








摘要
质谱脂质组学的进展导致了横跨生物学和生物医学的研究迅速扩散。这些会生成非常大的原始数据集,需要复杂的解决方案来支持自动化数据处理。为了解决这个问题,已经为特定的任务开发和定制了许多软件工具。然而,对于研究人员来说,决定哪种方法最适合他们的应用依赖于临时测试,这是低效和耗时的。在这里,我们首先回顾数据处理管道,总结可用工具的范围。接下来,为了支持研究人员,脂质地图提供了一个交互式在线门户,列出了具有图形用户界面的开放获取工具。这将指导用户在数据处理的主要领域中找到适当的解决方案,包括(1)面向脂类的数据库,(2)质谱数据库,(3)目标脂类组学数据集的分析,(4)脂类识别和(5)非目标脂类组学数据集的量化,(6)统计分析和可视化,以及(7)数据集成解决方案。详细介绍数据分析的功能和需求,为用户定制化的数据分析流程提供指导。
主要
脂质组学是代谢组学的一个快速发展的子领域,报告与健康和疾病相关的脂质物种的生成和代谢1,2,3.,4,5.人们对使用脂质组学来识别生物标志物和干预疾病进展的新靶点,以及描述基础机制越来越感兴趣6,7,8.在过去的10年里,脂质组学质谱(MS)方法在生物医学研究中的建立和应用出现了爆炸式增长。新一代的质谱仪器,特别是高分辨率的飞行时间和轨道跟踪配置,能够生成大型“组学”类型的数据集,可以在一次分析运行中报告数千种脂类。随着目前该领域的驱动是分析大量的样本(例如,血浆和组织提取物),实验生成的数据量正呈指数级增长。这导致了数据处理和下游存储方面的挑战,以供以后(开放访问)重用,这需要智能计算解决方案。
研究人员通过开发新的算法和工具,对数据进行有效的计算处理,对脂质组学中数据分析的新挑战做出了强有力的回应。这些工具已经开始应用新的脂质组学方法来表征不同的生物过程,在许多情况下导致了显著的发现,这里列出了一些例子。一些工具已经应用于分析血脂组,例如LipidXplorer, LipidFinder和脂质数据分析仪(LDA)。9,10.LDA还为各种生物化学研究做出了贡献,包括脂肪细胞来源的细胞外囊泡表征11,确定磷脂酰丝氨酸在自噬中的作用12,分析脂质在黄病毒复制中的作用13,以及脂质双分子层如何稳定血清素受体14.与此同时,LipidFinder对首次报告的SARS-CoV2包膜成分的高分辨率质谱数据进行了扩展清理15.作为进一步的例子,脂质本体丰富网络工具,LION/web16使研究脂质在骨髓中性粒细胞衰老过程中的作用成为可能17以及性别和基因对卡路里限制代谢反应的影响18.本文中描述的一些工具,包括LION/Web和XCMS,已经能够研究细胞代谢状态19,20..此外,XCMS阐明了鞘脂在神经性疼痛中的作用21.虽然这只是使用现有工具的一小部分说说性研究,但随着越来越多的研究人员进入该领域,脂质组学工具的生物应用的数量和多样性正在增加。脂质地图在全球约有7.2万名用户,2021年脂质地图结构数据库下载> 4600次,浏览约38万次,2020-2021年期间出版物引用约2500次(谷歌Scholar,谷歌Analytics数据)。
在选择要使用的数据分析方法时,研究人员需要考虑底层数据结构和所提出的研究问题。他们还需要了解算法所使用的底层方法,以确定算法是否会像预期的那样对特定数据执行。然而,目前决定最合适的软件是基于特别的过程,例如手动搜索文献和单独测试包。这既耗时又低效,因为实现工具需要大量的培训和熟悉。此外,不恰当地使用软件可能导致重大错误,例如,脂质鉴定的错误注释或错误地将噪声解释为峰,以表明样品中存在脂质。
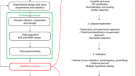
为了解决这些问题,并支持研究人员识别和测试适当的脂质组学计算解决方案,脂质组学工具指南(https://www.lipidmaps.org/resources/tools?page=flow_chart),可透过本局的网页查阅。这包括一个交互式显示,指导研究人员找到适当的解决方案,并提供单个工具的关键特性和性能的详细描述,使处理管道能够做出明智的决策(图2)。1).为了配合该工具,在这篇综述中,我们提供了脂质组学工具指南和列出的软件的全部细节,以及个人开发人员关于每个工具的主要和次要应用程序的实际建议。中提供了两个教程补充说明举例说明不同工具的互操作性,例如针对性和非针对性脂质组学实验。

每个任务都由一个可单击的按钮标记,以将用户重定向到相应工具及其描述的列表。
在lipomaps网站上,这些工具以交互式流程图的形式表示(https://www.lipidmaps.org/resources/tools?page=flow_chart),涵盖了可用的、开放的解决方案,由图形用户界面(GUI)支持,适用于不同类型的脂质组学衍生数据集。这是集成到脂质地图的链接,描述,视频教程,以及软件开发人员的联系方式。新工具全面覆盖了脂质组学数据处理的七个主要领域:(1)面向脂质的数据库;(2) MS数据库;(3)针对性脂质组学数据集分析;(4)从非靶向脂质组学数据集中进行脂质鉴定和(5)定量;(6)统计分析与可视化;(7)数据集成方案(图。2).为了支持脂质组学分析师做出明智的决策,每个软件都提供了简短的描述,强调了主要功能和应用领域,然后是“技术信息”和“特定任务信息”选项卡下列出的具体功能(图2)。3.而且4).此外,用户可以使用“工具概述”选项卡查看给定部分中每个工具可用功能的简化表格表示。

这些包括(1)面向脂类的数据库,(2)质谱数据库,(3)针对性脂类组学数据集分析,(4)脂类识别,(5)非针对性脂类组学数据集量化,(6)统计分析和可视化,以及(7)数据集成解决方案。

每个工具都有三个部分:“描述”部分是对工具的简要介绍,“技术信息”部分列出从链接到兼容文件格式的所有基本技术信息,以及“任务特定信息”部分,其中包含为相应任务量身定制的详细功能。将鼠标悬停在带下划线的文本字段上,将显示该节的进一步特性。

每个工具都有三个部分:“描述”部分是对工具的简要介绍,“技术信息”部分列出从链接到兼容文件格式的所有基本技术信息,以及“任务特定信息”部分,其中包含为相应任务量身定制的详细功能。将鼠标悬停在带下划线的文本字段上,将显示该节的进一步特性。
在“技术信息”部分,用户可以查看分发该工具的许可证类型、桌面和/或基于web的界面的可用性、数据输入/输出格式以及与不同操作系统(例如Windows、Linux、macOS)的兼容性。还有通过可点击的链接访问的信息,允许下载该工具以及相关文档、用户指南和培训数据集。其他字段列出了如何通过命令行或API接口使用该工具,以便高级用户构建自己的定制管道。“任务特定信息”选项卡将用户导航到描述特定任务的软件功能的页面,涵盖上面概述的七个领域(图7)。1而且2).一些综合工具将多个功能集成到一个组合包中,并且可以针对广泛的工作流进行配置。这些工具被分配给每个任务,并相应地进行了相关描述,工具列表显示在表中1.在下一节中,我们将提供关于每个领域及其相关软件和工具的更多详细信息。
脂质组学工具的类别
Lipid-oriented数据库
对于那些旨在识别生物样本中存在的特定分子的研究人员来说,从历史和新出版物到有组织的存储库的单个脂质结构的数据库是必不可少的。数据库还作为许多数据分析管道的基础,以及脂质研究的关键知识库。在过去的5-10年里,使用MS和串联MS (MS/MS)生成的脂质组学研究数据集的规模大幅增加,其常规分析需要自动化编程方法来实现数据库搜索。为了支持选择适合特定应用的数据库,“面向脂类数据库”部分中的“任务特定信息”选项卡提供了数据库功能的概述,包括包含的脂类结构的数量、结构本体、覆盖的脂类(子)类、管理和注释级别。描述了支持数据可搜索性和实用性的自动化方法,包括使用的标识符,结构表示,谱库的可用性,以及可用时计算的物理化学性质。
使用最广泛的脂类数据库是由lipomaps和swissliids提供的。脂质图谱拥有多个数据库,其中脂质结构根据脂质图谱的命名和分类进行了编目22,23,24.具体的数据库为不同的用例提供了实用程序,如下所示。脂质图谱结构数据库(LMSD)22包含超过47,000种脂类(2022年8月),这些来源包括脂类MAPS联盟进行的实验工作、其他脂类数据库、科学文献,以及一些根据哺乳动物脂类中常见的脂肪酸链计算生成的脂类。LMSD可以根据Liebisch等人描述的速记命名法,为MS数据返回体积(脂质种类)注释。24,或完全注释的名称(结构定义的脂类),其中用户已经有额外的结构信息,例如从MS/MS实验。LMSD最近实现了通过生化转化将脂类连接在一起的反应数据显示。这最初是从土卫五获得的25, WikiPathways26, Reactome27,以及其他来源,现在已经适用于许多普通脂类。这是在被级联到单个脂质物种的过程中。在(高分辨率)MS实验的情况下,用户可能只有关于的信息米/z脂离子检测值。在这种情况下,搜索数据库将提供元素组成的信息,并使用这些信息生成假定的匹配。建议使用脂质地图上的BULK搜索工具来执行此操作,因为第一步将返回简略的命名法。以质谱为基础的假定匹配表明了脂肪酰基链和双键或环中存在的碳的数量,但不包括这些碳在分子中酰基链之间或内部的分布情况。对于一些用户,脂质地图计算生成的大块脂质(COMP_DB)22可能是一个更适合查询的资源。该数据库以速记形式包含超过59,000种脂类(在主要类别中,如脂肪酰基,甘油和甘油磷脂,固醇和鞘脂),从常见的酰基和烷基链列表中计算生成。这个数据库中的大多数条目表示分层结构,可以映射到许多不同的特定注释。硅质结构数据库(LMISSD)中的脂质图谱22包含超过110万个条目,来自对常见脂类的头组和链的计算扩展。它们是作为特定的结构注释提供的,但也可以作为和组合和链组合的层次结构提供。最后,脂质组离子迁移数据库22是用麦克林和格里芬实验室的数据开发出来的28,29,30.为漂移管质谱实验提供碰撞截面测量。
SwissLipids知识库31开发的目的是帮助脂质组学研究人员解释实验数据集,并将其与先前的生物学知识相结合,还可以进行数据探索和假设生成。在SwissLipids中,使用ChEBI从同行评审的文献中策划了实验表征的脂类32本体(https://www.ebi.ac.uk/chebi/).使用Rhea知识库描述脂质代谢25生化及转运反应(https://www.rhea-db.org),它本身是基于ChEBI的,而酶、转运蛋白和相互作用的蛋白质是使用UniProt知识库UniProtKB描述的33(https://www.uniprot.org),其中Rhea是此类注释的参考词汇34.由于实验表征的脂质结构的数量只代表了自然界中可能存在的可能结构的一小部分,因此使用ChEBI、Rhea和UniProt中专家策划的脂质结构和代谢知识来设计和创建一个包含所有理论上可行的硅质脂质结构的库,该库完全映射到这三种资源。当前版本的SwissLipids库包含来自550多个脂类的近600,000个脂类结构,分为两个不同的脂类等级分类-一个与脂类地图的结构分类平行35一种是基于MS数据的速记符号36它将基于ms的实验中的脂质鉴定与结构和生物学知识联系起来。
MS数据库
使用免费存储库服务进行原始和/或处理数据沉积,虽然多年来一直是蛋白质组学领域发表结果之前的标准任务,但现在才进入脂质组学社区37.MS数据存储库增加了数据的透明度和可重复性,允许对新发现和数据驱动的假设生成进行重新分析,以及对新软件工具进行基准测试38.虽然有许多平台可以上传原始MS数据集(例如MassIVE (https://massive.ucsd.edu/)、蛋白质交换(http://www.proteomexchange.org/)),支持元数据、样本准备协议和数据矩阵的特定功能是必要的,以根据FAIR原则提高存储数据集的可重用性39.要为数据上传或下载选择最优解决方案,用户需要了解存储的原始数据、处理后的元数据和元数据的类型、管理策略、可用数据集的总数和物种覆盖范围。
代谢组学和脂质组学数据库,如代谢组学工作台40和MetaboLights41具有将存储的数据与复合查询结果相关联的功能,以增强数据集的可重用性,允许进一步查询。每个数据集都有一个唯一的项目登录ID,有足够的空间存放原始和/或处理过的数据,并有详细的信息支持,包括研究设计、相关元数据、样本制备的详细信息和分析协议。数据集可以通过特定的关键字、起源生物和报告的化合物来浏览和搜索,并且通常与源出版物相关联。MetaboLights具有独特的数据转换和代谢物识别字段,并提供在线查看器来查看脂类标识符、数量和相应的结构,而Metabolomics Workbench与RefMet捆绑在一起42数据资源(包含超过160,000注释代谢物物种,包括大量的脂类收集)和一套在线数据分析工具。MetaboLights和Metabolomics Workbench被主流期刊接受为脂质组学数据集出版物的数据库。
针对性脂质组学数据集分析
脂质组学数据采集策略一般可细分为目标工作流和非目标工作流。在靶向脂质组学中,具有已知质量电荷比(米/z)的前体和片段/产物离子(s)需要由用户在数据采集前提供。此外,必须对每对前体产物离子(所谓的“过渡”)的电离和质谱参数进行优化,以优化方法的灵敏度。在三重四极杆仪器上使用单个或多个反应监测(SRM, MRM)以及最近在轨道rap和四极杆飞行时间仪器上使用平行反应监测(PRM)的目标分析已成功应用于选定的脂类组以及大样本队列中的数百种脂类(例如,在一次液相色谱(LC) -质谱/质谱分析中使用超过600种脂类)的定量43).然而,为了在相应的大样本队列中量化大量的脂质,有针对性的脂质组学工作流程应该快速建立,所获得的结果应该易于检查和验证。这个过程可能非常耗时,而且通常是非专家无法访问的。因此,可以使用专门的工具来促进方法设计和数据处理步骤。对于软件辅助方法设计,用户应定义计划的目标采集方法类型(SRM/MRM或PRM)和目标覆盖的脂类(亚)类/种。过渡的选择可以通过实验验证或计算优化来完成,甚至可以根据脂类特定气相裂解化学的常识进行实时预测。这组片段离子和它们的产率很大程度上取决于类别、双键的数量和脂肪酰的长度,甚至是获取数据的仪器的类型。例如,使用LipidCreator44目标检测可通过三个步骤生成。简而言之,在步骤1中,用户将选择要使用的脂类类别和类别,并定义脂酰、双键、羟基和加合物约束(前体选择)以及极性模式,以分析感兴趣的脂类。在步骤2中,可以定义MS/MS级别上被监视的片段。在步骤3中,可以将设计的分子添加到目标列表中,审查,并转移到MS仪器进行数据采集。METLIN-MRM45是另一个数据丰富的资源,用户可以在其中选择实验和/或计算优化的转换,甚至是带有相应doi链接的公共存储库转换。
虽然方法设计需要仔细优化,且耗时,但目标脂组学数据集的采集后数据处理相对简单,并遵循蛋白质组学和代谢组学学界公认的基于LC-MS / ms的目标量化的一般规则。事实上,一些最初为靶向分析多肽(Skyline)或代谢物(XCMS-MRM)而开发的开放获取工具已经适用于脂质组学应用。因此,LipidCreator与Skyline完全集成46对于小分子,使其成为一个独立于供应商的软件。metlin - mrm辅助方法的开发可以直接扩展到使用XCMS-MRM的采集后数据处理45平台。Skyline和XCMS-MRM工具都为峰值集成、相对和绝对量化以及数据质量控制提供了自动化解决方案。
从非靶向脂质组学数据集中鉴别脂质
脂质组学中常用的第二种分析策略与基于数据依赖(DDA)或数据独立采集(DIA)的无目标工作流有关。在这里,用户在所谓的“发现”模式下对脂质组进行质谱分析,而无需事先了解样品中要分析的确切脂质组。一般来说,非靶向脂质组学的主要目的是分析并理想地识别尽可能多的脂质物种(最终从样品中提取所有可电离成分)。DDA和DIA实验都依赖于仪器周期的迭代,包括MS1调查扫描(通常在高分辨率下获得,以确定脂离子的元素组成)和许多质谱/质谱,其中脂离子是根据其丰度(DDA)或给定范围内选择的米/z范围(DIA),发生碰撞诱导解离(CID)。然后使用MS/MS信息根据已知的气相破碎模式将脂类分配到特定的分子物种。因此,非靶向脂质组学实验可以在不同的结构分配水平上支持脂质鉴定,高分辨率质谱仅提供脂质的元素组成,从而提供推定的脂质体组成(例如,PC 36:4),但附加的质谱/质谱信息支持在分子物种水平上鉴定脂质(例如,PC 16:0_20:4)。虽然这可以通过手动检查MS和相应的MS/MS谱来实现,但脂质鉴定需要自动化解决方案来支持分析吞吐量,因为在常用的LC-MS /MS DDA设置中,单个分析中会生成数千个单独的MS/MS谱。
由于非靶向脂质组学工作流程的高需求和普及,已经开发了许多工具来支持这一领域。因此,非靶向脂质组学的交互式图表部分由9个可供学术用户开放访问的软件工具表示。通过点击相应的“特定任务信息”选项卡,用户可以熟悉只支持特定获取策略的工具,而不是覆盖更大应用领域的其他工具。为了支持最佳识别工具的选择,用户可以在高分辨率MS应用程序(脂质数据分析仪(LDA))之间进行选择47, LipidFinder48, MS-DIAL49, XCMS在线50), dda (lda51,52, MS-DIAL, LipidHunter253, LipidXplorer54, Lipostar255和MZmine56,57,58DIA (MS- dial和Lipostar2),甚至使用离子迁移率方法获得的数据集,提供正交LC-MS /MS分离(MS- dial, MZmine, Lipostar2)。此外,LDA可以支持对氧化脂质鉴定的血脂组学数据集的分析59, Lipostar2, LPPtiger60,以及MS-DIAL工具。对于上面列出的每个特定应用程序,“任务特定信息”选项卡提供了关于操作和评分的主要原则以及准确性测量的信息。
来自非靶向脂质组学数据集的脂质定量
脂质的定量提供了它们在生物样品中的丰度(相对或绝对),以便与其他样品进行比较。量化值有助于协调脂质组学数据集。定量分析可以使用从目标和非目标方法获得的数据进行,而不管它们是使用Full-MS、DDA或DIA模式获得的。非靶向脂质组学定量可细分为相对(例如,条件1和条件2之间的倍数变化)和半绝对(例如,以pmol μg表示)−1的蛋白质)。由于天然脂质组中脂质结构的多样性非常大,而商业上可用的脂质标准数量相对有限,因此在真正的脂质组水平上进行绝对定量是不可行的61,62.另一方面,由于来自同一子类的脂类在电离和质谱行为上非常相似,目前认为每个子类使用一个或少量的内部标准是一种折衷方案。同位素校正算法可以在数据处理过程中使用,以尽量减少内部标准和单个脂质分子物种之间的结构差异的影响63.脂质对于准确识别来说是一个特别的挑战,因为在相对狭窄的范围内分布着数百种脂质米/z范围(例如,从400到900米/z),以及大量等压甚至同分异构体物种。此外,在天然脂质组中检测到的脂质在很大的动态浓度范围内。这些问题给精确的峰值分配和积分以及下游的精确量化带来了重大挑战62.处理定量脂质组学数据集的工具受益于先前为定量蛋白质组学和代谢组学设计的软件解决方案。然而,由于脂类的特殊性质如上所述,需要进一步优化以确保脂组学数据处理的准确性。例如,引入了使用一组预先配置的内部标准(例如Lipostar2和MS-DIAL)进行数据规范化,以简化规范化过程并减少数据矩阵的后处理。此外,鲁棒峰值选取和峰值边界选择算法对于获得精确的定量分析峰值面积至关重要。虽然有几种鲁棒的峰值提取算法,但由于等压和同分异构体物种数量多,通常需要手动调整和重新整合。在数据处理工具中集成的其他功能,如峰对准和反褶积,对于处理具有多种加合类型的脂类和处理DIA数据集很重要。目前可用的定量工具,如LDA, Lipostar2, MS-DIAL, MZmine和XCMS在线通常提供从脂质鉴定到定量的集成管道,包括基本的归一化功能。对于每个工具,血脂组学工具指南中的“任务特定信息”部分显示了多种功能,以指导根据用户要求选择工具,包括量化方法和准确性测量的详细信息。
脂质组学数据集的统计分析和可视化
脂质组学研究产生了大量的数据集,实验设计的复杂性也在增加。因此,脂质组学数据处理的一个关键瓶颈通常是统计分析,这需要广泛使用考虑脂质数据特定特征的定制方法。不同的方法可用于脂质组学数据的分析,每一个都有自己的优点和缺陷。要应用的统计方法的选择应首先以脂质组学研究的目的为指导。当需要测试预定义组之间的统计显著性时(例如,健康与疾病),通常通过应用参数来评估样本组之间的差异(例如,t-检验,方差分析)或非参数(例如,Wilcoxon符号秩检验,Kruskal-Wallis)统计假设检验64.在一些脂质组学实验中考虑了数千种脂质,大量的变量增加了发现虚假相关变量(假阳性)的机会。因此,需要对多重比较测试进行校正。此外,在脂质组学中,变量(脂质)通常并不都是真正独立的(例如,一种脂质可以由几个离子或加合物表示),这意味着通常应用于基因组学/转录组学的修正,如Bonferroni或Benjamini-Hochberg可能明显矫枉过正。在这里,温和的修正,如顺序拟合优度,代表了一种可能更合适的替代方法65.
另一个需要考虑的问题是,检测到的特征可能并不总是遵循正态分布66.因此,在脂质组学中广泛应用多元统计方法,即同时考虑所有变量,通常假设它们是相关的而不是完全独立的。为了探索目的,主成分分析(PCA)67代表了组学中最广泛使用的方法,包括脂质组学68.使用PCA,原始数据集表示在一个低维子空间中,该子空间维护了大多数相关信息(方差)。作为一种无监督的方法,PCA不需要数据集的先验知识,不仅可以用于探索最终形成的样本集群,还可以用于解释,而不需要对分类或集群关联施加任何信息。分层或非分层聚类方法的目的是通过相似度对样本进行分组,相似度是利用样本之间的统计距离或相似度来衡量的69.用于降维的监督回归算法,如线性判别分析70,71或者偏最小二乘判别分析72,73,也可用于评估和分类样本的身份。除了偏最小二乘法,其他机器学习方法也被用于脂质组学的应用。其中,支持向量机等监督方法74随机森林75用于分类目的,也可以用于特征选择。尽管统计工具广泛应用于脂质组学,几个潜在的问题需要考虑。例如,在大型研究中,所谓的“批量效应”可能会妨碍统计分析,在应用统计工具之前必须使用内部标准和/或质量控制进行校正。此外,分子浓度低于检测限导致的数据缺失在脂质组学中非常常见,这可能不利于模型的生成和解释,有些工具比其他工具更敏感68.然而,对于缺失数据的补充,已经提出了几种策略76.
一般来说,上述定量脂质组学的多功能工具都提供了统计分析和数据可视化的集成平台(LDA、Lipostar2、MS-DIAL、MZmine和XCMS在线)。此外,还专门开发了一些工具来支持化学计量学分析和代谢组学和脂质组学数据的结果可视化(脂质地图统计分析工具)77和MetaboAnalyst 5.078).集成的统计分析和可视化功能可以方便地访问最常见的函数,包括单变量(参数和非参数测试)以及多变量(无监督和有监督)解决方案,与相应的脂质定量数据矩阵具有密切的交互连接,并且通常与数据预处理捆绑在一起,包括规范化、缩放和过滤数据子集的可视化。专用工具(脂质地图统计分析工具和MetaboAnalyst 5.0)可能需要研究人员根据数据集导入的特定模板转换量化数据,但可以提供更广泛的统计和可视化功能,并提供详细的可定制配置。例如,MetaboAnalyst 5.0有一个专门用于批量效应校正的实用程序,其中包含9种代谢组学领域公认的方法,以及8种缺失值计算方法79.
数据集成解决方案
许多脂质组学研究的最终目的是探讨特定生物条件下脂质组重塑的生物学相关性和机制。考虑到脂质组学实验产生的“大数据”的性质,人工评估所获得结果的生物学意义将非常耗时,并且需要在生物化学和细胞生物学的各个领域拥有广泛的知识。这种先进的数据集成远远超出了单一的脂质组学数据矩阵,并扩展到使用策划路径或网络分析策略的相关多组学方法。来自不同来源的多组学数据的组合和利用需要复杂的数据预处理,包括人工管理和先进的生物信息学解决方案。这种工作流程一般分为三个步骤:将脂类注释转换为知识和本体数据库中相应的id、脂类本体丰富和高级通路/网络分析。
能够将纯脂组学软件支持的脂质注释与数据集成工具中的结构或功能id连接起来的工具,为脂组学数据集的系统生物学集成提供了关键的第一步。为了减少ID交叉验证和数据库查询的复杂性,可以使用一些工具来帮助这种转换(gosling . xml)80, LipidLynxX81,和RefMet42),并将脂质标识符链接到各种数据库(BridgeDb82, Goslin, LipidLynxX和RefMet)。例如,BridgeDb有到其他数据库的近19,000个脂质地图标识符的映射(https://doi.org/10.6084/m9.figshare.13550384.v1).
脂质组学数据的生物学解释往往是由对单个脂质的关注驱动的。虽然这种方法在生物标记物发现中很有用,但它掩盖了与生物现象相关的分子共享特性的可能影响。避免这种情况的一种方法是手动管理具有特定属性的脂类组(例如,脂类,不饱和水平)并报告汇总统计数据。然而,由于脂类命名的模糊性,手动构建这些组通常是费力的,并引入了选择性的风险。本体论、概念的形式化及其关系在其他组学领域已取得成功,为构建具有共同生物学特性的分子组提供了框架。对于脂质组学数据,有几种本体,如脂质本体(LION/Web)16和脂质Mini-On83,有助于生物学解释。目前,LION将超过50,000个脂类链接到化学(例如,脂类MAPS分类和脂肪酸关联)、物理化学(例如,膜流动性和固有曲率)和细胞生物学(例如,主要亚细胞定位)特性,而脂类Mini-On使用文本挖掘策略将脂类本体结构术语归因于脂类。
通常,使用富集分析方法分析本体论衍生的分子组(“术语”)。在这些分析中,如果属于该术语的分子在目标列表中过度表示,或者在统计数据排序的分子列表中排名较高(例如,折叠变化和P价值)比预期的偶然。LION/web和脂质Mini-On都是免费的在线工具,可以对用户提供的脂质组数据进行本体术语富集分析。LION/web允许包含特定的LION术语类别进行分析。提交后,LION/web报告描述性匹配统计数据和充实分析,以及可供出版的数据。传统上,富集分析比较两组样品。为了分析更多样本组的数据集,LION/web最近扩展了PCA-LION热图模块。该模块生成一个热图,显示所有样品在给定数量的主成分富集分析的基础上最动态的lion术语。显著富集项的脂质id可以进一步映射到可用的通路和网络,以研究系统水平的变化。脂质Mini-On能够通过结构特征生成各种脂质富集的可视化。脂类及其相关的脂类本体术语可以可视化为一个网络,以对所执行的富集进行分层解释。
有几种工具可用于支持脂质组学数据集的通路和网络分析,包括Lipostar2中的集成通路图分析模块和独立的web应用程序BioPAN84,它允许在已知生物合成途径的背景下可视化定量脂质组学数据,以及由WikiPathways上的脂质门户所代表的社区驱动途径的中心枢纽26,与脂质地图合作。虽然有经验的生物信息学家可以通过高度定制的程序和脚本执行更高级的分析,但这些工具为研究人员提供了简单的接口,可以开始绘制脂质组学数据,以从预定义的通路和网络(例如PathVisio)中获得必要的脂质中心分析结果85和Cytoscape86.此外,维基路径中的路径可以通过维基路径应用程序轻松转换为网络87之后,这些网络可以通过CyTargetLinker扩展额外的知识,如微rna、转录因子或药物88应用程序。
结论
脂质组学是一个快速发展的领域,越来越多地支持对高复杂性的更大数据集的分析。为了帮助高通量数据处理,学术研究人员开发了许多新的软件工具,现在可以在开发人员的网站上公开使用。为了指导用户并为找到这些工具提供一个接触点,在这篇综述中,我们提供了最广泛使用的脂质组学软件包的详细规范,以及在lipomaps上可用的补充交互式脂质组学工具指南。提供了两个教程补充笔记举例说明指南的互操作性,以及如何结合不同的工具进行有针对性和无针对性的脂质组学实验。该门户可以帮助研究人员构建一个完整的脂质组学数据分析工作流程,从脂质识别和量化开始,直到使用开放访问软件解决方案和可点击的图形用户界面进行高级可视化和数据集成。脂质组学工具指南将定期审查和更新,以反映该领域的新发展以及对所列工具的持续支持。此外,本指南可以根据本资源范围内软件作者的要求进行更新。脂质图谱互动脂质组学工具指南(https://www.lipidmaps.org/resources/tools?page=flow_chart)总结了每种工具的基本信息,以帮助脂质组学初学者以及高级数据科学家在ms衍生脂质组学数据处理的每个步骤中选择最合适的工具。
参考文献
温克,m.r.脂质组学的新兴领域。Nat. Rev.药物发现4, 594-610(2005)。
杨凯,韩欣。脂质组学:生物医学科学相关的技术、应用和结果。学生物化学的发展趋势。科学。41, 954-969(2016)。
阿尔茨海默病的脂质组学研究现状。阿尔茨海默氏症。4, 1-10(2012)。
米克尔,P. J.,黄,G., Barlow, C. K. & Kingwell, B. A.脂质组学在糖尿病和心血管疾病风险预测和治疗监测中的潜在作用。杂志。治疗143, 12-23(2014)。
杨,L.等。脂质组学在疾病研究中的最新进展。J. Sep科学39, 38-50(2016)。
沃森博士专题回顾系列:代谢和心血管疾病的系统生物学方法。脂质组学:生物系统中脂质分析的全球方法。脂质Res;47, 2101-2111(2006)。
胡,C.等。脂质组学分析策略及其在疾病生物标志物发现中的应用。j . Chromatogr。B877, 2836-2846(2009)。
脂质组学:掌握脂质多样性。细胞生物学。11, 593-598(2010)。
Vvedenskaya, O.等。用肝脏脂质组学对非酒精性脂肪肝进行分层。脂质Res;62, 100104-100105(2021)。
Vvedenskaya, O., Wang, Y., Ackerman, J. M., Knittelfelder, O. &舍甫琴科,a .人体血脂组学中的分析挑战:通往真理的曲折之路。趋势肛门。化学。120, 115277(2019)。
杜辛,M.等人。脂肪细胞衍生的细胞外囊泡亚型的特征鉴定了大小细胞外囊泡的不同蛋白质和脂质特征。j . Extracell。囊泡6, 1305677(2017)。
杜根等人。非典型自噬驱动替代ATG8偶联磷脂酰丝氨酸。摩尔。细胞81, 2031-2040(2021)。
庄,等。生物钟成分BMAL1和rev - erba调节黄病毒复制。Commun Nat。10, 1-13(2019)。
张杨,等。脂质双分子层中均戊聚5-HT3A血清素受体的不对称开放。Commun Nat。12, 1-15(2021)。
Saud, Z.等。SARS-CoV2包膜不同于宿主细胞,暴露促凝脂质,并在体内被口腔冲洗破坏。脂质Res;63, 100208(2022)。
莫雷纳,m.r.等人。LION/web:基于web的脂质组数据分析本体丰富工具。Gigascience8, 1-10(2019)。
卢,R. J.等。原发性小鼠中性粒细胞的多组学分析预测了与性别和年龄相关的功能调节模式。Nat老化。1, 715-733(2021)。
格林,C. L.等。性别和遗传背景决定了蛋白质限制的代谢、生理和分子反应。细胞金属底座。34, 209-226(2022)。
拜尔,B. A.等。基于代谢组学的代谢物的发现,增强少突胶质细胞成熟。Nat,化学。医学杂志。14, 22-28(2017)。
拉普兹,L.等人。SpaceM显示单细胞代谢状态。Nat方法。18, 799-805(2021)。
Patti, G. J.等。代谢组学提示神经病变性慢性疼痛中鞘脂改变。Nat,化学。医学杂志。8, 232-234(2012)。
Sud, M.等。LMSD:脂质地图结构数据库。核酸测定。35, d527-d532(2007)。
Fahy, E.等人。脂类综合分类系统的更新。脂质Res;50, s9-s14(2009)。卷。
Liebisch, G.等人。最新的脂质MAPS分类,命名法和ms衍生脂质结构的速记符号。脂质Res;61, 1539-1555 (2020).
班萨尔,P.等人。Rhea, 2022年的反应知识库。核酸测定。50, d693-d700(2022)。
马丁斯等人。维基路径:连接社区。核酸测定。49, d613-d621(2021)。
Gillespie, M.等人。反应组途径知识库2022。核酸测定。50, d687-d692(2022)。
斯托,S. M.等。漂移管离子迁移率-质谱碰撞截面测量的实验室间评估。分析的化学。89, 9048-9055(2017)。
Hinz, C.等人。一种全面的UHPLC离子迁移率四极子飞行时间方法,用于类二十烷磺酸,其他氧脂素和脂肪酸的分析和定量。分析的化学。91, 8025-8035(2019)。
Leaptrot, K. L., May, J. C., Dodds, J. N. & McLean, J. A.离子迁移构象脂谱高置信度脂组学。Commun Nat。10, 985(2019)。
Aimo, L.等人。SwissLipids脂质生物学知识库。生物信息学31, 2860-2866(2015)。
黑斯廷斯等人。2016年ChEBI:改善服务和扩大代谢物收藏。核酸测定。44, d1214-d1219(2016)。
贝特曼等人。UniProt: 2021年的通用蛋白质知识库。核酸测定。49, d480-d489(2021)。
莫加特等人。利用Rhea对UniProtKB进行酶注释。生物信息学36, 1896-1901(2020)。
Fahy, E.等人。脂类的综合分类系统。脂质Res;46, 839-861(2005)。
Liebisch, G.等人。质谱法得出的脂质结构的简写符号。脂质Res;54, 1523-1530(2013)。
奥唐纳,V. B.等人。迈向生物医学研究出版物中脂质组质谱最低报告标准的步骤。循环:染色体组。摘要。地中海。13, e003019(2020)。
Tsugawa, H.等。质谱数据存储库增强了新的代谢物发现与计算代谢组学的进步。代谢物9, 119(2019)。
威尔金森,m.d.等人。科学数据管理和管理的FAIR指导原则。科学。数据3., 160018(2016)。
Sud, M.等。代谢组学工作台:代谢组学数据和元数据、代谢物标准、协议、教程和培训以及分析工具的国际存储库。核酸测定。44, d463-d470(2016)。
Haug, K.等人。代谢:一种资源的发展,以响应其科学界的需求。核酸测定。48, d440-d444(2020)。
Fahy, E. & Subramaniam, S. RefMet:代谢组学的参考命名法。Nat方法。17, 1173-1174(2020)。
黄恩,K.等。高通量血浆脂组学:与心脏代谢危险因素相关的详细图谱。细胞化学。医学杂志。26, 71 - 84。e4(2019)。
彭,B.等。LipidCreator工作台,以探测脂质组学景观。Commun Nat。11, 1-14(2020)。
Domingo-Almenara, X.等人。XCMS-MRM和METLIN-MRM:用于小分子定向分析的云库和公共资源。Nat方法。15, 681-684(2018)。
亚当斯,K. J.等。小分子Skyline:定量代谢组学的统一软件包。J.蛋白质组。19, 1447-1458(2020)。
哈特勒,J.等人。脂质数据分析仪:在LC-MS数据中对脂质进行无人值守的鉴定和定量。生物信息学27, 572-577(2010)。
Fahy, E.等人。脂质图谱的LipidFinder:峰值过滤,质谱搜索和脂组学的统计分析。生物信息学35, 685-687(2018)。
Tsugawa, H.等。MS-DIAL 4中的脂质组图谱。生物科技Nat。》。38, 1159-1163(2020)。
Tautenhahn, R, Patti, G. J., Rinehart, D. & Siuzdak, G. XCMS在线:一个基于web的平台来处理非靶向代谢组学数据。分析的化学。84, 5035-5039(2012)。
哈特勒,J.等人。基于平台无关的决策规则破译脂质结构。Nat方法。14, 1171-1174(2017)。
哈特勒,J.等人。鞘脂的自动注释,包括使用MS nData准确识别羟基化位点。分析的化学。92, 14054-14062(2020)。
Ni, Z., Angelidou, G., Lange, M., Hoffmann, R. & Fedorova, M. LipidHunter通过LC-MS和霰弹脂组学数据集的高通量处理来识别磷脂。分析的化学。89, 8800-8807(2017)。
赫尔佐格,R.等人。LipidXplorer:跨平台脂质组学软件。《公共科学图书馆•综合》7, e29851(2012)。
Goracci, L.等。脂质组学的综合平台中性化学信息学工具。分析的化学。89, 6257-6264(2017)。
Pluskal, T., Castillo, S., Villar-Briones, A. & oresitic, M. MZmine 2:用于处理、可视化和分析基于质谱的分子剖面数据的模块化框架。BMC Bioinf。11, 1-11(2010)。
Korf, A.等人。三维Kendrick质量图作为图形脂质鉴定的工具。快速Commun。质量范围。32, 981-991(2018)。
Korf, A., Jeck, V., Schmid, R., Helmer, P. O. & Hayen, H.通过扩展MZmine 2开源软件包自定义数据库在双键位置水平上注释脂质物种。分析的化学。91, 5098-5105(2019)。
Krettler, C. A., Hartler, J. & Thallinger, G. G. LC-MS脂质组学数据中氧化脂质的鉴定和定量。钉。健康抛光工艺。通知。271, 39-48(2020)。
Ni, Z., Angelidou, G., Hoffmann, R. & Fedorova, M. LPPtiger软件用于脂质组特异性预测和从LC-MS数据集中鉴定氧化磷脂。科学。代表。7, 15138(2017)。
王,王,M c &汉x选择的内部标准准确量化复杂的脂质物种在生物提取物通过电喷雾质量spectrometry-what,如何以及为什么?质量范围。牧师。36, 693-714(2017)。
Khoury, S.等。脂质量化:模型、现实和妥协。生物分子8, 174(2018)。
Lange, M. & Fedorova, M.使用HILIC和RPLC质谱对人血浆中NIST®SRM®1950代谢物进行脂质定量准确性评估。分析的Bioanal。化学。412, 3573-3584(2020)。
米勒,J. N.和米勒,J. C.。分析化学统计与化学计量学“,第四版,第七章(皮尔逊教育,2000)。
Carvajal-Rodríguez, A., de Uña-Alvarez, J. & Rolán-Alvarez, E.一种新的多测试校正(SGoF),在增加测试次数时增加其统计能力。BMC Bioinf。10, 209(2009)。
格里芬,J. L.利吉,S. &霍尔,Z. inLipidomics(编者格里菲斯,W.和王,Y.) 25-48 (RSC, 2020)。
Wold, S. Esbensen, K. & Geladi, P.主成分分析。Chemom。智能。实验室。系统。2, 37-52(1987)。
Checa, A. Bedia, C. & Jaumot, J.脂质组数据分析:教程,实用指南和应用。分析的詹。学报885, 1-16(2015)。
Kaya Gülağız, F. & Şahin, S.层次和非层次聚类算法的比较。Int。计算机工程师正,抛光工艺。9, 6-14 (2017)
米卡,S.,拉奇,G.,韦斯顿,J., Scholkopf, B. &穆勒,K. R. Fisher判别分析与核。在用于信号处理的神经网络- IEEE研讨会论文集(IEEE 1999)。
Tharwat, A., Gaber, T., Ibrahim, A. & Hassanien, A. E.线性判别分析:详细教程。AI Commun。30., 169-190(2017)。
Wold, S., Sjöström, M. & Eriksson, L. pls -回归:化学计量学的基本工具。Chemom。智能。实验室。系统。58, 109-130(2001)。
李,L. C., Liong, C. Y. & Jemain, a . a .用于高维(HD)数据分类的偏最小二乘判别分析(PLS-DA):当代实践策略和知识差距的回顾。分析师143, 3526-3539(2018)。
Cortes, C., Vapnik, V. & Saitta, L.支持向量网络。马赫。学习。20., 273-297(1995)。
随机森林。马赫。学习。45, 5-32(2001)。
格罗姆斯基,p.s.等人。缺失值替代对代谢组学数据多元分析的影响。代谢物4, 433-452(2014)。
Fahy, E, Sud, M, Cotter, D. & Subramaniam, S.脂质地图在线脂质研究工具。核酸测定。35, w606-w612(2007)。
庞,Z.等。MetaboAnalyst 5.0:缩小原始光谱和功能见解之间的差距。核酸测定。49, w388-w396(2021)。
Stacklies, W., Redestig, H., Scholz, M., Walther, D. & Selbig, J. pcamethods -一个为不完整数据提供PCA方法的Bioconductor包。生物信息学23, 1164-1167(2007)。
Kopczynski, D., Hoffmann, N., Peng, B. & Ahrends, R. Goslin:一个简洁的脂类命名法语法。分析的化学。92, 10957-10960(2020)。
Ni, Z. & Fedorova, M. LipidLynxX:支持大规模脂质组学数据集集成的数据传输中心。预印在bioRxivhttps://doi.org/10.1101/2020.04.09.033894(2020)。
丁,D.等。BridgeDb框架:对基因、蛋白质和代谢物标识符映射服务的标准化访问。BMC Bioinf。11, 5(2010)。
克莱尔,G.等。脂质Mini-On:用于脂质组数据富集分析的挖掘和本体工具。生物信息学35, 4507-4508(2019)。
高德等人。BioPAN:一个基于网络的工具,探索哺乳动物脂质组代谢途径的脂质地图。F1000Research10, 4(2021)。
库特蒙,等人。PathVisio 3:一个可扩展的路径分析工具箱。公共科学图书馆第一版。医学杂志。11, e1004085(2015)。
香农等人。细胞景观:生物分子相互作用网络集成模型的软件环境。基因组Res。13, 2498-2504(2003)。
Kutmon, M., Lotia, S., Evelo, C. T. & Pico, A. R. Cytoscape的WikiPathways应用程序:使生物途径符合网络分析和可视化。F1000Research3., 152(2014)。
Kutmon, M., Ehrhart, F., Willighagen, e.l., Evelo, c.t. & Coort, s.l. CyTargetLinker应用程序更新:Cytoscape中网络扩展的灵活解决方案。F1000Research7, 743(2019)。
确认
本出版物基于成本行动EpiLipidNET,泛欧脂质组学和Epilipidomics网络(CA19105;https://www.epilipid.net),由COST(欧洲科学技术合作)资助。我们非常感谢Wellcome Trust对lipomaps (203014/Z/16/Z)的资助。脂质地图感谢来自开曼化学公司、默克公司和阿凡提极地脂质公司的赞助。该项目由捷克科学基金会21-11563M资助。感谢FWF P33298-B和人类前沿科学计划RGP0002/2022的资助。“Sonderzuweisung zur Unterstützung profilbestimmender Struktureinheiten 2021”由SMWK和Deutsche Forschungsgemeinschaft (FE 1236/5-1 to M.F.)表示感谢。JSPS KAKENHI (21K18216 to H.T.),国家癌症中心研究和发展基金(2020-A-9, H.T.), AMED日本传染病研究和基础设施计划(21wm0325036h0001 to H.T.), JST国家生物科学数据库中心(NBDC to H.T.), JST ERATO“有田脂质组地图集项目”(JPMJER2101 to H.T.)。
作者信息
作者及隶属关系
贡献
这份手稿是由所有同意最终版本的作者共同撰写的。M.F.和V.B.O.构想了最初的想法并监督了这个项目。Z.N、m.f.和V.B.O.对工具和数据收集的回顾做出了贡献。m.f., Z.N和M.W.对数字有贡献。M.W.设计并测试了工作流程和教程。G.J, K.M.E和R.An。在Z.N.和M.F.软件开发商Z.N., R.Ah的帮助下开发了这个网站。,L.A., J.A.J., S.A., A.B., G.C.C., M.J.C., E.F., C.G., L.G., J.H., N.H., D.K., A.K., A.F.L., A.M., J.M.A., M.R.M., C.O., T.P., A.S., D.S, G.S., M.K., H.T., E.L.W., and J.X. contributed to sections on software tools in both the manuscript and website.
相应的作者
道德声明
相互竞争的利益
A.K.受雇于Bruker Daltonics GmbH & Co. KG,不来梅,德国。其他作者宣称没有竞争利益。
同行评审
同行评审信息
自然方法感谢匿名审稿人对本工作的同行评议所作的贡献。主要处理编辑:Arunima Singh,与自然方法团队。
额外的信息
出版商的注意施普林格自然对出版的地图和机构从属关系中的管辖权主张保持中立。
补充信息
补充信息
补充说明
权利和权限
根据与作者或其他权利持有人签订的出版协议,自然或其许可方(例如,社会或其他合作伙伴)对本文拥有排他性权利;作者对这篇文章接受的手稿版本的自我存档仅受此类出版协议的条款和适用法律的约束。
关于本文

引用本文
Ni, Z., Wölk, M., Jukes, G.;et al。指导脂质组学研究应用的信息学软件和工具的选择。Nat方法(2022)。https://doi.org/10.1038/s41592-022-01710-0
收到了:
接受:
发表:
DOI:https://doi.org/10.1038/s41592-022-01710-0
