







摘要
元数据描述了数据的来源、创建类型、结构、状态和语义等信息,是医疗数据保存和重用的前提。为了克服具有异构数据格式的不同数据源和存储库的障碍,启动了基于现有标准的元数据人行横道。包括FAIR原则,以及数据格式规范。元数据人行横道是医疗数据集成中心(MeDIC)和研究人员之间提供数据的基础,为研究设计和请求提供元数据信息的选择。基于人行横道,元数据项进行了优先级和分类,以证明没有一个预定义的标准满足MeDIC的所有要求,只有最大的元数据集适合使用。开发包含最大数据集的收敛格式是在MeDIC中自动转换元数据的预期解决方案。
简介
由于人类开始对信息和对象进行排序和分类,元数据提供了重要的信息对象对齐。元数据被定义为关于数据的数据1.它们描述了信息对象的来源、创建类型、结构、状态、级别和语义。信息对象可以是包含编码值或实例标识符的数据,也可以是几个日期的列表,或者是具有各种依赖关系的整个数据库1.通过元数据,相关数据可以被重用、组织、描述、验证、搜索和查询。在医疗领域,信息的提供、再利用和保存对于确保患者得到尽可能好的治疗以及回答研究问题至关重要。作为Hegselmann等.“具有非常特定特征的个体可以被识别出来,这对于个性化医疗、流行病学和临床研究来说是强制性的,但一般的大数据应用也将成为可能。”2.回顾性获得的数据,特别是在大量可用的情况下,不仅为预测而且为检测提供了机会,例如在个人层面上的新风险和治疗方案(精准医学)3..因此,从属元数据占主导地位,通过提供元信息来实现来自不同数据源的信息的链接,从而为组合和转换数据准备基础。这表明了元数据对医疗部门的好处。
2016年提出的公平原则4,表明(元)数据的重用在医学研究中是非常重要的。数据管理和相应的元数据应用为高质量的数据分析和后续高影响力的出版物提供了多种机会。研究数据的元数据也变得越来越重要,因为期刊越来越要求公开已发表研究的主要数据5.公平原则分为可查找性、可访问性、互操作性和可重用性。元数据在所有四个类别中都显式命名。因此,元数据是使信息可访问和可用的重要构建块。
然而,Dugas等.承认来自德国医疗保健研究的大多数表格和项目目录不符合这些公平原则,不容易找到,因此不可重复使用6.这是因为表单有时不允许发布,因为权限限制,或者它们不是基于互操作性的观点发布的,例如,没有标识号或附带的元数据,而是保存在纸坟墓中。如本文所述,发布带有数据的元数据非常重要,因为这是迈向开放数据的第一步6.
主要在生物医学领域,值得注意的是,过去和现在都有一些实现强调了元数据的重要性7.不同的联盟和工作组根据可重用性、可访问性和可查找性提供了利用元数据的方法8,9.上述两篇文章都采用了定性元数据有助于检索、获取和利用元数据的范式。工作组参考8提出了本体论概念注释元数据的潜力,使元数据更容易被找到并且具有特定的语义,从而形成资源内容的强大描述符。
Goncalves等.9开发了一个软件,可以从元数据记录中提取信息,并根据给定的规范(正确的格式和合法的内容)分析信息是否完整和正确。
来自异构源数据系统的数据集成是一个重大挑战,不仅在生物医学领域。最初,每个系统都有必须考虑的非常不同的元数据属性。所使用的数据结构是专门为各自的源数据系统设计的。由于专有原因,这可能使重用在特定源系统中收集的数据变得困难。
Canham和Ohmann将元数据分为两部分。一方面,存在固有的元数据,它是永久的、不可改变的10.例如,诸如日期/时间戳和执行临床医生的元数据,以及临床检查的状态(活动、推迟、完成),都被认为是内在元数据。
另一方面,它们标识表示本地化或历史的起源元数据,如数据生命周期状态(创建、处理、分析、保存、访问、重用)、数据保卫者或数据收集方法。出处元数据可能会发生变化,因为它的本质是提供关于非静态知识的信息。内在元数据和起源元数据都是搜索和唯一标识数据所必需的。常规临床实践中数据的可变性使得统一元数据模式的使用变得复杂,但Canham和Ohmann在“协议驱动的临床研究”中提出了一种通用的元数据方案,这将适用于任何信息系统。正如他们所指出的,如果数据和相应的元数据保持原始的关系形式,并使用解析器将其转换为所需的目标格式FHIR、openEHR或OMOP,则会更有益10.在各自标准的各个元数据元素之间进行适当的交叉,对于使用最多的元数据元素集获得尽可能细粒度的结果至关重要。
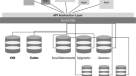
元数据收集描述了一个过程,将来自不同数据存储、档案或存储库的元数据组合起来,并将它们存储在中央数据库模式中。在这项工作中收集的数据来自大学医疗中心Göttingen (UMG)的医疗数据集成中心(MeDIC)。大学医疗中心是一家提供最大护理和广泛医疗数据来源的医院。MeDIC将来自医院信息系统和临床研究数据库(除其他外,包括来自研究和注册的数据,如病例报告表格、患者报告的结果或发现)的医疗信息及其相应的元数据连接到数据仓库中。它涉及来自不同(元)数据类型的数据集和纵向数据收集的数据,以及数据集成。数据和相应的元数据存储在关系数据库中,关系数据库是MeDIC数据仓库的基础。元数据保存在与数据分离的不同表中,通过主键/外键连接到数据表。因此,可以将元数据以相同的格式存储在一个n维存储库中。来自医院和部门信息系统的医疗源数据被假名化并转换为MeDIC的内部统一数据格式。在Extract-Transform-Load过程中收集元数据的过程中,元数据是通过特定于med的数据协议提取和加载的,从而防止重复。MeDIC的数据仓库期望将UMG的所有可用数据源作为正在进行的流程的一部分连接起来。
在本文中,我们的目标是提供上述格式之间的交叉,并尽可能准确地传达它们。
结果
为了本研究项目的目的,研究了数据格式CDISC、OMOP、openEHR和FHIR的规范。对于每一种数据格式,都会提取并对比所有相应的元数据项。
在元数据人行横道的概念之后,下一个阶段包括识别与MeDIC高度相关的元数据项。
考虑到文献研究的结果,例如FAIR原则和要求(这是MeDIC结构所固有的),决定了基本的元数据项。
在FAIR原则中,考虑了F1、F3、F4、A2、I3和R1.1原则,因为它们与元数据直接相关4.F1假设(元)数据必须分配一个全局唯一的持久标识符。F3涉及包含标识符的元数据,标识符清楚而显式地描述了相应的数据,而F4要求元数据在可搜索资源中建立索引。根据A2,元数据必须是可访问的,即使数据是不可获得的。I3包含元数据必须包含对其他元数据的限定引用。最后,R1.1建议在发布元数据时必须有一个清晰的、可访问的数据使用许可4.对MeDIC的需求来自于2019年MeDIC开发之初进行的需求分析。
表格4显示映射的结果矩阵,包括元数据项的优先级。
在无花果。1,针对各个数据格式计算优先级的分数,并在以下分组条形图中进行图形比较。

对MeDIC所需元数据进行定性优先级评分,定量覆盖FHIR、CDISC、OpenEHR和OMOP不同数据格式。
从前面的插图中可以看出,没有一种数据格式满足所有必需的医学固有标准。
如上所述,由于各个格式所基于的前提不同,因此不可能实现整个转换。例如,CDISC增加了结构,建立在ODM格式和形式的基础上,结合临床护理中的研究文档。另一方面,OpenEHR是为在EHR中存储医疗数据而设计的,而FHIR则用于不同机构之间的数据交换。而OMOP提供了一种通用的数据格式来统一来自不同数据库的数据。本文显示,没有一种数据格式包含所有元数据,而这些元数据是为了可靠的数据管理而成功地操作MeDIC所必需的。因此,我们提出了一种特定的收敛格式,它绕过了上述挑战。
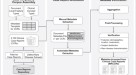
数字2通过提供OMOP和openEHR两种数据格式的摘录来显示一个示例。它说明了收敛格式如何合并不同格式的元数据项,并通过提供目标格式的元数据项(即使它不是源数据格式的一部分)来避免信息丢失。例如元数据项cdm_source_abbreviation在openEHR元数据中没有精确匹配。如果没有收敛格式,信息就会丢失,因为在转换之后,openEHR元数据项中将不再表示信息。

从OMOP和openEHR摘录元数据项的示例,展示了收敛格式如何在元数据转换期间避免信息丢失。虚线箭头表示具有null值的数据流。
另外,openEHR接受元数据项,例如resource_description:lifecycle_state和resource_description_item:language,它们在OMOP元数据中没有匹配项。当然,这两个元数据项不会在转换过程中创建,因为OMOP没有提供等效的结构。因此,如果源格式不提供任何输入值,收敛格式是提供和维护格式结构的最佳解决方案,方法是在转换过程中创建项并使用null值填充它们。
讨论
文献检索表明,元数据主题在医学和生物医学信息学中具有很高的重要性。然而,一个基本的问题是元数据的定义。乌尔里希等.检查了关于元数据定义和分类的文献,并指出了一个事实,即“元数据”这个术语没有明确的解释。此外,本文还展示了元数据的匹配、映射和转换的定义在文献中是如何不同的。总的来说,本文指出了对这一术语的不同理解可能导致的问题11.
一些作者先前展示了将单一数据格式转换为其他数据格式的可能性。但是,还没有执行元数据横行线中两种以上数据格式之间的转换。Doods, Neuhaus和Dugas的作品12以及Bruland & Dugas13例如,展示openEHR或FHIR转换为CDISC ODM的可能性。然而,在MeDIC中,既要考虑结构化数据,也要考虑非结构化数据和元数据,这与仅仅使用CDISC ODM作为目标格式相矛盾。
在医疗保健中使用不同的数据格式和相关的元数据格式会导致元数据项的异质性。这导致数据字段之间有时无法实现完全匹配,从而导致不平等。无论是数据格式支持不同的应用程序领域,还是它们在扩展的开发中允许不同程度的自由度。
本文中给出的结果表明,由于前面提到的元数据横行线的挑战,来自不同标准格式的元数据项满足了相互转换的要求,而很少进行调整。
下一阶段,我们会进一步发展汇流格式,并在不同数据格式与汇流格式之间建立自动人行横道。这种聚合格式既包括MeDIC固有的元数据项,也包括表中描述的四种数据格式的横行线中的所有项2.
为了能够以任何数据格式向研究人员提供元数据,医院信息系统中当前捕获的元数据与研究所需的衍生数据之间的差距是必需的,这一最大元数据项集将是必要的。此外,还必须评估收集的元数据的质量。如果向研究人员提供元数据,他们还必须确保它是高质量的,并允许安全的评估。因此,将制定一个质量评估方案。这种评估应该导致元数据质量的可视化,然后将其提供给研究人员。这种可视化使研究人员能够轻松地识别和评估数据质量以及数据是否适合此研究目的。
方法
文学研究
为了评估现有元数据标准的领域,通过Ovid使用PubMed和Embase进行了文献研究。
表格1.以PubMed为例,展示了文献检索的步骤和部分结果。该搜索结果与Embase中使用相同搜索策略的第二个搜索查询相结合。
为了充分选择和评估文献搜索的结果,文章提出了数据交换和处理所需的元数据(搜索标准一),以及(元)数据格式规范(搜索标准二),文章描述了已经存在的元数据交叉(搜索标准三)或将元数据格式转换/映射到另一个元数据格式的方法(搜索标准四),这些都被考虑在内。
在两个书目数据库中搜索得到517个结果,其中71个重复在Refworks中被自动删除,446个参考文献保留下来。通过扫描相关标题和摘要来检查每个结果的相关性。经过这次审查,剩下了60篇重要的文章,并获得了全文。在阅读全文后,有12篇文章被认为不适合本研究的目的。对所有收录文章的参考文献列表进行了扫描,以寻找进一步的重要出版物。最后,对其余的文章进行完整的研究,并根据用于选择、评估和优先排序文献搜索结果的搜索标准进行评估。建议的公平原则4以及所包含的数据格式的文档,其中核心满足了第一个搜索条件,而文档也满足了第二个搜索条件,并作为人行横道开发的序言。
Kock-Schoppenhauer等.Bruland和Dugas首次详细阐述了不同数据格式之间一对一的转换,与搜索标准3有关13,14.而15而且16提供了对人行横道的程序有根据的概述。
元数据人行横道
为了使数据集成中心收集的医疗数据可供研究人员使用,元数据应该以常用的数据格式进行访问。目前,MeDIC支持的数据格式包括OMOP、openEHR、FHIR和CDISC。这使得研究人员可以选择目标数据格式。为了实现这种选择,构建了一个元数据人行横道。
元数据人行横道包含一个图表或地图,它描述了来自不同标准或格式的元素,并将等效元素分组15.人行横道允许将元素从一种格式转换为另一种格式16.
表中描述了为这四种格式开发的元数据横行线的摘录2.完整的人行横道可在补充表中找到1在这份手稿的补充材料内。
在转换过程中,有时必须分离或合并来自输入格式的数据字段,以保留目标格式元数据的语义。
由于上述挑战,可能会发生信息丢失。为了避免这种情况,必须使用包含并存储最大元数据字段集的收敛格式。为了建立收敛格式,定义的元数据人行横道是这项工作的目标。
优先级
在执行人行横道之后,将标识对MeDIC特别重要的元数据项。这些元数据是根据文献回顾和数据格式规范确定的。然后,对符合MeDIC固有要求的项目进行分类。出于这个目的,我们选择了三个类别。第一类包括对医疗中心的运作和提供数据极为重要的项目。第2类包括中等重要性的对象,但对于数据隐私和同意是必需的。类别3由优先级最低的元数据组成,它们是附加上下文信息和语言规范的关键。相应项目的紧急情况不予考虑。因此,优先级维度只包括项目对MeDIC的重要性。
在确定优先级后,计算各个数据格式的分数,以显示哪些数据格式尽可能广泛地涵盖优先级类别1和2的项目。
表格3.显示标识的元数据项和相关的优先级。
优先级分为1、2和3类。类别1包含优先级最高的项目,而类别3包含优先级最低的项目。确定了19个元数据项目,这将有助于医疗中心在数据使用和交换方面的可持续性。由FAIR原则产生的元数据项目被赋予最高优先级,因为它对数据的可查找性、可访问性、互操作性和可重用性具有高度重要性。
然后将优先级到元数据项的映射应用于四种不同数据格式的元数据。
数据可用性
在本研究过程中产生或分析的所有数据均包含在本文中,并在17.
代码的可用性
在这项研究中没有使用自定义代码。
参考文献
秋雨,M。元数据简介第三版(盖蒂研究所出版计划,2016)
Hegselmann, S。等.将波美拉尼亚健康研究的元数据自动转换为原始数据管理。种马健康技术通知236, 88-96(2017)。
Hulsen, T。等.从大数据到精准医疗。地中海面前6(2019)。
威尔金森,M。等.科学数据管理和管理的FAIR指导原则。科学数据3., 160018(2016)。
Colavizza, G., Hrynaszkiewicz, I., Staden, I., Whitaker, K., McGillivray, B.链接出版物与研究数据的引用优势。《公共科学图书馆•综合》15(4)(2020)。
杜佳斯M。等.备忘录“开放元数据”。方法24(2015)。
Ohno-Machado, L。等.使用DataMed跨多个生物医学数据库查找有用数据。自然遗传学49(6), 816-819(2017)。
Ferreira, J. D. Inácio, B. Salek, R. M. & Couto, F. M.评估公共代谢组学元数据,以提高质量。integrr Bioinform14, 20170054(2017)。
Gonçalves, R. &穆森,M.生物医学实验中使用的生物样本元数据的可变质量。科学数据6, 190021(2019)。
Canham, S. & Ohmann, C.临床研究中数据对象的元数据模式。试用17, 557(2016)。
乌尔里希,H。等.理解元数据的本质:系统回顾。J医疗互联网服务24(1)(2022)。
杜德斯,J.,纽豪斯,P. & Dugas, M.将odm元数据转换为fhir问卷资源。种马健康技术通知228, 456-460(2016)。
Bruland, P. & Dugas, M. cdisc odm和openehr原型之间的转换。种马健康技术通知205, 1225(2014)。
科克-叔本华等.元数据标准兼容性:cdisc odm导入管道到sample .mdr。种马健康技术通知247, 221-225(2018)。
莱利,J。理解元数据(贝塞斯达,马里兰州:NISO出版社,国家信息标准组织,2004年)。
巴卡,M,吉利兰,A。元数据简介:通往数字信息的途径(盖蒂教育艺术研究所,2000年)。
Bönisch, C, Kesztyüs, D. & Kesztyüs, T.在临床护理中收集元数据:FHIR, OMOP, CDISC和openEHR元数据之间的十字路口。figsharehttps://doi.org/10.6084/m9.figshare.21333042.v1(2022)。
确认
作者承认从德国联邦教育和研究部获得了FAIRRMeDIC项目的资助,资助号01ZZ2012。本工作得到了大学医学中心医疗数据集成中心Göttingen的支持。
资金
由Projekt DEAL启动和组织的开放获取资金。
作者信息
作者及隶属关系
贡献
T.K.协调并监督了这个研究项目。C.B.进行元数据横过,促成了优先级分类和评分的实现,并撰写了初始稿件。D.K.和T.K.为研究的概念化做出了贡献,并参与了手稿的修订、编辑和最终批准。所有作者都阅读并批准了最终的手稿。
相应的作者
道德声明
相互竞争的利益
作者声明没有利益竞争。
额外的信息
出版商的注意施普林格自然对出版的地图和机构从属关系中的管辖权主张保持中立。
补充信息
权利和权限
开放获取本文遵循知识共享署名4.0国际许可协议(Creative Commons Attribution 4.0 International License),允许以任何媒介或格式使用、分享、改编、分发和复制,只要您对原作者和来源给予适当的署名,提供知识共享许可协议的链接,并注明是否有更改。本文中的图像或其他第三方材料包含在文章的创作共用许可中,除非在材料的信用额度中另有说明。如果内容未包含在文章的创作共用许可协议中,并且您的预期使用不被法定法规所允许或超出了允许的使用范围,您将需要直接获得版权所有者的许可。要查看此许可证的副本,请访问http://creativecommons.org/licenses/by/4.0/.
关于本文

引用本文
Bönisch, C, Kesztyüs, D. & Kesztyüs, T.在临床护理中收集元数据:FHIR, OMOP, CDISC和openEHR元数据之间的十字路口。科学数据9, 659(2022)。https://doi.org/10.1038/s41597-022-01792-7
收到了:
接受:
发表:
DOI:https://doi.org/10.1038/s41597-022-01792-7
