习困难的筛查在最近几十年才变得普遍。此外,这与报告诊断年龄的参与者的子样本(4.3%)的结果一致:年轻的参与者在更早的年龄(例如,20至30岁的参与者为9.7岁(±4.7岁))被诊断出来,而年龄较大的参与者(例如,80至90岁的参与者为22.4岁(±17.8岁))。在我们的样本中,阅读障碍的患病率在女性(4.51%)和男性(4.6%)中是相似的,尽管在这个非常大的样本中,男性的患病率略高,具有统计学意义(gydF4y2BaPgydF4y2Ba< 8.7 × 10gydF4y2Ba−6gydF4y2Ba).这种患病率处于美国人口中典型报告范围的较低端gydF4y2Ba3.gydF4y2Ba考虑到需要正式诊断,这可能代表了更严重的阅读障碍病例;此外,有阅读障碍的人可能会选择退出需要阅读的调查研究,进一步限制了样本范围。gydF4y2Ba
基因分型和imputationgydF4y2Ba
从唾液样本中提取DNA,并在国家遗传学研究所(NGI)的五个基因分型平台之一上进行基因分型。在目前的分析中,只包括有欧洲血统的参与者。关于基因分型阵列、样品质量控制和祖先来源的详细信息可以在Fontanillas等人的文章中找到。gydF4y2Ba53gydF4y2Ba和gydF4y2Ba补充说明gydF4y2Ba.采用Minimac3将阶段性基因型归算到1000个基因组阶段3单倍型的联合参考组(2015年5月)和UK10K归算参考组(见Das等人)。gydF4y2Ba54gydF4y2Ba).gydF4y2Ba
关联分析gydF4y2Ba
使用逻辑回归对基因分型和估算SNP剂量数据进行关联分析,并假设等位基因效应的可加模型。x染色体分析中,男性基因型被视为纯合子二倍体。协变量包括年龄、年龄平方、性别、前五个祖先主成分和基因型平台。通过似然比检验评估SNP显著性,全基因组显著性为gydF4y2BaPgydF4y2Ba< 5 × 10gydF4y2Ba−8gydF4y2Ba(提示显著性水平为gydF4y2BaPgydF4y2Ba< 1 × 10gydF4y2Ba−6gydF4y2Ba).只有可靠估算的单核苷酸多态性(gydF4y2BargydF4y2Ba2gydF4y2Ba> 0.80)和小等位基因频率(MAF) > 0.01者(gydF4y2BangydF4y2Ba= 7995923)。我们通过首先识别所有变量来定义相关区域gydF4y2BaPgydF4y2Ba< 5 × 10gydF4y2Ba−8gydF4y2Ba,然后将这些变体分组到间隔至少250kb的区域。索引变量是最小的变量gydF4y2BaPgydF4y2Ba值。我们对具有暗示性关联的区域使用相同的方法,但首先确定与gydF4y2BaPgydF4y2Ba< 10gydF4y2Ba−5gydF4y2Ba.单独男性的辅助全基因组关联分析(gydF4y2BangydF4y2Ba= 21,513例,对照组446,054例)和女性(gydF4y2BangydF4y2Ba= 30,287例,对照组641,016例)组,以及更年轻(55岁以下;gydF4y2BangydF4y2Ba= 30,763例,对照组582,276例)及以上(55岁及以上;gydF4y2BangydF4y2Ba= 21037例,对照组504794例)。后者是为了检查诊断的可靠性是否会影响GWAS信号(假设诊断的可靠性在年轻样本中更高,他们对诊断的回忆应该更好,他们将暴露在更高水平的阅读障碍筛查中)。gydF4y2Ba
我们还试图在Gialluisi等人发表的一项GWAS元分析中独立验证我们的全基因组显著变异(1),该分析对来自9个欧洲国家代表6种不同语言的2274例阅读障碍患者进行了分析(NeuroDys)。gydF4y2Ba55gydF4y2Ba;(2)总体样本(中文阅读研究;阅读准确性和阅读流畅性的定量特征(gydF4y2BangydF4y2Ba= 2270;详述于gydF4y2Ba补充说明gydF4y2Ba),;(3)对GenLang内词汇阅读的数量性状GWAS进行元分析gydF4y2BangydF4y2Ba= 33,959)和拼写(直到gydF4y2BangydF4y2Ba= 18,514)这项技能测试是由来自欧洲、美国和澳大利亚的儿童和青少年组成的,他们代表了7种欧洲语言,其中英语最为常见gydF4y2Ba14gydF4y2Ba.gydF4y2Ba
基因控制gydF4y2Ba
最高的SNPs来自更保守的GWAS结果,经基因组控制调整(图。gydF4y2Ba1gydF4y2Ba,扩展数据图。gydF4y2Ba1gydF4y2Ba- - - - - -gydF4y2Ba4gydF4y2Ba、及补充表格gydF4y2Ba1gydF4y2Ba,gydF4y2Ba2gydF4y2Ba,gydF4y2Ba9gydF4y2Ba和gydF4y2Ba10gydF4y2Ba),而下游分析(包括基因集分析、富集和遗传力划分、遗传相关性、多基因预测、候选基因复制)是基于GWAS结果而不进行基因组控制。gydF4y2Ba
基于基因的分析gydF4y2Ba
GWAS结果用于基于基因的计算gydF4y2BaPgydF4y2Ba通过在MAGMA v.1.08中进行基因分析,确定与阅读障碍相关的值。gydF4y2Ba56gydF4y2Ba)gydF4y2Ba57gydF4y2Ba使用标准设置。总共测试了19039个基因gydF4y2BaPgydF4y2Ba值根据bonferroni校正的显著性阈值进行判断gydF4y2BaPgydF4y2Ba< 2.63 × 10gydF4y2Ba−6gydF4y2Ba.我们还对生物通路的关联进行了基因集分析(所有可用的基因本体(GO)术语和来自分子特征数据库(MsigDB)的策划基因集)。gydF4y2Ba58gydF4y2Ba,gydF4y2Ba59gydF4y2Ba)通过fua界面在MAGMA进行阅读障碍。测试的路径总数为15,486,并且gydF4y2BaPgydF4y2Ba值根据bonferroni校正的显著性阈值进行判断gydF4y2BaPgydF4y2Ba< 3.23 × 10gydF4y2Ba−6gydF4y2Ba.gydF4y2Ba
生物学注释gydF4y2Ba
使用外部参考数据注释全基因组显著变异体和附近基因,并评估其功能或调控影响。基于近似贝叶斯因子(abf),在重要区域,99%可信的SNPs潜在因果变异集gydF4y2Ba60gydF4y2Ba假设先验方差为0.1,并使用Maller等人的方法。gydF4y2Ba61gydF4y2Ba来定义这些集合。在ENSEMBL (release 104)中对这些变量效应进行了预测。gydF4y2Ba62gydF4y2Ba.对于全基因组显著变异体,我们考虑了:基因背景(无论是基因间变异体还是位于基因位点的特定功能区域内);有害性(综合注释依赖损耗(CADD)评分);功能(RegulomeDB (RDB)类别);染色质状态(最小和常见的15核染色质状态);以及在NHGRI GWAS目录中报告的snp -性状关联gydF4y2Ba13gydF4y2Ba.gydF4y2Ba
对于每个变体,最可能的基因目标是使用开放目标遗传学门户网站确定的gydF4y2Ba63gydF4y2Ba该研究利用了来自QTL和染色质相互作用实验、功能预测以及与基因转录起始位点距离的证据。对于全基因组重要基因,我们考虑:功能缺失不耐受(pLI评分概率);变异不耐受(残留变异不耐受评分,RVIS);非编码区变异不耐受(非编码RVIS, ncRVIS);非编码区域的进化约束(非编码基因组进化速率谱(ncGERP)评分);蛋白质编码区域的进化约束(蛋白质编码基因组进化速率谱(pcGERP)评分);非编码区域的危害性(非编码CADD (ncCADD)评分);非编码区域变异的组合功能(非编码全基因组变异注释(ncGWAVA)评分);12个脑组织(杏仁核、前扣带皮层、尾状基底神经节、小脑半球、小脑、皮层、额皮质、海马、下丘脑、伏隔核基底神经节、壳核基底神经节和黑质)表达。所有注释均通过fua获得gydF4y2Ba57gydF4y2Ba除了RVIS、ncGERP、pcGERP、ncCADD和ncGWAVA,均取自Petrovski等人。gydF4y2Ba64gydF4y2Ba.每个注释的详细信息,包括原始来源gydF4y2Ba补充说明gydF4y2Ba.gydF4y2Ba
分区的遗传gydF4y2Ba
如Finucane等人所述,我们使用分层LDSC对阅读障碍的SNP遗传力进行了划分。gydF4y2Ba39gydF4y2Ba,以确定拥有最大比例遗传力的snp是否也聚集在基因组中的特定功能类别中。总的来说,我们进行了266个不同的测试,这将给出非常保守的bonferroni校正显著性水平1.88 × 10gydF4y2Ba−4gydF4y2Ba,但是因为注释组之间会有重叠,所以我们还报告了不同注释类中对重要性的更正,我们现在描述每个注释类。对Finucane等人定义的24个主要功能注释进行分区。gydF4y2Ba39gydF4y2Ba.LD分数,回归权重和等位基因频率来自欧洲血统样本,并从gydF4y2Bahttps://alkesgroup.broadinstitute.org/LDSCOREgydF4y2Ba.遗传性估计被认为具有统计学意义,如果gydF4y2BaPgydF4y2Ba数值超过了α水平(2.08 × 10)gydF4y2Ba−3gydF4y2Ba,根据24次试验的Bonferroni校正得到。gydF4y2Ba
我们还估计了组织特异性注释对阅读障碍遗传力的富集,同时控制基线模型中的注释,包括三种脑细胞类型的基因表达,12个大脑区域的基因表达,以及多个组织中的染色质标记H3K4me1和H3K4me3(分别为108和114),因为这些标记在增强子上富集gydF4y2Ba65gydF4y2Ba和推动者gydF4y2Ba66gydF4y2Ba,分别。富集是SNP遗传力的比例除以SNP的比例。对于脑细胞类型,我们利用Cahoy等人的数据估计了神经元、星形胶质细胞和少突胶质细胞中表达的基因对阅读障碍遗传力的富集程度。gydF4y2Ba67gydF4y2Ba.浓缩被认为具有统计学意义,如果gydF4y2BaPgydF4y2Ba值超过了0.017的α水平,根据三次试验的Bonferroni校正得出。用于估计某些大脑区域表达的基因遗传力富集的基因表达数据来自GTEx数据库gydF4y2Ba68gydF4y2Babonferroni衍生α富集水平为4.17 × 10gydF4y2Ba−3gydF4y2Ba(基于12次测试)。染色质注释包括来自路线图表观基因组学联盟的数据gydF4y2Ba17gydF4y2Ba和EN-TExgydF4y2Ba69gydF4y2Ba,gydF4y2Ba70gydF4y2Ba.对于H3K4me1, bonferroni衍生α富集水平为4.63 × 10gydF4y2Ba−4gydF4y2Ba(基于108次测试),对于H3K4me3, bonferroni衍生的α富集水平为4.39 × 10gydF4y2Ba−4gydF4y2Ba(基于114次测试)。gydF4y2Ba
进化的注释gydF4y2Ba
尽管阅读和写作是人类的文化发明,但它建立在语言处理的基本途径上。因此,我们通过应用来自Tilot等人的进化分析管道,研究了与人类进化相关的注释是否显著丰富了阅读障碍的遗传力。gydF4y2Ba18gydF4y2Ba.这些分析记录了从大约3000万年前到5万年前进化到人类谱系的一系列时期。gydF4y2Ba
估计成人大脑人类获得增强子(HGEs)的遗传力富集。gydF4y2Ba71gydF4y2Ba,胎儿大脑HGEsgydF4y2Ba72gydF4y2Ba,古代选择性扫掠区域gydF4y2Ba73gydF4y2Ba,尼安德特人渗入的snpgydF4y2Ba74gydF4y2Ba以及尼安德特人消失的地区gydF4y2Ba75gydF4y2Ba(见gydF4y2Ba补充说明gydF4y2Ba对于每个注释的描述);并使用Gazal等人的baselineLD v.2模型进行控制。gydF4y2Ba76gydF4y2Ba.成人和胎儿HGEs的遗传力富集还受到来自路线图表观基因组学资源的成人和胎儿大脑活性调节元件的控制gydF4y2Ba17gydF4y2Ba.使用chromHMM定义主动调控元件gydF4y2Ba16gydF4y2Ba.浓缩gydF4y2BaPgydF4y2Baα水平为10gydF4y2Ba−2gydF4y2Ba,由五次试验的Bonferroni校正得到。gydF4y2Ba
遗传相关性gydF4y2Ba
阅读障碍的23andMe GWAS的遗传相关性gydF4y2Ba
使用LDSC计算男性和女性自我报告的阅读障碍诊断之间的遗传相关性,以及年轻(<55岁)和年长(≥55岁)成年人之间的遗传相关性gydF4y2Ba77gydF4y2Ba,gydF4y2Ba78gydF4y2Ba.gydF4y2Ba
阅读障碍与其他特征的遗传相关性gydF4y2Ba
我们提出了阅读障碍与98个性状的两两遗传相关性。这些特征中的大多数的概要统计数据都可以通过LD Hub公开获得gydF4y2Ba77gydF4y2Ba,gydF4y2Ba78gydF4y2Ba,gydF4y2Ba79gydF4y2Ba-一个集中的数据库和web界面,自动化LDSC回归分析管道。从ENIGMA-3联盟获得的脑磁共振成像测量的选择gydF4y2Ba80gydF4y2Ba,gydF4y2Ba81gydF4y2Ba,gydF4y2Ba82gydF4y2Ba,gydF4y2Ba83gydF4y2Ba以及来自GenLang Consortium的阅读和拼写准确性和性能智商的测量gydF4y2Ba14gydF4y2Ba采用LDSC进行局部分析。GenLang的单词阅读准确性是通过在有时间限制或不受限制的情况下从列表中大声朗读正确单词的数量来衡量的。包括这种测量的工具的例子是单词阅读效率测试(TOWRE),英国能力量表(BAS)和广泛成就测试(WRAT)。GenLang的拼写准确性是通过口头或书面拼写正确的单词数量来衡量的。这些单词被口述为单个单词或在一个句子中。包括这一测量的工具的例子是BAS, WRAT和韦氏客观阅读维度(WORD)。GenLang中的IQ表现基于不依赖于语言线索的IQ测试的子测试,例如BAS和韦氏儿童智力量表(WISC)。性状描述及汇总统计资料来源见补充表gydF4y2Ba22gydF4y2Ba.Bonferroni校正多重测试得到一个调整的临界gydF4y2BaPgydF4y2Ba值为5.1 × 10gydF4y2Ba−4gydF4y2Ba来自98个独立测试gydF4y2Ba
通过对英国生物银行(UK Biobank)的结构脑磁共振成像测量进行有针对性的分析,进一步估计了遗传相关性,该测量比目前从ENIGMA获得的测量更全面,以及诸如半球特异性数据和队列和扫描程序中更大的同质性等进一步优势。从牛津脑成像遗传学服务器下载了3.3万名参与者的脑成像衍生表型的GWAS汇总统计数据gydF4y2Ba84gydF4y2Ba.结构脑成像特征包括弥散张量成像和基于表面的形态测量表型gydF4y2Ba85gydF4y2Ba选定的地区或感兴趣的地区与语言有已知的联系。对于扩散张量成像,从基于束的空间统计和概率束成像中导出的分数各向异性值用于跨越扩展语言网络的可用束gydF4y2Ba86gydF4y2Ba.对于基于表面的形态测量学(皮层体积、表面积和厚度)GWAS,使用了来自Desikan-Killiany地图集(白色表面)的感兴趣区域的汇总统计数据,再次根据它们在语言处理中的相关性选择,基于以往的文献gydF4y2Ba87gydF4y2Ba,gydF4y2Ba88gydF4y2Ba,gydF4y2Ba89gydF4y2Ba,gydF4y2Ba90gydF4y2Ba.为了校正多重测试,通过PhenoSpD推导并分析了英国生物样本库成像指数之间的表型相关性gydF4y2Ba23gydF4y2Ba以获得用于Bonferroni校正的自变量数(36.08)(调整临界gydF4y2BaPgydF4y2Ba值为1.39 × 10gydF4y2Ba−3gydF4y2Ba).gydF4y2Ba
多基因评分分析gydF4y2Ba
阅读障碍多基因评分基于与之相关的越来越多的snpgydF4y2BaPgydF4y2Ba23andMe GWAS的值(gydF4y2BaPgydF4y2Ba< 5 × 10gydF4y2Ba−8gydF4y2Ba,gydF4y2BaPgydF4y2Ba< 1 × 10gydF4y2Ba−5gydF4y2Ba,gydF4y2BaPgydF4y2Ba< 0.001,gydF4y2BaPgydF4y2Ba< 0.01,gydF4y2BaPgydF4y2Ba< 0.05,gydF4y2BaPgydF4y2Ba< 0.1,gydF4y2BaPgydF4y2Ba< 0.5, 1)。它们在四个独立的队列中计算。其中两个是来自澳大利亚的普通人群队列:gydF4y2BangydF4y2Ba= 1,640名(772个家庭)青少年/青年(布里斯班青少年)gydF4y2Ba91gydF4y2Ba;gydF4y2BangydF4y2Ba= 1,165(966个家庭)老年人(布里斯班成年人)gydF4y2Ba25gydF4y2Ba.另外两个是选择阅读障碍患者的家庭样本:一个来自英国,gydF4y2BangydF4y2Ba930个(595个家庭);另一个来自美国(科罗拉多学习障碍研究中心,CLDRC),gydF4y2BangydF4y2Ba= 717(336个家庭)gydF4y2Ba92gydF4y2Ba.在澳大利亚样本中,使用PLINK对1000个基因组阶段3 (v.20101123)估算的遗传数据计算多基因评分gydF4y2Ba93gydF4y2Ba.只有可靠估算的单核苷酸多态性(gydF4y2BaRgydF4y2Ba2gydF4y2Ba> 0.80)和等位基因频率较小的>0.01,并使用默认的聚块程序,其中指标snp与LD中的其他snp形成聚块(gydF4y2BaRgydF4y2Ba2gydF4y2Ba> 0.1),并在250kb距离内。在UKdys和CLDRC样本中,使用PRSice在单倍型参考联盟(Haplotype Reference Consortium)估算的遗传数据上计算多基因评分gydF4y2Ba94gydF4y2Ba,对基样(23andMe GWAS)具有相同的imputation质量和MAF排除,并具有聚块参数。gydF4y2Ba
然后,多基因分数被用作量化特征结果的线性模型的预测因子(澳大利亚:单词、非单词(语音)、不规则单词(词汇)阅读和来自阅读考试组成部分扩展版本的拼写测试gydF4y2Ba95gydF4y2Ba以及对发展性语言障碍敏感的两种非单词重复测试——dollaghan和CampbellgydF4y2Ba96gydF4y2Ba, Gathercole和BaddeleygydF4y2Ba97gydF4y2Ba;UKdys和CLDRC:单词识别)。所有数量性状均对性别、年龄和血统主成分进行了预调整(UKdys和CLDR中有10个主成分;澳大利亚样品中20个主成分)。对澳大利亚样本的归算试验(不同基因分型阵列分别进行试验)、所有样本的非语言智商(澳大利亚成年人除外)以及澳大利亚老年人的听力困难进行了进一步调整。由于队列包括相关的家庭成员(双胞胎或兄弟姐妹),在RStudio中指定了线性混合模型(lme)gydF4y2Ba98gydF4y2Ba家庭成员被建模为随机效应,阅读障碍多基因评分被建模为固定效应。当出现同卵双胞胎时,他们的特征得分被平均,并被用作单个案例。gydF4y2Ba
根据以往文献评估候选人gydF4y2Ba
我们利用23andMe阅读障碍GWAS的结果,在过去的关联研究、关联分析和其他研究中,评估了先前与阅读障碍和/或阅读和拼写能力变化相关或涉及的变异、基因和生物途径。gydF4y2Ba
先前报道的变异gydF4y2Ba
我们在总结统计中评估了75个先前报告的变异,采用复制/验证显著性阈值为gydF4y2BaPgydF4y2Ba< 7.28 × 10gydF4y2Ba−4gydF4y2Ba,基于矩阵谱分解得到的68.7个独立检验,考虑LD,通过Bonferroni校正得到(见Doust et al.;gydF4y2Ba25gydF4y2Ba关于如何选择这些变体的详细信息)。每种变体的来源在补充表中提供gydF4y2Ba26gydF4y2Ba.gydF4y2Ba
阅读障碍候选基因gydF4y2Ba
我们评估了MAGMA v.1.08的基于基因的结果。gydF4y2Ba56gydF4y2Ba)在早期文献中14个候选基因的位点中,来自23andMe阅读障碍GWAS的全基因组显著变异的过度代表:gydF4y2Ba的生产商gydF4y2Ba,gydF4y2BaCNTNAP2gydF4y2Ba,gydF4y2BaCYP19A1gydF4y2Ba,gydF4y2BaDCDC2gydF4y2Ba,gydF4y2BaDIP2AgydF4y2Ba,gydF4y2BaDYX1C1gydF4y2Ba,gydF4y2BaGCFC2gydF4y2Ba,gydF4y2BaKIAA0319gydF4y2Ba,gydF4y2BaKIAA0319LgydF4y2Ba,gydF4y2BaMRPL19gydF4y2Ba,gydF4y2Ba资金gydF4y2Ba,gydF4y2BaPRMT2gydF4y2Ba,gydF4y2BaS100BgydF4y2Ba和gydF4y2BaROBO1gydF4y2Ba.Luciano等人详细阐述了这种选择的基本原理。gydF4y2Ba24gydF4y2Ba杜斯特等人。gydF4y2Ba5gydF4y2Ba.的关键gydF4y2BaPgydF4y2Ba14次试验Bonferroni校正值为3.57 × 10gydF4y2Ba−3gydF4y2Ba.gydF4y2Ba
候选阅读障碍基因集gydF4y2Ba
我们在MAGMA进行了基因集分析,以测试(1)一组转录靶点的全基因组显著变异的过度代表gydF4y2BaFOXP2基因gydF4y2Ba这是一种高度保守的转录因子,与言语障碍有关gydF4y2Ba99gydF4y2Ba;(2)先前提出的两种生物学途径在阅读障碍易感性中发挥作用gydF4y2BaOne hundred.gydF4y2Ba,gydF4y2Ba101gydF4y2Ba-轴突引导(GO:0007411:“引导轴突生长锥迁移到特定目标位点的趋化过程”;216个基因)和神经元迁移(GO:0001764:“未成熟神经元从生发区移动到它们成熟后将停留的特定位置”;145个基因)。调整后的临界gydF4y2BaPgydF4y2Ba基于三次独立试验,采用Bonferroni校正得到0.017的值。gydF4y2Ba
道德标准gydF4y2Ba
参与者提供知情同意,并根据外部aahrpp认可的IRB,伦理和独立审查服务机构批准的协议在线参与研究。在开始数据分析时,根据检查的同意状态将参与者纳入分析。gydF4y2Ba
报告总结gydF4y2Ba
有关研究设计的进一步资料,请参阅gydF4y2Ba自然研究报告摘要gydF4y2Ba链接到这篇文章。gydF4y2Ba
数据可用性gydF4y2Ba
本文中介绍的每个阅读障碍GWAS的完整汇总统计数据将通过23andMe网站(gydF4y2Bahttps://research.23andme.com/dataset-access/gydF4y2Ba)提供给符合23andMe协议的合格研究人员,该协议保护了23andMe参与者的隐私。可以从主GWAS下载前10,000个相关snpgydF4y2Bahttps://doi.org/10.7488/ds/3465gydF4y2Ba.gydF4y2Ba
改变历史gydF4y2Ba
2023年2月23日gydF4y2Ba
对本文的更正已发表:gydF4y2Bahttps://doi.org/10.1038/s41588-023-01336-8gydF4y2Ba
参考文献gydF4y2Ba
里奇,S. J.和贝茨,T. C.童年数学和阅读成绩与成年社会经济地位之间的持久联系。gydF4y2BaPsychol。科学。gydF4y2Ba24gydF4y2Ba, 1301-1308(2013)。gydF4y2Ba
谢维茨,S. E.谢维茨,B. A.弗莱彻,J. M. &埃斯科巴,m.d .男孩和女孩阅读障碍的患病率:康涅狄格纵向研究的结果。gydF4y2Ba《美国医学会杂志》gydF4y2Ba264gydF4y2Ba, 998-1002(1990)。gydF4y2Ba
Katusic, s.k, Colligan, r.c, Barbaresi, W. J., Schaid, d.j . & Jacobsen, s.j .基于出生队列的阅读障碍发生率,1976-1982,罗切斯特,明尼苏达州。gydF4y2Ba梅奥中国。Proc。gydF4y2Ba76gydF4y2Ba, 1081-1092(2001)。gydF4y2Ba
卡罗尔,J. M.,莫恩,B.,古德曼,R. &梅尔策,H.识字困难和精神障碍:共病的证据。gydF4y2Ba儿童精神病。精神病学gydF4y2Ba46gydF4y2Ba, 524-532(2005)。gydF4y2Ba
玛格丽,L.等。学习障碍中的神经精神病理共病。gydF4y2BaBMC神经。gydF4y2Ba13gydF4y2Ba, 198(2013)。gydF4y2Ba
彭宁顿,B. F. & DeFries, J. C.阅读障碍与注意缺陷/多动障碍共病病因学的孪生研究。gydF4y2Ba点。J.医学热内。gydF4y2Ba96gydF4y2Ba, 293-301(2000)。gydF4y2Ba
麦克阿瑟,g.m.,霍格本,j.h.,爱德华兹,v.t.,希思,s.m.和门勒,e.d.关于特定阅读障碍和特定语言障碍的“具体情况”。gydF4y2Ba儿童精神病。精神病学gydF4y2Ba41gydF4y2Ba, 869-874(2000)。gydF4y2Ba
张晓明,张晓明,张晓明。语言障碍儿童阅读效果的纵向研究。gydF4y2BaJ.演讲郎。听到的。Res。gydF4y2Ba45gydF4y2Ba, 1142-1157(2002)。gydF4y2Ba
贝茨,t.c.等。阅读和拼写的遗传和环境基础:一个统一的遗传双路径模型。gydF4y2Ba阅读。令状。gydF4y2Ba20.gydF4y2Ba, 147-171(2007)。gydF4y2Ba
霍沃斯,c.m.a.等。通才基因和学习障碍:对8000名12岁双胞胎的阅读、数学、语言和一般认知能力低表现的多变量遗传分析gydF4y2Ba儿童精神病。精神病学gydF4y2Ba50gydF4y2Ba, 1318-1325(2009)。gydF4y2Ba
发展性阅读障碍:复杂认知特征的遗传解剖。gydF4y2Ba神经科学。gydF4y2Ba3.gydF4y2Ba, 767-780(2002)。gydF4y2Ba
Gialluisi, A.等。全基因组关联研究揭示了对发展性阅读障碍的遗传性和遗传相关性的新见解。gydF4y2Ba精神病学摩尔。gydF4y2Ba26gydF4y2Ba, 3004-3017(2021)。gydF4y2Ba
布尼洛,A.等人。2019年发表的全基因组关联研究、靶向阵列和汇总统计数据的NHGRI-EBI GWAS目录。gydF4y2Ba核酸测定。gydF4y2Ba47gydF4y2Ba, d1005-d1012(2018)。gydF4y2Ba
Eising, E.等人。对多达34000人的阅读和语言相关技能进行定量评估的个体差异的全基因组分析。gydF4y2Ba国家科学院学报美国gydF4y2Ba119gydF4y2Ba, e2202764119(2022)。gydF4y2Ba
Kircher等人。估算人类遗传变异的相对致病性的一般框架。gydF4y2BaNat,麝猫。gydF4y2Ba46gydF4y2Ba, 310-315(2014)。gydF4y2Ba
恩斯特,J. &凯利斯,M. ChromHMM:自动色谱状态发现和表征。gydF4y2BaNat方法。gydF4y2Ba9gydF4y2Ba, 215-216(2012)。gydF4y2Ba
昆达杰等人。111个参考人类表观基因组的综合分析。gydF4y2Ba自然gydF4y2Ba518gydF4y2Ba, 317-330(2015)。gydF4y2Ba
提洛,a.k.等人。影响人类皮质表面积的常见遗传变异的进化史。gydF4y2Ba大脑皮层gydF4y2Ba31gydF4y2Ba, 1873-1887(2020)。gydF4y2Ba
Sniekers, S.等人。对78,308个个体的全基因组关联元分析确定了影响人类智力的新位点和基因。gydF4y2BaNat,麝猫。gydF4y2Ba49gydF4y2Ba, 1107-1112(2017)。gydF4y2Ba
Benyamin, B.等。儿童智力可遗传,高度多基因,与FNBP1L相关。gydF4y2Ba精神病学摩尔。gydF4y2Ba19gydF4y2Ba, 253-258(2014)。gydF4y2Ba
Bycroft, C.等。英国生物银行资源与深层表型和基因组数据。gydF4y2Ba自然gydF4y2Ba562gydF4y2Ba, 203-209(2018)。gydF4y2Ba
米德尔多普,c.m.等人。以人群为基础的儿童队列中注意力缺陷/多动障碍症状的全基因组关联荟萃分析gydF4y2Baj。儿童,青少年。精神病学gydF4y2Ba55gydF4y2Ba, 896 - 905。e6(2016)。gydF4y2Ba
郑,J.等。PhenoSpD:使用GWAS汇总统计进行表型相关性估计和多重测试校正的集成工具包。gydF4y2BaGigasciencegydF4y2Ba7gydF4y2Ba, giy090(2018)。gydF4y2Ba
卢西亚诺,M.高,A. J.帕蒂,A.贝茨,T. C. &迪瑞,I. J.阅读障碍候选基因对老年阅读技能的影响。gydF4y2BaBehav。麝猫。gydF4y2Ba48gydF4y2Ba, 351-360(2018)。gydF4y2Ba
杜斯特,等。阅读障碍和发展性言语和语言障碍候选基因与成人阅读和语言能力的关联。gydF4y2Ba双胞胎,嗯。麝猫。gydF4y2Ba23gydF4y2Ba, 23-32(2020)。gydF4y2Ba
Davis, C. J., Knopik, V. S., Olson, R. K., Wadsworth, S. J. & DeFries, J. C.基因和环境对快速命名和阅读能力的影响。gydF4y2Ba安。难语症gydF4y2Ba51gydF4y2Ba, 231-247(2001)。gydF4y2Ba
Gayán, J. & Olson, R. K.遗传和环境对阅读障碍儿童正字法和语音技能的影响。gydF4y2BaDev Neuropsychol。gydF4y2Ba20.gydF4y2Ba, 483-507(2001)。gydF4y2Ba
Hannula-Jouppi, K.等。轴突引导受体基因ROBO1是发育性阅读障碍的候选基因。gydF4y2Ba公共科学图书馆麝猫。gydF4y2Ba1gydF4y2Ba, e50(2005)。gydF4y2Ba
Ganna, A.等。极端罕见的破坏性和破坏性突变会影响一般人群的受教育程度。gydF4y2BaNat。>。gydF4y2Ba19gydF4y2Ba, 1563-1565(2016)。gydF4y2Ba
Gialluisi, A.等。研究拷贝数变异对阅读和语言表现的影响。gydF4y2Baj . Neurodev。Disord。gydF4y2Ba8gydF4y2Ba, 17-17(2016)。gydF4y2Ba
奥克森伯格,N.,史蒂文森,L.,沃尔,J. D.和阿希图夫,N. AUTS2基因的功能和调控,一个涉及自闭症和人类进化的基因。gydF4y2Ba公共科学图书馆麝猫。gydF4y2Ba9gydF4y2Ba, e1003221(2013)。gydF4y2Ba
Beunders, G.等人。两名成年男性AUTS2致病性变异,包括两个碱基对缺失,进一步描述了AUTS2综合征。gydF4y2Ba欧元。J.人类生殖器。gydF4y2Ba23gydF4y2Ba, 803-807(2015)。gydF4y2Ba
Girirajan, S.等人。大CNVs对一系列神经发育表型的相对负担。gydF4y2Ba公共科学图书馆麝猫。gydF4y2Ba7gydF4y2Ba, e1002334(2011)。gydF4y2Ba
17q23.2q23.3与言语和语言障碍、学习困难、不协调、运动技能障碍和行为障碍相关的从头重复:一例报告。gydF4y2BaBMC医学,Genet。gydF4y2Ba18gydF4y2Ba, 119(2017)。gydF4y2Ba
郭,H.等。TANC2的破坏性突变定义了与精神障碍相关的神经发育综合征。gydF4y2BaCommun Nat。gydF4y2Ba10gydF4y2Ba, 4679(2019)。gydF4y2Ba
帕斯蒙特,E.等人。在一名NF1连续基因综合征患者中,7.6 mb种系缺失包括NF1位点和约100个基因的特征。gydF4y2Ba欧元。j .的嗡嗡声。麝猫。gydF4y2Ba16gydF4y2Ba, 1459-1466(2008)。gydF4y2Ba
高田,A.等。对新生突变的综合分析为自闭症谱系障碍提供了更深层次的生物学见解。gydF4y2Ba细胞的报道gydF4y2Ba22gydF4y2Ba, 734-747(2018)。gydF4y2Ba
李,J. J.等。基因发现和多基因预测来自110万人受教育程度的全基因组关联研究。gydF4y2BaNat,麝猫。gydF4y2Ba50gydF4y2Ba, 1112-1121(2018)。gydF4y2Ba
斐努凯恩,H. K.等。利用全基因组关联汇总统计数据,通过功能注释划分遗传力。gydF4y2BaNat,麝猫。gydF4y2Ba47gydF4y2Ba, 1228-1235(2015)。gydF4y2Ba
格罗夫,J.等。自闭症谱系障碍常见遗传风险变异的鉴定。gydF4y2BaNat,麝猫。gydF4y2Ba51gydF4y2Ba, 431-444(2019)。gydF4y2Ba
莫兹,A.等人。口语和书面语相关基因的进化史:超越FOXP2。gydF4y2Ba科学。代表。gydF4y2Ba6gydF4y2Ba, 22157(2016)。gydF4y2Ba
Schmitz, J., Abbondanza, F. & Paracchini, S.儿童听力测量的全基因组关联研究和多基因风险评分分析。gydF4y2Ba点。J.医学热内。B Neuropsychiatr。麝猫。gydF4y2Ba186gydF4y2Ba, 318-328(2021)。gydF4y2Ba
阅读障碍的不同概念:支持语言缺陷假说的证据。gydF4y2Ba哈佛大学的建造。牧师。gydF4y2Ba47gydF4y2Ba, 334-354(2012)。gydF4y2Ba
德阿纳,科恩,L.,莫莱斯,J.和柯林斯基,R.文盲到识字:阅读习得引起的行为和大脑变化。gydF4y2Ba神经科学。gydF4y2Ba16gydF4y2Ba, 234-244(2015)。gydF4y2Ba
Cuellar-Partida, G.等。全基因组关联研究确定了48种与用手习惯相关的常见遗传变异。gydF4y2BaNat,哼。Behav。gydF4y2Ba5gydF4y2Ba, 59-70(2021)。gydF4y2Ba
帕帕达图-帕斯图,等人。人类用手习惯:元分析。gydF4y2BaPsychol。公牛。gydF4y2Ba146gydF4y2Ba, 481-524(2020)。gydF4y2Ba
Peters, M, Reimers, S. & Manning, J. T. Hand在255,100名受试者中对写作的偏好及其与选定的人口统计学和行为变量的关联:BBC互联网研究。gydF4y2Ba大脑Cogn。gydF4y2Ba62gydF4y2Ba, 177-189(2006)。gydF4y2Ba
布兰德勒,W. M. & Paracchini, S.利手与神经发育障碍的遗传关系。gydF4y2Ba趋势、医学。gydF4y2Ba20.gydF4y2Ba, 83-90(2014)。gydF4y2Ba
威尔卡特,彭宁顿,B. F.,奥尔森,R. K., Chhabildas, N. & Hulslander, J.阅读障碍和注意缺陷多动障碍共病的神经心理学分析:寻找共同缺陷。gydF4y2BaDev Neuropsychol。gydF4y2Ba27gydF4y2Ba, 35-78(2005)。gydF4y2Ba
Gu, x等。患有自闭症谱系障碍的高功能成年人对疼痛预期的大脑反应增强。gydF4y2Ba欧元。j . >。gydF4y2Ba47gydF4y2Ba, 592-601(2018)。gydF4y2Ba
惠特尼,D. G. &夏皮罗,D. N.患有自闭症谱系障碍的儿童和青少年疼痛的全国流行率。gydF4y2BaJAMA Pediatr。gydF4y2Ba173gydF4y2Ba, 1203-1205(2019)。gydF4y2Ba
Munafò, M. R., Tilling, K., Taylor, A. E. Evans, D. M. & Davey Smith, G. Collider scope:当选择偏差可以显著影响观察到的关联时。gydF4y2BaInt。j .论文。gydF4y2Ba47gydF4y2Ba, 226-235(2018)。gydF4y2Ba
Fontanillas, P.等人。皮肤癌的疾病风险评分。gydF4y2BaCommun Nat。gydF4y2Ba12gydF4y2Ba, 160(2021)。gydF4y2Ba
Das, S.等人。下一代基因型植入服务和方法。gydF4y2BaNat,麝猫。gydF4y2Ba48gydF4y2Ba, 1284-1287(2016)。gydF4y2Ba
Gialluisi, A.等。全基因组关联扫描确定了与阅读障碍认知预测相关的新变异。gydF4y2BaTransl。精神病学gydF4y2Ba9gydF4y2Ba, 77(2019)。gydF4y2Ba
de Leeuw, C. A., Mooij, J. M., Heskes, T. & Posthuma, D. MAGMA: GWAS数据的广义基因集分析。gydF4y2Ba公共科学图书馆第一版。医学杂志。gydF4y2Ba11gydF4y2Ba, e1004219(2015)。gydF4y2Ba
Watanabe, K, Taskesen, E, van Bochoven, A. & Posthuma, D. fua遗传关联的功能映射和注释。gydF4y2BaCommun Nat。gydF4y2Ba8gydF4y2Ba, 1826(2017)。gydF4y2Ba
萨勃拉曼尼亚,A.等。基因集富集分析:解释全基因组表达谱的一种基于知识的方法。gydF4y2Ba国家科学院学报美国gydF4y2Ba102gydF4y2Ba, 15545-15550(2005)。gydF4y2Ba
Liberzon等人。分子特征库(MSigDB) 3.0。gydF4y2Ba生物信息学gydF4y2Ba27gydF4y2Ba, 1739-1740(2011)。gydF4y2Ba
遗传流行病学研究中错误发现概率的贝叶斯度量。gydF4y2Ba点。J.人类生殖器。gydF4y2Ba81gydF4y2Ba, 208-227(2007)。gydF4y2Ba
马勒,J. B.等。3种常见疾病14个位点关联信号的贝叶斯细化。gydF4y2BaNat,麝猫。gydF4y2Ba44gydF4y2Ba, 1294-1301(2012)。gydF4y2Ba
豪,K. L.等。运用2021年。gydF4y2Ba核酸测定。gydF4y2Ba49gydF4y2Ba, d884-d891(2020)。gydF4y2Ba
Carvalho-Silva, D.等人。开放目标平台:两年来的新发展和更新。gydF4y2Ba核酸测定。gydF4y2Ba47gydF4y2Ba, d1056-d1065(2018)。gydF4y2Ba
彼得罗夫斯基等人。调控序列对遗传变异的不耐受预示着基因的剂量敏感性。gydF4y2Ba公共科学图书馆麝猫。gydF4y2Ba11gydF4y2Ba, e1005492(2015)。gydF4y2Ba
Rada-Iglesias, A. H3K4me1增强子是相关的还是致病的?gydF4y2BaNat,麝猫。gydF4y2Ba50gydF4y2Ba, 4-5(2018)。gydF4y2Ba
Heintzman, n.d.等人。人类基因组中转录启动子和增强子的独特和预测染色质特征。gydF4y2BaNat,麝猫。gydF4y2Ba39gydF4y2Ba, 311-318(2007)。gydF4y2Ba
Cahoy, J. D.等人。星形胶质细胞、神经元和少突胶质细胞的转录组数据库:理解大脑发育和功能的新资源。gydF4y2Baj . >。gydF4y2Ba28gydF4y2Ba, 264(2008)。gydF4y2Ba
GTEx联盟。基因型-组织表达(GTEx)先导分析:人类多组织基因调控。gydF4y2Ba科学gydF4y2Ba348gydF4y2Ba, 648(2015)。gydF4y2Ba
斐努凯恩,H. K.等。特异性表达基因的遗传力富集可识别疾病相关组织和细胞类型。gydF4y2BaNat,麝猫。gydF4y2Ba50gydF4y2Ba, 621-629(2018)。gydF4y2Ba
Dunham, I.等人。人类基因组中DNA元素的综合百科全书。gydF4y2Ba自然gydF4y2Ba489gydF4y2Ba, 57-74(2012)。gydF4y2Ba
佛蒙特,m.w.等。灵长类动物大脑进化过程中基因调控改变的表观基因组注释。gydF4y2BaNat。>。gydF4y2Ba19gydF4y2Ba, 494-503(2016)。gydF4y2Ba
赖利,S. K.等。进化基因组学。人类皮质发生过程中启动子和增强子活性的进化变化。gydF4y2Ba科学gydF4y2Ba347gydF4y2Ba, 1155-1159(2015)。gydF4y2Ba
Peyrégne, S., Boyle, M. J., Dannemann, M. & Prüfer, K.使用扩展谱系排序检测人类的古代正向选择。gydF4y2Ba基因组Res。gydF4y2Ba27gydF4y2Ba, 1563-1572(2017)。gydF4y2Ba
西蒙蒂,C. N.等。现代人和尼安德特人混合后的表型遗产。gydF4y2Ba科学gydF4y2Ba351gydF4y2Ba, 737-741(2016)。gydF4y2Ba
Vernot, B.等人。从美拉尼西亚人的基因组中挖掘尼安德特人和丹尼索瓦人的DNA。gydF4y2Ba科学gydF4y2Ba352gydF4y2Ba, 235-239(2016)。gydF4y2Ba
Gazal, S.等人。人类复杂性状的连锁不平衡依赖结构表现出负选择作用。gydF4y2BaNat,麝猫。gydF4y2Ba49gydF4y2Ba, 1421-1427(2017)。gydF4y2Ba
布里克-沙利文,B. K.等。LD评分回归在全基因组关联研究中区分混杂和多基因性。gydF4y2BaNat,麝猫。gydF4y2Ba47gydF4y2Ba, 291-295(2015)。gydF4y2Ba
布里克-沙利文,B. K.等。人类疾病和性状遗传相关性图谱。gydF4y2BaNat,麝猫。gydF4y2Ba47gydF4y2Ba, 1236-1241(2015)。gydF4y2Ba
郑,J.等。LD Hub:执行LD评分回归的集中式数据库和web界面,最大限度地利用汇总水平GWAS数据进行SNP遗传力和遗传相关性分析。gydF4y2Ba生物信息学gydF4y2Ba33gydF4y2Ba, 272-279(2016)。gydF4y2Ba
格拉斯比,K. L.等。人类大脑皮层的遗传结构。gydF4y2Ba科学gydF4y2Ba367gydF4y2Ba, eaay6690(2020)。gydF4y2Ba
Satizabal, C. L.等。38851个个体皮层下大脑结构的遗传结构。gydF4y2BaNat,麝猫。gydF4y2Ba51gydF4y2Ba, 1624-1636(2019)。gydF4y2Ba
Hibar, D. P.等。与海马体积相关的新基因位点。gydF4y2BaCommun Nat。gydF4y2Ba8gydF4y2Ba, 13624(2017)。gydF4y2Ba
亚当斯,H. H.等。通过全基因组关联确定人类颅内容量的新遗传位点。gydF4y2BaNat。>。gydF4y2Ba19gydF4y2Ba, 1569-1582(2016)。gydF4y2Ba
史密斯,s.m.等人。英国生物库中脑成像表型全基因组关联研究的扩展集。gydF4y2BaNat。>。gydF4y2Ba24gydF4y2Ba, 737-745(2021)。gydF4y2Ba
Alfaro-Almagro, F.等人。英国生物银行首批10,000个脑成像数据集的图像处理和质量控制。gydF4y2Ba科学杂志gydF4y2Ba166gydF4y2Ba, 400-424(2018)。gydF4y2Ba
福克尔,S. J. &卡塔尼,M。gydF4y2Ba牛津神经语言学手册:语言科学中的扩散成像方法gydF4y2Ba(牛津大学出版社,牛津,2019)。gydF4y2Ba
语言解剖:2009年发表的100项功能磁共振成像研究综述。gydF4y2Ba安。纽约大学科学学院gydF4y2Ba1191gydF4y2Ba, 62-88(2010)。gydF4y2Ba
理查森,F. M. &价格,C. J.结构MRI研究的语言功能在未受损的大脑。gydF4y2Ba大脑结构。功能。gydF4y2Ba213gydF4y2Ba, 511-523(2009)。gydF4y2Ba
普杜,M. V.,梅德尼克,J.,普,K. R. &兰蒂,N.,灰质结构与典型发展中的年轻读者阅读技能相关。gydF4y2BaCereb。皮质gydF4y2Ba30.gydF4y2Ba, 5449-5459(2020)。gydF4y2Ba
roehrich gascon, D., Small, S. L. & Tremblay, P.口语能力的结构相关性:基于表面的感兴趣区域形态测量研究。gydF4y2Ba大脑朗。gydF4y2Ba149gydF4y2Ba, 46-54(2015)。gydF4y2Ba
卢西亚诺等人。两组人群阅读和语言能力的全基因组关联研究。gydF4y2Ba基因,大脑行为。gydF4y2Ba12gydF4y2Ba, 645-652(2013)。gydF4y2Ba
Gialluisi, A.等。全基因组筛选与阅读和语言特征相关的DNA变异。gydF4y2Ba基因,大脑行为。gydF4y2Ba13gydF4y2Ba, 686-701(2014)。gydF4y2Ba
Purcell, S.等人。PLINK:全基因组关联和基于人群的连锁分析工具集。gydF4y2Ba点。J.人类生殖器。gydF4y2Ba81gydF4y2Ba, 559-575(2007)。gydF4y2Ba
Euesden, J. Lewis, C. M. & O 'Reilly, P. F. PRSice:多基因风险评分软件。gydF4y2Ba生物信息学gydF4y2Ba31gydF4y2Ba, 1466-1468(2015)。gydF4y2Ba
贝茨,t.c.等。阅读和拼写的行为遗传分析:一个组成过程的方法。gydF4y2Ba欧斯特。j . Psychol。gydF4y2Ba56gydF4y2Ba, 115-126(2004)。gydF4y2Ba
多拉汉,C. &坎贝尔,t.f.非单词重复与儿童语言障碍。gydF4y2BaJ.演讲郎。听到的。Res。gydF4y2Ba41gydF4y2Ba, 1136-1146(1998)。gydF4y2Ba
盖瑟科尔,S. E.,威利斯,C. S.,巴德利,a . D. &埃姆斯利,H.儿童非单词重复测试:语音工作记忆测试。gydF4y2Ba内存gydF4y2Ba2gydF4y2Ba, 103-127(1994)。gydF4y2Ba
RStudio团队。RStudio: R.的集成开发(波士顿,马萨诸塞州,2020)。gydF4y2Ba
阿尤布,Q.等人。FOXP2靶在欧洲人群中显示出积极选择的证据。gydF4y2Ba点。J.人类生殖器。gydF4y2Ba92gydF4y2Ba, 696-706(2013)。gydF4y2Ba
Poelmans, G., Buitelaar, J. K., paul, D. L. & Franke, B.阅读障碍的理论分子网络:整合可用的遗传发现。gydF4y2Ba精神病学摩尔。gydF4y2Ba16gydF4y2Ba, 365-382(2011)。gydF4y2Ba
Guidi, L. G.等。阅读障碍的神经元迁移假说:30年后的批判性评价。gydF4y2Ba欧元。j . >。gydF4y2Ba48gydF4y2Ba, 3212-3233(2018)。gydF4y2Ba
确认gydF4y2Ba
我们感谢23andMe公司、GenLang联盟、布里斯班成人阅读研究和CRS的研究参与者和员工。e.e., G.A, b.m., B.S.P, C.F.和S.E.F.由马克斯普朗克学会(德国)支持。国家自然科学基金项目(No. 61807023)、教育部人文社会科学研究基金项目(No. 19YJC190023、17XJC190010)、陕西省自然科学基础研究项目一般项目(No. 2018JQ8015、2021JQ-309)资助。S.P.由英国皇家学会资助。GenLang联盟的致谢见补充说明。gydF4y2Ba
作者信息gydF4y2Ba
作者及隶属关系gydF4y2Ba
财团gydF4y2Ba
贡献gydF4y2Ba
M.L.、s.e.f.、T.C.B.和N.G.M.构思了这项研究,M.L.负责一般分析,A.A.负责23andMe分析。c.d., p.f., e.e., g.a., S.D.G, Z.W, B.M.和M.L.进行了统计和/或下游注释分析。rem建议cd做一些分析。C.D.起草了手稿,部分由p.f.、e.e.、g.a.、Z.W.和m.l.b s.p贡献,C.F.和S.E.F.监督了GenLang GWAS。J.Z.负责中文阅读研究。s.p.、j.b.t.、A.P.M.和J.F.S.负责ukdy的研究。J.R.G R.K.O。,E.G.W J.C.D B.F.P.和S.D.S. CLDRC研究管理。M.J.W, T.C.B.和N.G.M.负责澳大利亚青少年双胞胎研究。m.l.、T.C.B、S.E.F.和N.G.M.负责澳大利亚成人阅读研究。所有作者都对手稿进行了严格的审查。gydF4y2Ba
相应的作者gydF4y2Ba
道德声明gydF4y2Ba
相互竞争的利益gydF4y2Ba
p.f.、A.A.和23andMe研究团队受雇于23andMe, Inc.,并持有其股票或股票期权。其余作者声明没有竞争利益。gydF4y2Ba
同行评审gydF4y2Ba
同行评审信息gydF4y2Ba
自然遗传学gydF4y2Ba感谢匿名审稿人对本工作的同行评议所作的贡献。gydF4y2Ba同行评审报告gydF4y2Ba是可用的。gydF4y2Ba
额外的信息gydF4y2Ba
出版商的注意gydF4y2Ba施普林格自然对出版的地图和机构从属关系中的管辖权主张保持中立。gydF4y2Ba
扩展数据gydF4y2Ba
扩展数据图1阅读障碍GWAS结果QQ图。gydF4y2Ba
一个gydF4y2Ba-gydF4y2BacgydF4y2Ba,观察值与预期值的分位数-分位数(Q-Q)图gydF4y2BaPgydF4y2Ba在所有参与者的全基因组关联分析中,单核苷酸多态性与自我报告的阅读障碍诊断的相关性值(gydF4y2BangydF4y2Ba= 51,800例,1,087,070对照)(gydF4y2Ba一个gydF4y2Ba)、女性参加者(gydF4y2BangydF4y2Ba= 30,287例,对照组641,016例)(gydF4y2BabgydF4y2Ba),以及男性参加者(gydF4y2BangydF4y2Ba= 21,513例,对照组446,054例)(gydF4y2BacgydF4y2Ba).红色实线表示分布gydF4y2BaPgydF4y2Ba零假设下的值,红色虚线表示95%置信区间。黑色圆圈表示观测到的分布gydF4y2BaPgydF4y2Ba值。gydF4y2Ba
扩展数据图2女性阅读障碍GWAS结果曼哈顿图。gydF4y2Ba
的gydF4y2Bay -gydF4y2BaAxis表示-loggydF4y2Ba10gydF4y2BaPgydF4y2Ba来自30,287名女性个体和641,016名女性对照的单核苷酸多态性与自我报告的阅读障碍诊断的相关性价值。全基因组显著性的阈值(gydF4y2BaPgydF4y2Ba< 5 × 10gydF4y2Ba−8gydF4y2Ba)由一条水平灰线表示。17个全基因组显著位点的全基因组显著变异体为红色。位于彼此之间250 kb距离内的变异被认为是一个基因座。gydF4y2Ba
扩展数据图3男性阅读障碍GWAS结果曼哈顿图。gydF4y2Ba
的gydF4y2Bay -gydF4y2BaAxis表示-loggydF4y2Ba10gydF4y2BaPgydF4y2Ba单核苷酸多态性与自我报告的阅读障碍诊断的价值,来自21,513名男性个体和446,054名男性对照。全基因组显著性的阈值(gydF4y2BaPgydF4y2Ba< 5 × 10gydF4y2Ba−8gydF4y2Ba)由一条水平灰线表示。6个全基因组显著位点的全基因组显著变异体为红色。位于彼此之间250 kb距离内的变异被认为是一个基因座。gydF4y2Ba
扩展数据图4与阅读障碍显著相关的可信变异集的变异效应预测因子摘要。gydF4y2Ba
摘要信息来自ENSEMBL(版本104)中的在线变异效应预测器。我们所有的变体都出现在1000个基因组参考面板中,因此被认为是存在的,并且没有预先过滤(例如,在MAF上;结果类型)。gydF4y2Ba
扩展数据图5主要功能注释的丰富估计。gydF4y2Ba
24个主要功能注释由Finucane等人定义。gydF4y2Ba39gydF4y2Ba.浓缩是比例gydF4y2BahgydF4y2Ba2gydF4y2Ba/ SNPs的比例。水平虚线表示未富集(其中gydF4y2BahgydF4y2Ba2gydF4y2Ba/ SNPs的比例= 1)。误差柱表示富集估计的标准误差。星号表示基于bonferroni衍生的富集估计是重要的gydF4y2BaPgydF4y2Ba值< 2.08 × 10gydF4y2Ba−3gydF4y2Ba(24次测试)。浓缩统计量的精确值,标准误差,和gydF4y2BaPgydF4y2Ba值可在补充表中查询gydF4y2Ba16gydF4y2Ba.gydF4y2Ba
图6脑组织基因表达划分的阅读障碍遗传力。gydF4y2Ba
的日志gydF4y2Ba10gydF4y2BaPgydF4y2Ba12个脑区表达的阅读障碍基因遗传力的富集估计值。水平虚线表示12次试验Bonferroni校正后的显著性(gydF4y2BaPgydF4y2Ba< 4.17 × 10gydF4y2Ba−3gydF4y2Ba).gydF4y2Ba
图7按脑细胞类型划分的阅读障碍遗传力。gydF4y2Ba
的日志gydF4y2Ba10gydF4y2BaPgydF4y2Ba脑细胞类型阅读障碍遗传力的富集估计值。水平虚线表示三次试验Bonferroni校正后的显著性(gydF4y2BaPgydF4y2Ba< 1.67 × 10gydF4y2Ba−2gydF4y2Ba).gydF4y2Ba
图8阅读障碍的遗传力由细胞类型特异性H3K4me1划分。gydF4y2Ba
的日志gydF4y2Ba10gydF4y2BaPgydF4y2Ba不同组织中位于H3K4me1峰内的变体的阅读障碍遗传力的富集估计值。深绿色表示中枢神经系统组织,浅绿色表示其他组织。垂直虚线表示114次试验Bonferroni校正后的显著性(gydF4y2BaPgydF4y2Ba< 4.39 × 10gydF4y2Ba−4gydF4y2Ba).gydF4y2Ba
图9用细胞类型特异性H3K4me3划分的阅读障碍遗传力。gydF4y2Ba
的日志gydF4y2Ba10gydF4y2BaPgydF4y2Ba不同组织中位于H3K4me3峰内的变体的阅读障碍遗传力的富集估计值。深蓝色表示中枢神经系统组织,浅蓝色表示其他组织。垂直虚线表示114次试验Bonferroni校正后的显著性(gydF4y2BaPgydF4y2Ba< 4.39 × 10gydF4y2Ba−4gydF4y2Ba).gydF4y2Ba
补充信息gydF4y2Ba
权利和权限gydF4y2Ba
开放获取gydF4y2Ba本文遵循知识共享署名4.0国际许可协议(Creative Commons Attribution 4.0 International License),允许以任何媒介或格式使用、分享、改编、分发和复制,只要您对原作者和来源给予适当的署名,提供知识共享许可协议的链接,并注明是否有更改。本文中的图像或其他第三方材料包含在文章的创作共用许可中,除非在材料的信用额度中另有说明。如果内容未包含在文章的创作共用许可协议中,并且您的预期使用不被法定法规所允许或超出了允许的使用范围,您将需要直接获得版权所有者的许可。要查看此许可证的副本,请访问gydF4y2Bahttp://creativecommons.org/licenses/by/4.0/gydF4y2Ba.gydF4y2Ba
关于本文gydF4y2Ba

引用本文gydF4y2Ba
杜斯特,C.,丰塔尼拉斯,P.,艾辛,E.。gydF4y2Baet al。gydF4y2Ba发现42个与阅读障碍相关的全基因组显著位点。gydF4y2BaNat麝猫gydF4y2Ba54gydF4y2Ba, 1621-1629(2022)。https://doi.org/10.1038/s41588-022-01192-ygydF4y2Ba
收到了gydF4y2Ba:gydF4y2Ba
接受gydF4y2Ba:gydF4y2Ba
发表gydF4y2Ba:gydF4y2Ba
发行日期gydF4y2Ba:gydF4y2Ba
DOIgydF4y2Ba:gydF4y2Bahttps://doi.org/10.1038/s41588-022-01192-ygydF4y2Ba
这篇文章被引用gydF4y2Ba
大脑结构、表型和遗传与阅读能力的相关性gydF4y2Ba
人类行为gydF4y2Ba(2023)gydF4y2Ba
识别与单词阅读和相关特征的潜在遗传关联的脑细胞类型gydF4y2Ba
《分子精神病学》gydF4y2Ba(2023)gydF4y2Ba
心脏代谢健康,饮食和肠道微生物组:元组学的观点gydF4y2Ba
自然医学gydF4y2Ba(2023)gydF4y2Ba
