







文摘
在本文中,我们实现了一个大规模的基于代理模型来研究冠状病毒的爆发传染病(COVID-19)在新加坡,考虑复杂的人机交互模式。特别是,多路网络的概念是用来区分社会交互作用发生在家庭和工作场所。此外,弱相互作用在人群中,瞬态相互作用在社交聚会,和密集的人类接触外国工人在宿舍也考虑在内。这种分类的多元社会网络连接一起Susceptible-Exposed-Infectious-Removed(西)流行病模型使一个更精确的控制措施的可行性和有效性的研究如社会距离,在家里工作,和封锁,在不同的时刻和阶段的大流行。使用这个模型,我们研究流行病爆发,在新加坡发生在人口稠密的居民区。我们的模拟表明,在人口稠密地区的居民很容易被感染,即使他们构成整个人口的很小的一部分。一旦感染开始在这些领域,疾病传播是不可控的,如果未采取适当的控制措施。
介绍
2019年冠状病毒疫情已成为流行。人类历史上第一次,我们观察一个全球共同努力,试图阻止疫情的传播与semi-closing国界和接地的国际航班。每个国家都有其独特的策略包含病毒在他们的领土。这个范围从完整的封锁在中国和在瑞典的群体免疫及渐进的干预方法1。而逮捕病毒最直接的方法是创建一个疫苗,疫苗研发的交货时间是长相对于疾病的毒性,最好的短期战略是社会排斥。
冠状病毒传播通过简单的人与人之间的联系机制。这就是为什么各国政府实施封锁和限制社会互动。理想情况下,如果我们能够隔离每一个人,就不会有病毒生存的空间。但这对家庭成员的社会是不可能的。此外,关键经济活动仍然需要继续为整个社会功能,这需要社会互动和工人提供基本服务。有两个实用的手段来防止病毒的传播通过这样一个社会的路线。一个是隔离感染者和他们接触2。然而,这需要所有感染者立即发现一旦他们成为传染性。但总是有延迟在这样的识别,最糟糕的是,有些感染者无症状。开展大规模的交换能力测试因此变得很重要,因为它不仅降低了延迟从发病到隔离,但还未被发现的传播者。第二种方法是社会距离的实现已经严重扰乱了许多国家的经济。
为了妥善管理的社会经济影响COVID-19大流行,政府需要一个清晰正确的政策进行合理化。有问题是否应该实施封锁,像瑞典的情况下与北欧邻国。如果锁定解除,我们应该逐步放松限制的顺序如何?一起解决这些问题的手段的间接警告政府一直由数学和计算模型。例如,一个基于微观族群间流动模型马尔可夫链的方法3被用来预测COVID-19病例数在每个市的西班牙。模拟的结果已经通知加泰罗尼亚政府提前任何西班牙地区是否超过其处理能力导致的快速实现干预措施,解决短缺。基于族群间的全球流行和流动模型也在另一个环境评估的有效性旅行限制的传播COVID-19在国家和国际水平4。这项工作的结果表明,旅行禁令主要延迟疾病的进展,与缓解最好通过传输减少干预。在另一个建模工作5,重新开放学校的影响作为退出策略的一部分,封锁了。发现逐步开放的学校是必要的不要压倒现有医疗系统或导致一个新的第二波疫情传播。也有一些研究调查在新加坡COVID-19的传播6,7。所有这些模型使用真实的数据来不断地调整自己的计算来驱动模拟场景接近现实,靠近地面真理。和他们的见解指导政府的政策和决策。事实上,流行病学分析的文学发展迅速在COVID-19流行病,回顾最相关的现有文献中可以找到参考。8。
模型
在本文中,我们使用Susceptible-Exposed-Infectious-Removed COVID-19流行病的传播建模(西)模型。与西珥的修改版本模型由几个研究小组目前模拟COVID-19蔓延9,10我们的方法利用多路复用11和时间网络12结合西珥模型。多路复用网络被用于参考。13学习如何在社会支持资源分配层影响病毒的传播在身体接触层。之前也有研究,结合爵士或SIS模型与多路复用网络调查免疫的影响14,动态病毒药物之间的相互作用15,出现的流行阶段16和传染病动力学17。最近的研究在西珥模型多路网络上已经探索到谣言的传播18,COVID-19的传播和不同层之间的交通网络19。
西珥的目的和目标多路网络模型来模拟不同形式的现实世界的社交互动,以检查各种干预策略的有效性对COVID-19的传播。社会交互调整数学模型的能力是至关重要的想办法遏制疫情蔓延的加速潮汐,除了给见解从封锁措施适当的退出策略大流行是进入减速阶段20.。我们的模型的主要应用程序将在新加坡大流行的评价情况。
西珥的模型
在西珥的模型中,个体感染分为四个阶段,即敏感,暴露,感染,删除。所有个人的人口被认为是容易受到病毒在大流行开始之前。模型开始当第一个传染性个人导入易感个体的人口。注意,这个进口个人从人口中随机抽取的。在这之后,米(t)个人选择在每个模拟随机均匀的一天t建模米(t)数量的输入性病例。作为我们研究的重点是在新加坡大流行,这些输入性病例的信息是来自新加坡卫生部网页21。
易感个体接触后感染个体,易感个体变得暴露的概率p。请注意,它需要\ (T_e \)天前平均暴露个人成为传染性。在这里,曝光时间被认为是gamma-distributed均值\ (T_e \)天。一旦个体的状态改为传染病,传播病毒的易感接触的概率p。注意,每个人可以成为不同的天数取决于感染时显示感染的症状和发病时间跨度从社会隔离。此外,否则无症状的感染状态个人认为停止只有当个人已经恢复。传染期因此认为是gamma-distributed均值\ (T_i \)天。一旦恢复,个体不再容易,再也不能成为传染性疾病。
社会互动
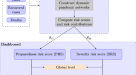
现实社会互动往往是太复杂是由理想的复杂网络模型,如Erdős-Renyi随机网络和无标度网络。在这里,我们建立一个多路网络11这是由多个重叠网络描述代理之间的各种社会关系研究流行病爆发的动力。具体地说,我们的多路网络由一个家庭网络,一个宿舍网络,一个工作网络,颞人群网络和时间网络社交聚会。注意,这个网络不是详尽的列表。原则上,任何社区社会交往方式明显不同,并不是在现有的社区模型中应该添加多路网络作为一个单独的层。例如,一个贫民窟网络可以包含在我们的模型的城市贫民窟附近。
现在让我们进入我们的社交网络的细节。我们有一个家庭网络在我们的模型中捕获一个家庭中家庭成员之间的社会交往。它代表了一个复杂网络社区结构。代理属于同一家庭(或社区)更紧密连接内部和其他代理在家庭网络。家庭的规模被认为是与平均泊松分布\ (S_h \)成员。另一方面,社会互动在员工宿舍由宿舍网络分别模仿宿舍容纳更多的居民相比,正常的家庭。此外,个人在宿舍拥有更多的社会关系与其他居民呆在同一个宿舍。注意,我们在员工宿舍的特殊利益源于毒性蔓延的发生在新加坡宿舍内的COVID-19集群。
我们模型之间的社会联系和工作场所的工作场所的网络。在新加坡,\ \ (40 \ %)人口的就业和工作在一个工作场所。每个工作都是模仿在工作场所作为一个社区网络。假设工作场所的大小,然而gamma-distributed包括工作场所的尺寸。请注意,为了简单起见,我们模仿社会互动在一样的学校,工作场所。
中的社会交往的公共空间,如公共交通系统和市场,非常不同于固定的家庭或工作场所。它涉及短期每天随机群体的个体之间的交互。在我们的模型中,我们选择\ (f_c \)组\ (N_c \)代理平均一致和随机模拟的形式\ (f_c \)全时间的网络。传播概率\ (p_c \)在每个这些人群的代理人被认为是小于的家庭或办公室网络。具体地说,它是\ (p_c = 0.1 p \)。此外,我们模型社交聚会,如宗教服务、学术会议和大型宴会事件以类似的方式虽然不同拓扑的社会互动。在每个模拟的一天,\ (f_g \)组平均大小\ (N_g \)代理形成均匀随机无标度拓扑的时序网络的平均度\ (k_g \)短暂的社会互动模式。我们假设病毒传播的概率p在这些网络社交聚会。
结合西珥模型和多路网络
数学上,组合模型可以表示为如下方程:
在哪里N是网络中的节点或个体的总数。在这里,\ \ (S_i (t)),\ \ (E_i (t)),\ \ (I_i (t))和\ \ (R_i (t))是个体的概率我敏感,暴露,感染和恢复时间t分别。暴露个人的速度成为传染性σ\ (\ \)当感染者的速度恢复用\γ(\ \)。一个是整个网络的邻接矩阵,它包含了社会互动在家庭,工作场所,和宿舍;\ \ (^ g (t))的邻接matirx颞网络社交聚会;和\ \ (^ c (t))的邻接matirx颞人群网络。
结果
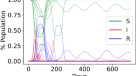
我们模拟的结果见图。1。仿真结果与CB显示好对应的真实数据的报告病例总数以及报告病例COVID-19的社区传播(即。情况下,排除感染在宿舍)。相比之下,一个西珥模型与社会接触模型由一个简单的Erdős-Renyi或无尺度随机网络不能充分捕捉COVID-19的传播动力学在新加坡(见补充材料)。我们还看了链接的数量情况。截至2020年5月13日,新加坡COVID-19报告了约570例与未知的感染源。在我们的模型中,分离的情况下源于感染在人群的传输网络以及患有轻微或没有症状。在模拟的最后时期,我们观察了314例感染病例从人群中网络。通过假设一个未被发现的个人能够传播病毒7天或更多,我们分类137例未检测到的模拟。注意,这种情况并没有发生在宿舍网络,因为政府一直积极筛查COVID-19感染在宿舍的工人由于CB。在我们的模拟,我们发现另一个平均290例感染由于这些未被发现的病例。 Assuming that some of these cases can be back-traced eventually through routine screening to asymptomatic individuals, our simulation would have uncovered 314 to 604 cases with unknown sources of infection.
我们的模型允许我们模拟的场景,如果政府没有实现断路器和没有修改外国工人的生活条件。在这种情况下,我们的结果显示一个指数的病例总数上升。注意,病例数将更加如果没有110年的最大容量,000宿舍工人固定在我们的模拟。这就解释了外观的饱和曲线没有CB案件的总数。因此,CB成功包含了远远超过4倍COVID-19的传播,并相应减少,预防医疗设备上的压力由于大流行。
图2说明了流行在新加坡的发展动态\ (R_e \)。我们观察到\ (R_e \)预测三波的出现增强COVID-19传输时\ (R_e \)变得比一个大。第一波发生在2020年2月14日根据无花果。2。它对应于感染集群在教会神的恩典大会首次报告病例2020年2月12日(这也是与报告病例从新加坡生活教会和任务)22。总共有33个感染者在这个集群。2020年2月22日开始第二波(见图。2)。它与另一种感染集群由于私人函数在莎拉裕廊首次报道于2020年2月27日。这个集群的感染者总数是48。这两个波COVID-19传播实际上是非常小,相对于第三波是2020年3月29日开始的基础上\ (R_e \)见图。2。第三波是一个非常大的波循环造成的COVID-19宿舍内的外国工人。虽然首次报道发表于2020年4月5日,它的存在可能已经被抢占的报告病例的感染在建筑工地莱佛士坊地区2020年4月3日。感染外国工人在宿舍的总数大概是23日,000年由当前计数和集群仍在增长。每个浪潮的开始之间的时间延迟和符合第一个报告案例观察之间的延迟COVID-19出现症状和诊断22。
没有CB,我们期望COVID-19的遗传性高,结果证实了在无花果。2。然而,\ (R_e \)应该继续上涨超出了2020年4月中旬如果没有强加给宿舍员工的最大容量模型,如前所述,流行曲线没有CB。图中紫色的线。1给出了在社区感染病例。没有实质性的感染最初在社区内。大规模感染发生后才在宿舍网络3月底。虽然感染蔓延速度很快在宿舍网络,但它需要一段时间的蔓延到社区通过相互作用的概率在工作场所或人群个体接触工人宿舍很小。社区内的病毒传播迅速,一旦达到临界数量急剧上升,这将导致病例所表示的紫色的线在无花果。1。然而当CB实施。这不会发生
COVID-19的发行量在新加坡的外国员工宿舍例证流行病爆发发生在人口稠密的居民区。外国工人只占\ (5.5 \ % \)整个人口在我们的模型中,我们假设那些居住在宿舍不连接到其他人群。在我们的模型中,选择输入性病例随机均匀,离开宿舍居民一个很小的机会是一个进口的情况。尽管如此,疫情暴发中观察到发生的宿舍在43个50的模拟,早些时候到达爆发的一些模拟相对于别人。这些结果让我们设想高传播性的影响在这样人口稠密的居民区更肆虐在低收入国家数以百万计的人生活在贫民窟。
我们使用了一个西多路网络模型来模拟在新加坡COVID-19疫情的发展。我们已经证明了我们的模型的效用评估断路器的功效在遏制病毒的传播。截至2020年6月1日与断路器,有不确定性的战略方法解除各种社会强加限制命令。我们设想empirically-fitted西多路网络模型可以模拟潜在战略的作用与不同层次的社会交互的局限性,目的是确定正确的数量的社会经济功能,可以重新启动在新加坡不会造成任何伤害COVID-19成功控制的努力已经取得了。
因此,我们探索的使用模型来模拟社会限制逐渐放松从2020年6月1日到2020年6月30日。在这里,我们假设没有在研究期间输入性病例。我们进一步假设一个完整的恢复inter-household社会关系而intra-household连接在CB维持不变。企业和工作场所的重新开放后在新加坡断路器发生在阶段。在这里,为简单起见,我们考虑\ (30 \ % \)不必要的工作场所内再次成为社会交往的工作场所的网络15 \ % \ \ ()工作场所的基本服务整个月保持现状。由于劳动力的返回他们的工作场所,我们增加人群频率\ \ (f_c = 600)。我们也会增加\ \ (f_g = 400),但在一个较小的平均组的大小\ (N_g = 25 \)。最后,我们假定社会连接在宿舍网络恢复\ \ (50 \ %)。注意,临时隔离设施如factory-converted宿舍曾家外国工人在CB时期,最大限度地减少社会接触。一些工人被允许回到他们的前提后,2020年6月23根据交换测试结果。我们因此恢复\ \ (50 \ %)的社会联系而不是25 \ % \ \ ()在CB之后。宿舍的房子通常12至16的工人在CB。数量减少到大约10后CB24。
我们的仿真结果基于这些参数(参见无花果。3和4)表明,逐步提升社会限制的策略将流行曲线变平,而激烈的社会互动的恢复时期2020年1月21日将导致另一个大型COVID-19传播的波。因此,我们的模型表明,谨慎的公共卫生政策,避免大规模的社会互动是典型的大流行控制的保持当前状态。2020年6月1日之前我们有模拟逐渐放松的人口规模\ \ (N = 1000000)并得到了类似的结果25。
此外,我们使用我们的模型研究的影响大规模流行病的聚集在两个不同的阶段,即当疫情爆发后达到高峰,慢了下来。具体地说,我们把4月21日和5月12日两个参考点和模拟流行病有或没有的存在大规模收集平均组的大小\ \ (N_g = 10000)在一个人口\ \ (N = 1000000)。一旦仿真达到参考点,我们考虑的场景(a)完整的社会关系在家庭,(b)\ \ (50 \ %)社会关系对工作场所的不必要的服务,(c)15 \ % \ \ ()连接工作场所的基本服务和(d)\ \ (50 \ %)宿舍的社会网络连接。我们设置了人群频率\ \ (f_c = 300)与\ (N_c = 50 \)。我们还设置\ (f_g \)1为每个模拟21天社会大规模的集会。然后我们比较新病例的积累增加自参考点(见图。5)。在无花果。5没有大规模收集参考点的5月12日,185例新病例中观察到社区的模拟。数量翻倍到378年在社区一级启用大型聚会时在我们的模型中。在人口级别4 586例新病例观察,数量增加到5,678年举行大规模集会日常(见图。5b)。得到了类似的结果当聚会举行超过4月21日爆发的高峰期(见图。5c, d)。我们看到在社区情况下增加从271年到541年,而新感染病例的总数增加从5,830 - 7,025年大规模的收集每天发生一段3周。

在新加坡流行曲线COVID-19传播的。真实数据的曲线所示,模拟动力学有或没有实现断路器(CB)的措施。的插图显示了一个传播的放大视图COVID-19新加坡的社区内。标准偏差的垂直线显示模拟动力学。注意,两个图中虚线竖线马克CB的开始。

动态演化的繁殖数量\ (R_e \)来自西多路复用模型,没有断路器(CB)的措施。注意,垂直虚线标志CB的开始。
讨论
往往一个模型需要适当增强捕捉更大的复杂性在真实世界的物理场景。我们的模型包含了社会交往的关键组件通过社会关系的多路复用的范例给一个精确的描述实际的传输COVID-19的场景。multiplex-network表示社会接触允许更大的灵活性的不同类型的社会互动的造型的模拟和评估社会排斥的流行病控制策略。此外,一个合适的分类的社会实体通过多路复用网络提供了一个正式的数学结构,非常适合流行的详细研究不同社会群体中传播。
但是要注意,该模型只适用于短期预测和规划为大流行还取决于许多无法预料的事件如输入性病例的突然增加或改变政府的政策。这样的变化对社会互动的具体影响尚不清楚。频繁的校准与更新数据因此需要捕捉社会交互模式的演化和动力学的大流行。

在新加坡流行曲线COVID-19传播的。真实数据的曲线所示,模拟动力学有或没有实现的逐步解除(GL)措施。的插图显示了一个传播的放大视图COVID-19新加坡的社区内。标准偏差的垂直线显示模拟动力学。

动态演化的繁殖数量\ (R_e \)来自西多路复用模型,没有逐步提升(GL)措施。注意,COVID-19传播的两个小波在2020年2月14日和2020年2月22日讨论的主要内容(见图。2)在这个情节略有变化由于大统计波动。

累计增加新的感染病例数量的自引用的一天。这两个参考天:5月12日(一个)和(b)爆发后已经放缓,4月21日(c)和(d当疫情已经达到了顶峰。每一次要情节中的两条曲线显示累计新病例增加日常大规模集会的存在与否(LG)的人口规模\ \ (N = 1000000)。(见一个)和(c)说明社区的新感染病例的增加,而次要情节(b)和(d)表示新感染病例的总数。
方法
繁殖数量
基本的繁殖数量\ (R_0 \)的数量,这是定义为继发感染引起的受感染的个体,是一个严密监控措施,揭示了当前状态的流行疫情。它告诉政府官员和流行病学家任务来抑制猪流感的大规模流行是否爆发迫在眉睫。如果上面的复制号码是1,传染性病例增加,预计疫情的发生。另一方面,如果\ (R_0 \)低于1,感染病例数减少和流行是适度的。\ (R_0 \)动态变化的病毒传播的不同部分的人口后果社会个人和社区之间的交互。的干预措施,诸如旅行禁令和社会距离产生了积极的效果,降低的价值\ (R_0 \)。事实上,繁殖数量被发现从2.35下降到1.05在武汉被锁定在一月底26。
两种常见的方法来估计繁殖数量是最大似然估计值和分支过程估计量27。在这里,我们采用分支过程估计量来评估有效的繁殖数量\ (R_e \),而不是\ (R_0 \)由于人口爆发后开始成为部分敏感。首先,我们小组日常的新病例数量的时间序列\ (n = \ {n_0, n_1、甲烷、\ cdots n_T \} \)的长度\ (T + 1 \)成米一代又一代,每一代的\ (T_e \)数据点的数量。然后形成一组:
注意,平均暴露时间\ (T_e \)给的时间连续几代人感染或串行之间间隔。我们关心的是一个不断发展的\ (R_e \),我们估计\ (R_e \)对每一代我为:
新病例报告和包含在流行病数据库后阳性感染者。然而没有简单或直接报告病例的数量之间的关系和实际的新感染病例的数量。在裁判。28线性回归模型被用来嫁祸于失踪的感染发病日期考虑报告延迟分布。在这里,我们与西珥演绎发病日期模式。具体来说,我们模拟\ (M = 50 \)实现大流行与我们西珥模型和选择20 \ % \ \ ()最佳流行曲线在研究。然后推导出新的感染病例的数量从这些实现。
西珥模型与多路网络
在我们的模拟中,我们使用一个有效的人口规模\ \ (N = 2000000)而不是实际的新加坡的人口规模的560万年的2020人。这种假设是合理的,因为感染病例\ \(和_ {t = 0} ^ t n_t \)比实际的人口规模相对较小。因此,它是可行的假设的一大部分人口有消失的机会接触任何传染性个人在研究期间。这个假设已经减少仿真时间的优势。
同样,我们认为,110年,000名外国工人呆在宿舍,而不是323年的实际数量,00030.。宿舍在新加坡的不同大小,最大的网站的房子至少有000人30.。为简单起见,我们假定每个宿舍容纳000个人在我们的模型中。因此,我们的宿舍网络由110个社区。通常在宿舍每层楼房子120至180名工人23,29日。校准后(详见补充材料),我们宿舍网络的平均度\ (k_d = 60.15 \)。大多数的网络连接是在社区内的宿舍,宿舍与每个连接到约0.15其他个人的宿舍。
其余的人口规模890人,000人认为留在家庭的平均大小\ (S_h = 2.5 \)。样本家庭的大小是随机来自一个泊松分布的均值\ \λ= 2.5 (\)。在同一个家庭成员社会连接的概率为0.95。此外,我们假设平均每个家庭网络是社会交往中的0.4其他个人在另一个家庭。
接下来,我们模型中从事经济活动的人在家庭网络连接45 \ % \ \ ()在工作场所的网络。请注意,这些人包括学生在学校“工作”。同时,\ \ (90 \ %)包括个人在宿舍网络的工作场所的网络。此外,工人在宿舍有更高的机会在同一工作场所工作。工作场所的网络被认为是模块化平均社区的大小\ (S_w = 4 \)。工作场所的大小是随机来自伽马分布2的形状参数和尺度参数为2。成员在同一工作场所是社会连接的概率为0.7,而不同的社会联系工人工作场所设置为0.08。此外,我们引入了少量的网际网路household-to-workplace链接连接非工作家庭个人与工作场所的人。类似household-to-dormitory网际网路也插在我们的多路复用网络模型的链接。
在我们的时间人群网络的情况下,我们设置\ \ (f_c = 1000)和\ (N_c = 50 \)为每个模拟。时间社交聚会网络的参数是:\ \ (f_g = 400),\ (N_g = 50 \)和\ (k_g = 8 \)。
我们模拟始于2020年1月21日的场景,前两天在新加坡COVID-19首次报道,和2020年5月13日结束。新加坡实现断路器(CB) 2020年4月7日限制居民之间的社会互动。CB后,我们集\ (f_g = 0 \)和\ \ (f_c = 400)。我们关掉社会关系\ \ (85 \ %)的工作场所,剩下的15 \ % \ \ ()继续与必要的工人在工作中身体功能。我们也关闭工作场所之间的社会关系。另一方面,在家庭社会关系保持不变,尽管我们关掉\ \ (95 \ %)家庭之间的社会关系,同时保持\ (5 \ % \)inter-household连接代表违反”措施。模型新加坡政府努力在改进外国工人的生活条件,我们减少砍伐对宿舍内的社会关系25 \ % \ \ ()直到有连接的每一个5天25 \ % \ \ ()的连接了。最后,我们组p到0.131日和\ (T_e \)4。\ (T_i \)将从2020年1月21日30天3第一反映的时间延迟疾病发病病例报告在早期阶段的大流行。它是调整值为2。参数的值是明智而审慎地从文学或从真实数据校准。
校准
比较的结果与数据模拟,我们计算的平均绝对误差\ (e_ {l1} \)这是定义如下:
在哪里\ (N_{总}^ M (t) \)累积感染病例数在时间吗t从模型模拟\ (N_{总}^ D (t) \)累积感染病例数在时间吗t给出的数据。换句话说,我们研究一阶的均值误差在时间跨度T。
引用
Claeson, m &汉森COVID-19和瑞典的谜。《柳叶刀》397年,259 - 261 (2021)。
Hellewell, J。et al。控制的可行性COVID-19孤立的病例和暴发的联系人。柳叶刀水珠。健康8,488 - 496 (2020)。
领域,。科,W。,&Gómez-Gardeñes, J.,et al。一个COVID19时空流行病传播的数学模型。MedRxiv2020.03.21.20040022 (2020)。
Chinazzi, M。et al。旅行限制的影响2019年的小说《冠状病毒的传播(COVID-19)爆发。科学368年395 (2020)。
多梅尼科,l D。Pullano, G。,Sabbatini, C. E., Boëlle, P. Y. & Colizza, V. Expected impact of reopening schools after lockdown on COVID-19 epidemic in l̂le-de-France.MedRxiv2020.05.08.20095521 (2020)。
罗,j . COVID-19预测建模。2020年白皮书。https://ddi.sutd.edu.sg/(2020年5月20日通过)。
箱型雪撬,R。et al。调查的三个集群在新加坡COVID-19:影响监测和应对措施。《柳叶刀》395年1039 - 46 (2020)。
埃斯特拉达,大肠COVID-19 SARS-CoV-2。建模,看未来。理论物理。代表。869年1-51 (2020)。
李,m . L。,Bouardi, H. T., Lami, O. S., Trikalinos, T. A., Trichakis, N. K. & Bertsimas, D. Forecasting COVID-19 and analyzing the effect of government interventions.MedRxiv2020.06.23.20138693 (2020)。
统计机器学习实验室的加州大学洛杉矶,COVID-19信息网站。https://www.covid19.uclaml.org/(2020年5月20日通过)。
Kivela, M。et al。多层网络。Netw j .复杂。2,203 - 271 (2014)。
河中沙洲,p . & Saramaki j .时序网络。理论物理。代表。519年,97 - 125 (2012)。
陈,X。et al。抑制传染病传播与人际互助多路网络。新的期刊。20.013007 (2018)。
吴,Q。,Lou, Y. & Zhu, W. Epidemic outbreak for an SIS model in multiplex networks with immunization.数学。Biosci。277年38岁(2016)。
玛索,V。诺埃尔,P。,Hébert-Dufresne, L., Allard, A. & Dubé, L. J. Modeling the dynamical interaction between epidemics on overlay networks.理论物理。启E84年026105 (2011)。
Dickison, M。,Havlin, S. & Stanley, H. E. Epidemics on interconnected networks.理论物理。启E85年066109 (2012)。
刘问:H。,Xiong, X., Zhang, Q. & Perra, N. Epidemic spreading on time-varying multiplex networks.理论物理。启E98年062303 (2018)。
Di, L。,Gu, Y., Qian, G. & Yuan, G. X. A dynamic epidemic model for rumor spread in multiplex network with numerical analysis.v1 ArXiv: 2003.00144(2020)。
李,t .模拟流行病的传播在中国多层次交通网络:在武汉以外的冠状病毒。v1 ArXiv: 2002.12280(2020)。
Kupferschmidt, k .锁定工作:但接下来会发生什么呢?。科学368年218 (2020)。
新加坡卫生部。https://www.moh.gov.sg/covid-19。
塔里克,。et al。实时监控的传输协议COVID-19在新加坡,2020年3月。BMC地中海。18166 (2020)。
Meah:清洁但仍然拥挤,说恢复外国工人回到宿舍“传染”。今天2020年6月13日。https://www.todayonline.com/singapore/cleaner-still-overcrowded-say-recovered-foreign-workers-returning-virus-free-dorms(2020年8月3日通过)。
Nadarajan, r .新宿舍好标准的建立为100000外国工人在未来几年:劳伦斯黄。今天2020年6月1日。https://www.todayonline.com/singapore/new -宿舍-好-标准- - - - - - -建造- 100000外国工人——-年-劳伦斯-黄(2020年8月3日通过)。
钟:n和咀嚼,l . y .造型新加坡covid-19流行西多路复用网络模型。MedRxiv2020.05.31.20118372 (2020)。
Kucharski, a·J。et al。早期传播动力学和控制COVID-19:数学建模研究。柳叶刀感染。说。20.,553 - 558 (2020)。
白色,l . f . & Pagano m .基于可能性方法实时估计连续间隔和生殖的一种流行病。统计,地中海。27,2999 - 3016 (2008)。
白色,l F。et al。估计的生育数量和早期阶段的串行间隔2009年甲型H1N1流感大流行在美国。流感和。病毒3,267 - 276 (2009)。
Lim j .冠状病毒:工人描述拥挤,拥挤的生活条件在宿舍公告的隔离区域。《海峡时报》2020年4月6日。https://www.straitstimes.com/singapore/manpower/workers-describe-crowded-cramped-living-conditions(2021年2月4日)访问。
Ng, k . g .宿舍coronavirus-free居民的80%以上,95宿舍的Covid-19:妈妈。《海峡时报》2020年7月30日。https://www.straitstimes.com/singapore/over - 80 -宿舍-居民-冠状病毒-免费- 95 -更多-宿舍-清除- - covid - 19 -妈妈。
方,Y。,N我e, Y. & Penny, M. Transmission dynamics of the COVID-19 outbreak and effectiveness of government interventions: A data-driven analysis.j .地中海性研究。92年645 (2020)。
作者信息
作者和联系
贡献
L.Y.C. N.N.C.设计项目,进行了分析和写论文。N.N.C.写程序代码和执行模拟。
相应的作者
道德声明
相互竞争的利益
作者宣称没有利益冲突。
额外的信息
出版商的注意
施普林格自然保持中立在发表关于司法主权地图和所属机构。
补充信息
权利和权限
开放获取本文是基于知识共享署名4.0国际许可,允许使用、共享、适应、分布和繁殖在任何媒介或格式,只要你给予适当的信贷原始作者(年代)和来源,提供一个链接到创作共用许可证,并指出如果变化。本文中的图片或其他第三方材料都包含在本文的创作共用许可证,除非另有说明在一个信用额度的材料。如果材料不包括在本文的创作共用许可证和用途是不允许按法定规定或超过允许的使用,您将需要获得直接从版权所有者的许可。查看本许可证的副本,访问http://creativecommons.org/licenses/by/4.0/。
关于这篇文章

引用这篇文章
钟,N.N.,Chew, L.Y. Modelling Singapore COVID-19 pandemic with a SEIR multiplex network model.Sci代表1110122 (2021)。https://doi.org/10.1038/s41598 - 021 - 89515 - 7
收到了:
接受:
发表:
DOI:https://doi.org/10.1038/s41598 - 021 - 89515 - 7
本文引用的
混合室模型的案例研究COVID-19在英国和以色列
数学在行业杂志》上(2023)
一种新颖的混合SEIQR模型将检疫和锁定COVID-19规定的影响
科学报告(2021)
